《兴业数金》专题
-
 23秋招 阿里 商业智能 数据分析 过经挂经?
23秋招 阿里 商业智能 数据分析 过经挂经?9.28晚上十点电话没接到-9.29下午四点电话没接到-9.29晚上十点半约9.30面试 电话面 35min 自我介绍 讲了两个实习项目均没有深入提问 机器学习 -讲两个无监督 两个有监督学习算法 -讲的算法优缺点都是什么 -过拟合怎么处理 -知道决策树ID3吗 讲一下信息增益的公式 数据分析使用什么工具 sql:每个商家近三个月最大的三笔订单 python:给你一个数列怎么转换成数组 用哪个库的
-
 电商业务数据指标体系面试题与解析2
电商业务数据指标体系面试题与解析2面试高频题5: 题目:怎么衡量你在业务部门的贡献 业务部门是数据分析师分析所服务的相关方,包括产品、运营等 答案解析: 能否驱动业务提供方向和结论,并有明显业务效益的提升 能否理解业务并提供专业的意见,从而解决了业务方的一些难题 能否对业务充分理解,并能高效做出取数和数据报表等操作,提升业务方效率 拿日常工作详细举例: 比起零散的跑数据,提供有效的数据报表更有效一些 能有一些数据可视化的展示,比纯
-
部署 Seafile 专业版服务器 - 使用 Oracle 数据库部署
安装依赖库 数据库配置 下载与安装 启动 Seafile 服务器 安装依赖库" class="reference-link">安装依赖库 Ubuntu 14.04,可用以下命令安装全部依赖。 sudo apt-get install openjdk-7-jre poppler-utils libpython2.7 python-pip mysql-server python-setuptools
-
 2023暑期实习-大数据开发面试-字节商业化
2023暑期实习-大数据开发面试-字节商业化1、 目前研究的项目,对数据的处理? 2、 你怎么理解数据挖掘? 3、 平时用啥数据库? 4、 3NF? 5、 深剖数仓项目 6、 讲一讲项目? 7、 数仓表哪里用到了3NF? 8、 是2NF吗? 9、 数仓模型? 10、 事实表和维度表都有啥? 11、 下单业务中怎么记录下单了但未支付的行为? 12、 拉链表用过吗? 13、 留存率怎么实现的? 14、 连续的还是间隔的? 15、 今天算出来的留
-
 长城汽车-产业数智化中心-产品运营一面
长城汽车-产业数智化中心-产品运营一面技术面 1.自我介绍 2.对产品运营的理解 3.学习了SQL的哪些方面 4. left join 和 join的区别 5. 关于课题的内容 6. 有没有使用SQL或者Tableau进行数据分析的经历 7.反问 #长城汽车#
-
 我爱我家数据运营二面业务面面经整理
我爱我家数据运营二面业务面面经整理1、经数据分析,发现某高业绩业务员最近业绩为0,怎么分析原因。 我的回答: (1)、查看历史数据,是否为周期性波动。若否,查看外部环境、如房地产业务不佳,环境周期不佳。 (2)、和对接端口确认数据源是否来源有误、确认我的分析过程是否有误。 面试官补充:基本正确。 (1)先去检核自己的数、检验无误后找人员调研、查看该人员是否有工作心态上态度上的问题,如他想要离职等现象。 2、一面面试官看出我比较想要
-
 小红书商业化技术二面-大数据方向-社招
小红书商业化技术二面-大数据方向-社招部门主管来面 1. 开场自我介绍 2. 问了其中做过的一个项目,大约十几分钟 3. 一条Hive SQL具体的执行流程 4. 优化逻辑执行计划具体做了哪些事情 5. 有哪些类型的OperatorTree 6. Map Join和Reduce Join 7. Spark Join的三种方式 8. Hive SQL最后转换成Task提交给计算引擎是先生成MapReduceTask再转换成SparkTa
-
如何使管道作业等待所有触发的并行作业?
问题内容: 我将Groovy脚本作为Jenkins中Pipeline工作的一部分,如下所示: 由于将标记设置为,因此它并行执行多个其他自由式作业。但是,我希望所有作业完成后才能完成呼叫者作业。目前,Pipeline作业会触发所有作业并在几秒钟后自行完成,这不是我想要的,因为我无法跟踪总时间,而且我无法一次取消所有已触发的作业。 当并行完成所有作业时,如何纠正上述脚本以完成管道作业? 我试图将构建作
-
在上游作业中显示下游作业的控制台输出
问题内容: 我正在使用詹金斯。 詹金斯(Jenkins)有上游工作:A 詹金斯(Jenkins)有下游工作:B A的控制台日志输出为: B的控制台日志输出为: 我想要得到的是: 有什么办法,我可以在作业A的控制台日志中获取作业B的控制台输出,然后确定作业“ A”是否成功(使用日志解析/ grep表示故障/错误等关键字)。 问题答案: 不确定您要达到的目标,但是看起来有些人为。查看以下方法是否满足您
-
无法为作业rke-network-plugin-deploy-job获取作业完成状态
我在有以下规格的空气间隙环境中清除了rke: 节点: 主机类型/提供程序:VirtualBox(测试环境) cluster.yml文件: 复制的步骤: docker网络 问题是否与网络接口有关?如果是:我如何创建它?
-
将作业配置导入通用作业配置类(注释配置)
我正在重构一个传统的基于Spring Batch XML的应用程序,以使用注释配置。我想了解如何将以下XML文件转换为基于注释的配置,并保持相同的关注分离。 为了便于讨论,这里有一个简单的例子。 job-config-1.xml job-config-2.xml job-config-3。xml 我想从XML配置转移到Java配置。我想为每个XML创建3个作业配置类。比如说JobConfig1。j
-
Jenkins管道作业将构建状态转发到自由式作业
我目前正在使用全局构建统计插件,显示我们的工作状态在一个良好的格式图表。
-
一个作业更新另一个作业输出的最佳方法
下面是我的场景。我的工作是处理大量的csv数据,并使用Avro将其写入按日期划分的文件中。我得到了一个小文件,我想用它来更新这些文件中的一些附加条目,第二个作业我可以在需要时运行,而不是再次重新处理整个数据集。 这个想法是这样的: job1:处理大量的csv数据,将其写入压缩的Avro文件中,并按输入日期拆分为文件。源数据不按日期划分,因此此作业将做到这一点。 job2(在Job1运行之间根据需要
-
如何在azkaban 3.0中从作业文件中获取作业名称
当试图安排作业时,我们需要来自Azkaban的作业名称。有什么内置属性吗?我们从获取流名称。 我的工作文件是:
-
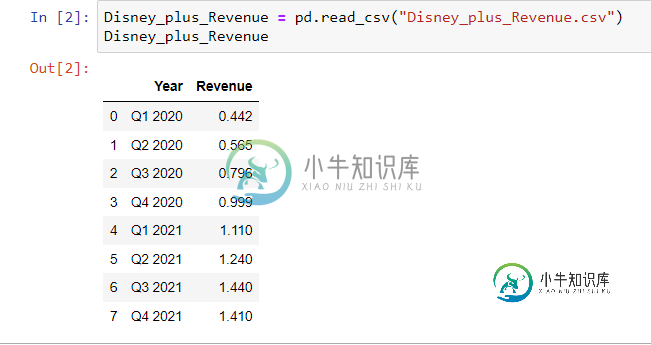 使用 Pandas 将季度业绩转换为年度业绩的建议
使用 Pandas 将季度业绩转换为年度业绩的建议因此,我有2020年第一季度至2021第四季度迪士尼加收入的季度数据。 错误-