《哈啰出行》专题
-
3. 哈希表
3. 哈希表 下图示意了哈希表(Hash Table)这种数据结构。 图 26.12. 哈希表 如上图所示,首先分配一个指针数组,数组的每个元素是一个链表的头指针,每个链表称为一个槽(Slot)。哪个数据应该放入哪个槽中由哈希函数决定,在这个例子中我们简单地选取哈希函数h(x) = x % 11,这样任意数据x都可以映射成0~10之间的一个数,就是槽的编号,将数据放入某个槽的操作就是链表的插入操作
-
hashlib — 哈希库
用途: 密码散列和消息摘要 散列算法 md5 sha1 sha224 sha256 sha384 sha384 sha512 import hashlib print('Guaranteed:\n{}\n'.format( ', '.join(sorted(hashlib.algorithms_guaranteed)))) print('Available:\n{}'.format(
-
哈多普映射器输出到HBase表和减速器
我正在尝试编写一个MapReduce作业,该作业可以解析CSV文件,将数据存储在HBase中并一次性执行简化函数。理想情况下,我想要 映射器输出良好记录到 HBase 表良好 映射器将坏记录输出到 HBase 表坏 映射器使用键将所有好的数据发送到化简器 还希望更新第三个表,表明存在新数据。此表将包含有关数据和日期的基本信息。最有可能的是每个 CSV 文件的一条或两条记录。 我知道如何使用HBas
-
Java MD5哈希与C#MD5哈希不匹配
问题内容: 我对加密/哈希知之甚少。 我必须对加密密钥进行哈希处理。Java中的示例是这样的… 现在,如果我错了,请纠正我,但是上面的代码使用MD5算法对字符串进行了哈希处理。 当我在C#中哈希相同的字符串时,我希望得到相同的结果。 我当前的C#代码看起来像这样… 但是末字节结果不匹配。 Java得到… C#得到… 我需要C#代码才能获得与Java代码相同的结果(不是相反),有什么想法吗? 谢谢。
-
列表不可哈希,但元组可哈希?
问题内容: 在如何哈希列表?有人告诉我,我应该转换为一个元组第一,如到。 因此,第一个不能散列,而第二个可以散列。为什么*? *我并不是真正地在寻求详细的技术说明,而是在寻找一种直觉 问题答案: 主要是因为元组是不可变的。承担以下工作: 现在,当您这样做时会发生什么?您已修改字典中的键!远道而来!如果您熟悉哈希算法的工作原理,这会让您感到恐惧。另一方面,元组是绝对不变的。看起来好像是在修改元组,但
-
将Java哈希码合并为“主”哈希码
问题内容: 我有一个实现了hashCode()的向量类。它不是我写的,而是使用2个质数对2个向量分量进行异或运算。这里是: …因为这是来自已建立的Java库,所以我知道它可以正常工作。 然后,我有一个Boundary类,其中包含2个向量:“开始”和“结束”(代表直线的端点)。这两个向量的值是边界的特征。 在这里,我尝试为构成该边界的向量的唯一2元组(起点和终点)创建一个良好的hashCode()。
-
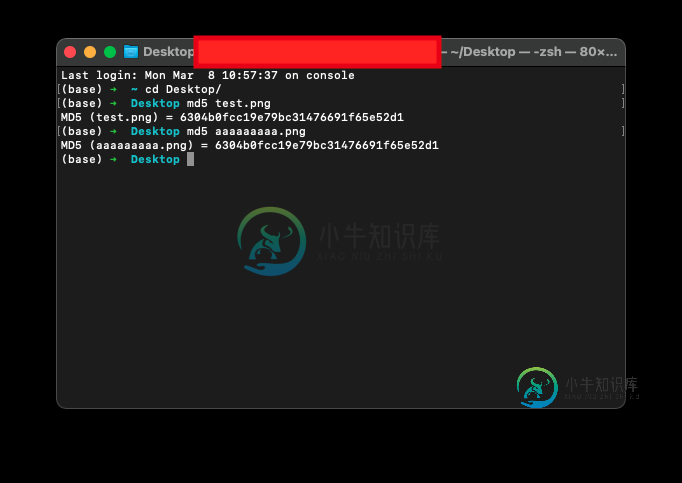 Swift:计算出的图像文件md5哈希与终端和其他哈希生成器不匹配
Swift:计算出的图像文件md5哈希与终端和其他哈希生成器不匹配我想计算一个图像的哈希,首先我把图像转换成数据,然后在这个函数的帮助下,我会计算图像文件的哈希(数据),但是生成的哈希不匹配在线生成器和其他语言转换器,像(Java),甚至我尝试了其他库,但我得到相同的结果,我想当我转换成数据的时候,我的文件发生了一些事情,所以哈希不匹配其他转换器。 但当我计算一个纯文本散列时,它与所有在线转换器和其他语言转换器匹配,但与图像不一样? 谢谢你的帮助
-
拉雷维尔雄辩的哈斯曼->哈斯曼
可以在一个集合/json? 使用者- 用户:id | name post:id |用户| id |文本 postimage: id|post_id|imgpath 用户模型: 帖子模式: 从用户处获取所有帖子工作正常: 我能够在一个循环内从帖子中获取所有图像 我想要的是得到所有的帖子,没有循环的图像,例如 谢啦
-
 米哈游笔试第一题90%ac输出内容过多
米哈游笔试第一题90%ac输出内容过多米哈游第一题: 任何数字都可以由不同的3的幂加或减组成。 28 = 27 + 1 20 = 27 - 9 + 3 - 1 输入一个n 输出上述可以构成n的唯一字符串,从大到小排列 例如: 输入: 20 输出 27-9+3-1 这道题我a了90%,最后一个例子没过没搞明白为什么 首先思路是递归f(20) = 27 - f(7),然后过0%,说系统栈爆炸了,我直接慌了当时做了30min了,不能0啊;
-
对perl中哈希的哈希的两个级别的键进行排序
我有一个代码,我需要跟踪不同类别中给定位置的一些值(随机出现)(并且数量相当大;~40,000),所以我认为散列散列是最好的方法,类别作为第一层键,位置作为第二层,值作为值;类似于: 然后,我需要按照这两个类别的顺序对它们进行排序和打印,然后进行定位,得到如下输出文件: 但是我无法计算出嵌套排序的语法(或者,有人比这种方法有更好的想法吗?
