《兰亭集势》专题
-
2.3.4 JVM中垃圾收集算法及垃圾收集器详解
一、垃圾收集算法 1.标记-清除算法 最基础的收集算法是“标记-清除”(Mark-Sweep)算法,如同它的名字一样,算法分为“标记”和“清除”两个阶段。 ①首先标记出所有需要回收的对象 ②在标记完成后统一回收所有被标记的对象。 不足: 效率问题:标记和清除两个过程的效率都不高 空间问题:标记清除之后产生大量不连续的内存碎片,空间碎片太多可能会导致以后程序运行过程中需要分配较大对象时,无法找到足够
-
如何合并具有交集的集合(连通分量算法)?
问题内容: 有没有有效的方法来合并具有交集的集合。例如: 预期结果是: 所有具有交集(公共分量)的集合都应合并。例如: 因此,这两个集合应该合并: 不幸的是我没有任何有效的解决方案。 更新:结果集的顺序并不重要。 问题答案: @ mkrieger1在注释中提到的一种实现连接组件算法的有效方法是将集合列表转换为一组可散列的冻结集,以便在迭代时找到与当前集合相交的冻结集。从池中删除它: 鉴于,将变为:
-
流收集并根据独立谓词收集成多个结果
问题内容: 我盯着一些命令性代码,试图将其转换为纯函数式样式。基本上有一个迭代的for循环,在该循环中,我检查3个谓词,并根据匹配的谓词填充3个谓词。输出集可以重叠。如何使用Java 8 Streams / map / filter /等以纯功能方式实现此目的? 问题答案: 最简单的解决方案(除了将所有内容保留为更容易之外)是创建三个单独的流: 如果有谓词列表,则可以创建相应的集合列表: 在此,结
-
在Java中验证空集合和空集合的最佳实践
问题内容: 我想验证集合是否为空和。任何人都可以让我知道最佳做法。 目前,我正在检查以下内容: 问题答案: 如果在项目中使用Apache Commons Collections 库,则可以使用和方法分别检查集合或映射是否为 空 或为 空 (即它们是“空安全的”)。 这些方法背后的代码或多或少是用户@icza在其答案中所写的内容。 无论您做什么,都请记住,随着代码复杂度的降低,编写的代码越少,测试的
-
设计:Spring集成:集群环境中的Jdbc入站适配器
我们在Oracle Weblogic 10.3.6服务器中有两个节点的集群环境,它是循环的。 我有一个服务,它从外部系统获取消息并将它们放入数据库(Oracle DB)。 我正在使用jdbc入站适配器转换这些消息并将其传递到通道。一条消息只处理一次。我计划在DB表中有一列(NODE\u NAME)。当从外部系统获取消息的第一个服务也使用NODE_名称(weblogic.NAME)更新列时。在jdb
-
Spring JpaRepository查找方式。。。In(Collection)返回并集而不是交集
我的JpaRepository中有一个查询方法 通过实例变量
-
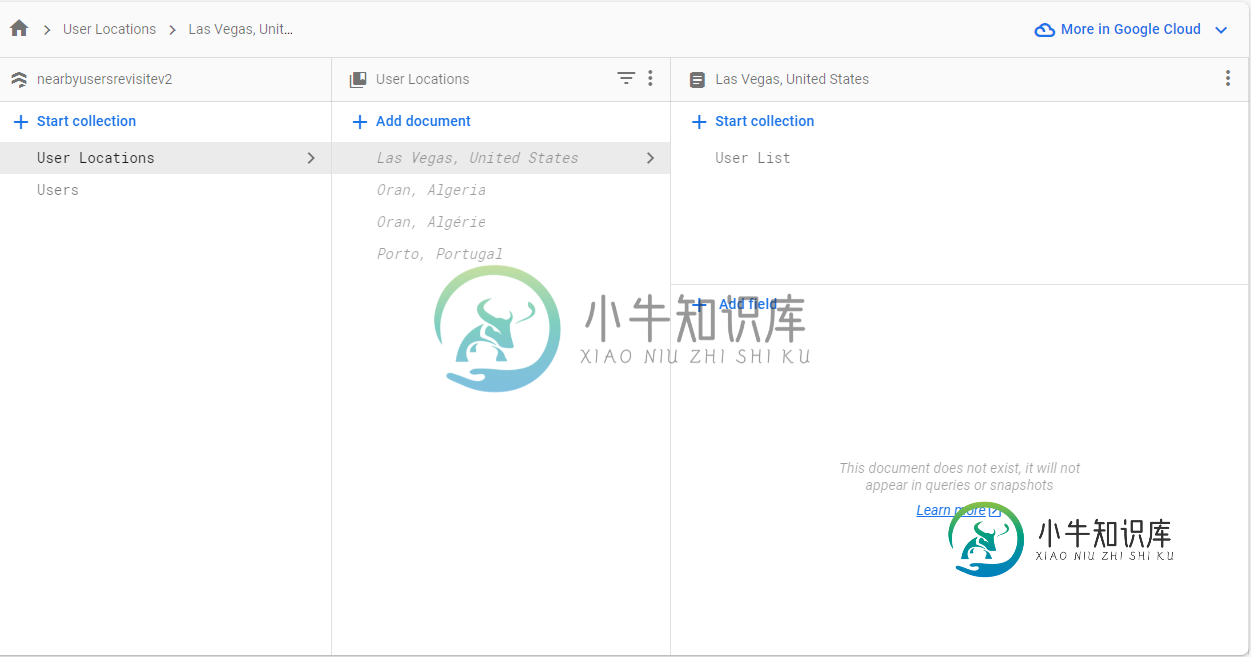 Firestore从根集合中获取所有文档(包含子集合)
Firestore从根集合中获取所有文档(包含子集合)我正在使用Java开发一个Android应用程序,我使用firestore数据库,我有一个名为用户位置的集合,其结构类似于照片: 分贝 我的问题是,当一个用户改变他的位置或一个新用户进入一个已经存在的位置(其他用户有相同的位置)时,它会创建一个新文档(如在“oran, algerie”中)。当我添加新用户并更新文档时,我想使用,但问题是我无法以正常方式检索根集合的所有文档: 它返回null。我尝试
