《万集科技》专题
-
编写超过5000万从Pyspark df到PostgresSQL,最有效的方法
从Spark数据框到Postgres表格插入数百万条记录的最有效方法是什么?我在过去通过使用批量复制和批量大小选项也成功地从火花到MSSQL做到了这一点。 有没有类似的东西可以在这里为博士后? 添加我尝试过的代码以及运行流程所需的时间: 所以我做了上面的方法,1000万记录,并有5个并行连接,如中指定的,还尝试了200k的批量大小。 整个过程的总时间为0:14:05.760926(14分5秒)。
-
如何用apache spark处理数百万个较小的s3文件
注意:计数是对处理文件需要多长时间的更多调试。这项工作几乎花了一整天的时间,超过10个实例,但仍然失败,错误发布在列表的底部。然后我找到了这个链接,它基本上说这不是最佳的:https://forums.databricks.com/questions/480/how-do-i-ingest-a-large-number-of-files-from-s3-my.html 然后,我决定尝试另一个我目前
-
 申万宏源产品经理国际业务部面试复盘
申万宏源产品经理国际业务部面试复盘一面 群面 一小时 三个候选人 三个面试官 ——基础问题 第一部分 个人英文自我介绍 一分钟 第二部分 自我评价(优缺点)及理想工作状态 第三部分 你了解到的产品经理完整的工作流程,详细说一下 ——业务问题 第一部分 如何理解国际业务 第二部分 如何理解前台如销售岗位与中台如产品设计岗位 第三部分 中台部门如何与前台部门合作推广一个产品 第四部分 所在实习券商公司有什么比较优势和不足 第五部分
-
用三千万影视剧字幕语料库生成词向量
对语料库切词 因为word2vec的输入需要是切好词的文本文件,但我们的影视剧字幕语料库是回车换行分隔的完整句子,所以我们先对其做切词,有关中文切词的方法请见《教你成为全栈工程师(Full Stack Developer) 三十四-基于python的高效中文文本切词》,为了对影视剧字幕语料库切词,我们来创建word_segment.py文件,内容如下: # coding:utf-8 import
-
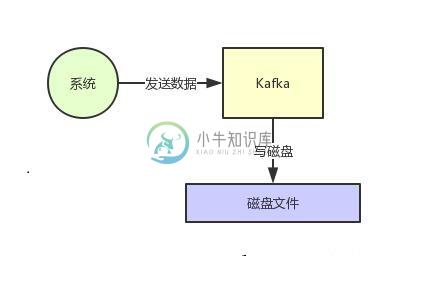 RocketMQ每秒要写入几十万并发,是怎么实现的?
RocketMQ每秒要写入几十万并发,是怎么实现的?主要内容:1、页缓存技术 + 磁盘顺序写,2、零拷贝技术,3、最后的总结这篇文章来聊一下Kafka的一些架构设计原理,这也是互联网公司面试时非常高频的技术考点。 Kafka是高吞吐低延迟的高并发、高性能的消息中间件,在大数据领域有极为广泛的运用。配置良好的Kafka集群甚至可以做到每秒几十万、上百万的超高并发写入。 那么Kafka到底是如何做到这么高的吞吐量和性能的呢?这篇文章我们来一点一点说一下。 1、页缓存技术 + 磁盘顺序写 首先Kafka每次接收到数据都会往磁
-
 mysql sum多个字段千万级数据如何查询优化?
mysql sum多个字段千万级数据如何查询优化?统计数据表中多个sum千万级数据超时。由于业务需要实时 所以做不来快照表 我加了索引似乎也不管用 后来为了不联表 我直接把快照写入进去了
-
收集配置和技术
这个 relationship() 函数定义两个类之间的链接。当链接定义了一对多或多对多关系时,当加载和操作对象时,它被表示为一个Python集合。本节介绍有关收集配置和技术的其他信息。 处理大型集合 的默认行为 relationship() 是将完全加载项集合中,根据加载策略的关系。另外, Session 默认情况下,只知道如何删除会话中实际存在的对象。当父实例标记为删除并刷新时, Sessio
-
python 划分数据集为训练集和测试集的方法
本文向大家介绍python 划分数据集为训练集和测试集的方法,包括了python 划分数据集为训练集和测试集的方法的使用技巧和注意事项,需要的朋友参考一下 sklearn的cross_validation包中含有将数据集按照一定的比例,随机划分为训练集和测试集的函数train_test_split 得到的x_train,y_train(x_test,y_test)的index对应的是x,y中被抽取
-
如何在收集列表、收集集合或组集合后修复配置单元错误?
假设我的配置单元表包含以下值: 我正在使用。我在collect_list/collect_set或group_concat查询后出现此错误。 错误:org。阿帕奇。蜂箱服务cli。HiveSQLException:处理语句时出错:失败:执行错误,从组织返回代码2。阿帕奇。hadoop。蜂箱ql.exec。org的MapRedTask先生。阿帕奇。蜂箱服务cli。活动活动toSQLException
-
无法为任务“…”设置只读属性“ClassDirectory”的值类型为org。格拉德尔。测试。杰科科。任务。雅科克报告
我刚刚用新版本的Gradle将我的Android Studio更新为4.0,现在我的构建出现了一个错误。
-
帕拉米科和伪tty分配
问题内容: 我正在尝试使用Paramiko连接到远程主机并执行许多文本文件替换。 其中一些命令需要作为sudo运行,从而导致: sudo:对不起,您必须有一个tty才能运行sudo 我可以使用-t开关和ssh强制进行伪tty分配。 使用paramiko可以做同样的事情吗? 问题答案: 我认为您想要对象的方法(我想提供一个URL,但是lag.net上的paramiko文档非常繁琐,只是不会为我显示文
-
科尔多瓦:“Android SDK:未安装”
我知道有很多这样的线程,但没有一个有帮助。 我使用的是Windows 10,Cordova 7.1.0(最新版本),我已经安装了带有SDK平台7.1.1-API级别25的Android Studio(也尝试降级到7.0-API级别24)。此外,我使用Android Studio SDK管理器安装了SDK构建工具。 正在运行: 我收到以下消息: Android SDK设置不正确。确保Android
-
 同程数科-社招-Java一面
同程数科-社招-Java一面2023.02.09晚 整体就是有点懵,原本以为一面是基础面,没想到上来直接问项目框架业务,对着简历项目一个业务一个业务在问,答得不是很好。结巴 + 口吃,听录音回放有很多地方要改进下,感觉后来都有点急了。 🔥1. 项目、基础 自我介绍:简单自我介绍 重点:按着项目依次问了框架、业务亮点,难点,和自己负责的点(真的要对自己框架、业务亮点超级了解呀,不然答得结结巴巴的) 慢查询怎么排查的?:结
-
 中电28电科莱斯面经
中电28电科莱斯面经Set和Map的区别 块元素和行内元素 水平垂直居中 防抖和节流 判断数据类型的方法 Promise #23届提前批##中国电科#
-
 【人品开攒】科大 C++ 一面
【人品开攒】科大 C++ 一面时间线:8.31hr面 9.15技术一面(30min左右) 1、八股 C++浮点数的存储格式 const关键字 红黑树的概念 红黑树插入节点 C++面向对象理解 封装 继承 多态 了解的排序算法,具体说哪一种 然后项目的一些问题,不是很深入,也和项目本身菜有关 问一问对科大的理解 无手撕 面试体验还好,面试官人很和蔼,全程笑着说话。许愿技术二面~ #科大讯飞#