-
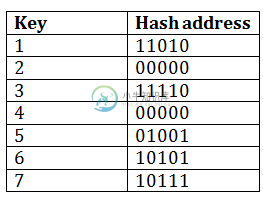 DBMS动态哈希
DBMS动态哈希主要内容:如何搜索一个键,如何插入新记录动态哈希方法用于克服桶溢出等静态哈希问题。 在此方法中,随着记录的增加或减少,数据桶会增大或减小。 此方法也称为可扩展哈希方法。 该方法使哈希动态化,即,它允许插入或删除而不会导致性能不佳。 如何搜索一个键 首先,计算键的哈希地址。 检查目录中使用了多少位,这些位称为。 取哈希地址的最不重要的位。 这给出了目录的索引。 现在使用索引,转到目录并查找记录可能位于的存储区地址。 如何插入新记录 首先,
-
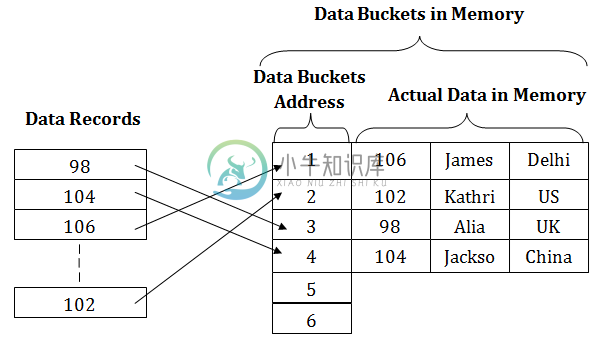 DBMS静态哈希
DBMS静态哈希主要内容:静态哈希的操作,1.打开散列,2.关闭哈希在静态哈希中,结果数据桶地址将始终相同。 这意味着如果使用散列函数生成地址,那么它将始终产生相同的桶地址。这里,桶地址不会有任何变化。 因此,在这种静态散列中,内存中数据桶的数量始终保持不变。 在这个例子中,在内存中有五个数据桶用于存储数据。 静态哈希的操作 搜索记录 - 当需要搜索记录时,相同的哈希函数检索存储数据桶的地址。 插入记录 - 当一个新记录插入表中时,将根据哈希键为新记录生成一个地址
-
Swif哈希集合
Swift 4集合是用于存储相同类型的不同值,但它们没有像数组那样的有明确排序顺序。 如果不需要元素排序,或者需要没有重复值(唯一值),则可以使用集合而不是数组(集合只允许不同的值)。 类型必须是可散列类型并且是可以比较的,才能存储在一个集合中。哈希值是对象的值相等。例如,如果两个对象相等:,则。 默认情况下,所有基本值都是可散列类型,可以用作集合值。 创建集 使用以下初始化语法创建某个类型的空集
-
Flink哈州后端
我试图为HA设置配置Flink 1.2.0,在那里我必须设置一个名为状态后端的参数。我之前已经将此参数设置为rocksdb,但随后阅读了留档,其中说HA只有文件系统可用。这是真的吗?(HA设置只支持文件系统状态后端,没有rocksdb可用?)或者这是指一个不同的(特定于动物园管理员的)状态后端? 谢谢!
-
Ruby解析哈希
所以我使用gem文件从reddit的首页拉链接。gem函数返回一个哈希,其中包含首页上的所有链接及其所有信息(评论、业力、作者、日期、链接、上升、下降等的#)。下面是包含我首页上第一个链接信息的哈希请求: {"modhash"= 结尾<code>,</code>分隔下一个链接,如下所示: {“种类”= 我基本上需要某种方法来解析这个散列的每个条目,这样我就可以将所有相关的东西存储到一个数组中。实际