-
cassandra -保存的集群名称测试集群!=配置的名称
当我收到这个错误时,我应该如何bot一个新的Cassandra节点? cassandra.yaml文件中集群的名称是: 我如何解决?
-
使用SAP云平台集成(SCPI)将Hybris集成到SAP零售
我正在尝试使用SAP云平台集成(SCPI)将SAP Hybris(1811)集成到SAP for Retail(ISR)。有什么好线索吗? 问候,Wajih
-
如果Zookeeper集群中的节点死亡,Kafka集群不可用
这就是我如何开始我的3个Kafka节点: 动物园管理员和Kafka集群在独立测试时表现良好。 我的意思是,我可以连接到一个Zookeeper节点(比如zoo1),并创建一个zNode。我可以在之后停止节点(例如,docker停止zoo1),并且我仍然可以从Zookeeper集群中的任何其他节点查询znode。 我将收到一个未知的HostException: 但是,我确实需要Kafka集群能够充分发
-
无法访问Redis(启用群集模式)群集的终结点
我有1个VPC——在1个EC2实例(amazon ami)和1个Redis(支持群集模式)下,使用Auth(密码)和对所有IP:端口开放的安全组(仅用于测试)——设置非常简单。 telnet在我的EC2实例(配置endpoint)的6379端口工作 无法使用Redis CLI连接到Redis服务器-无论是配置endpoint还是节点endpoint都无关紧要;使用v.5.0.4版本的Redis C
-
一个集装箱从另一个集装箱的进入端口
BigGDB的Dockerfile: 有人能告诉我,我需要在docker-compose.yml或命令中做哪些更改,以使java容器访问biggdb(postgres)容器的端口吗?
-
无法强制转换java。util。集合$EmptySet到java。util。哈希集
我使用的是Vaadin14和Java1.8。我想实现一个多选组合框,这就是我使用以下Vaadin插件的原因:https://vaadin.com/directory/component/multiselect-combo-box/api/org/vaadin/gatanaso/MultiselectComboBox.html 实例化和使用combobox效果很好,但是我得到了一个错误 尝试“保存”
-
采集帮助 - 了解采集 - 常用过滤规则 - HTML过滤
HTML过滤: {dede:trim}<object([^>]*)>([^>]*)</object>{/dede:trim} {dede:trim}<object([^>]*)>{/dede:trim} {dede:trim}</object>{/dede:trim} {dede:trim}<OBJECT([^>]*)>([^>]*)</OBJECT>{/dede:trim} {dede:trim
-
数据库的字符集、表的字符集和列的字符集之间的关系?不同的字符集是否会导致性能问题?
我正在用ASP开发一个网站。net和我的数据库是MYSQL。在那里,用户可以提交文章。这个网站是国际性的,所以我不想把语言限制为英语。 所以我决定做几件事。如果我做了错误的选择,请指导我。 1) 我选择utf8mb4作为数据库字符集。因为它是UTF8的改进版本,用于存储更多字符。我的选择正确吗?我的意思是,我只有几个需要使用utf8mb4的表。那么我应该使用Latin1作为数据库字符集吗? 2)