《轻松筹》专题
-
垃圾收集年轻一代扫描
我在尝试理解垃圾收集机制,我在研究代际算法,我有一个关于年轻人和老年人的代沟的问题。我读到,在年轻一代开始收集物品,GC是从GC根开始标记它们,以找到活的,通常它会将它们复制到幸存者空间,清除年轻一代区域,然后瞧。 我不明白,如果我们从GC根开始,我们开始遍历活动对象,我们不是也在旧一代中找到了对象吗?这是否意味着,当我们击中旧空间中的一个物体时,我们会在那个点上停止跟踪参照物?
-
年轻一代的JVM垃圾收集
如果我错了,请随时指正。在JVM堆中,有老一代和年轻一代两代。在做全GC时,在老一代中,有像紧凑空间和修复漏洞这样的繁重操作,这会使JVM挂起。而我发现在年轻一代中,应用了一个轻量级的GC,从我的搜索结果中还有一个叫做Eden的区域涉及年轻一代。但是,在搜索了很多文档后,我对年轻一代中的GC仍然有两个困惑, 在年轻一代中,GC似乎不像老一代GC那样工作(即老一代GC压缩并修复漏洞)?如果是这样,年
-
如何使PyCharm更快/更轻?[重复]
我真的很喜欢PyCharm的想法,也很乐意使用它。然而,它消耗计算机处理能力和延迟的倾向是一个很大的缺点。 在不久的将来,我将运行Python入门课程,并建议学生安装PyCharm,因为它似乎是目前最友好的IDE。 有没有一种方法可以加快PyCharm的速度,使其处理更加“轻松”?
-
FixedThreadPool与CachedThreadPool:两害相权取其轻
我有一个程序,它产生执行一系列任务的线程(~5-150)。最初,我使用,因为这个类似的问题表明它们更适合更长时间的任务,而且由于我对多线程的知识非常有限,我认为线程的平均寿命(几分钟)是“长寿命”的。 但是,我最近添加了生成额外线程的功能,这样做使我超过了我设置的线程限制。在这种情况下,是猜测并增加我可以允许的线程数,还是切换到,这样就不会浪费线程? 初步尝试了这两种方法,似乎没有什么不同,所以我
-
如何使用轻推邮件功能?
在轻推邮件功能中成功配置邮箱后,可利用轻推进行邮件接收和发送。 操作办法:我-邮件-配置邮件 查看邮件-发送邮件
-
第9章 轻量级线程:协程
在常用的并发模型中,多进程、多线程、分布式是最普遍的,不过近些年来逐渐有一些语言以first-class或者library的形式提供对基于协程的并发模型的支持。其中比较典型的有Scheme、Lua、Python、Perl、Go等以first-class的方式提供对协程的支持。 同样地,Kotlin也支持协程。 本章我们主要介绍: 什么是协程 协程的用法实例 挂起函数 通道与管道 协程的实现原理 c
-
7. 附录:轻量级标记语言
没有标记语言就没有Web和丰富多彩的互联网,但创造了Web的HTML语言并非尽善尽美,存在诸如难读、难写、难以向其他格式转换的问题。究其根源是因为HTML语言是一种“重”标记语言,对机器友好而并非对人友好。 下面这段HTML源码,非技术控阅读起来会遇到困难。 <html> <head> <meta content='application/xhtml+xml;charset=utf-8' ht
-
高内聚力和松耦合的优化
在一次技术采访中,我被问及项目的凝聚力和耦合性。我详细解释了它们的定义,尽管我没有像他说的那样正确回答问题的第二部分。 “我们如何在一个项目中同时实现高度内聚和松散耦合的设计,请解释这种方法应该如何在一个整体项目中实现?” 我回答说这两个目标是矛盾的,所以我们需要找出每个项目或模块的最佳选择,但我无法提供全面的答案。 如果有人能帮我,我将不胜感激。
-
松鼠SQL-UCANACCESS_HOME系统变量未定义
设置 Windows10 1709, 16299.64 松鼠SQLsquirrel-sql-3.8.0安装在"C:\Program Files\squirrel-sql-3.8.0" UCanAccess UCanAccess-4.0.2-bin安装在"C:\Java\UCanAccess-4.0.2-bin" Java8更新151 我不熟悉SquirrelSQL。我正在尝试使用UCanAcces
-
AnyLogic的到达率是泊松分布吗?
-
 松下电器面经-嵌软(要线下)
松下电器面经-嵌软(要线下)1.先做笔试题 2.hr和技术主管一起面 3.三个人一起面都是我们学校的😂轮流发言,主要问项目还有一些其他的性格之类的问题,没八股,笔试题也还好,一周内出结果,薪资8-13k,六险一金,加班但不多,日企 #23届找工作求助阵地#
-
设置杜松子酒找不到的路线
问题内容: 我在Gin中设置了默认路由器和一些路由: 但是我该如何处理杜松子酒中找不到404路线? 最初,我使用的是了解Gin所用的httprouter,所以这就是我最初拥有的… 和功能: 但这对杜松子酒不起作用。 我需要能够使用返回JSON,这样我才能使用: 问题答案: 您正在寻找的是处理程序。 更确切地说:
-
Heroku雪松堆栈上的Node.js端口问题
问题内容: 我在Node.js中运行一个基本的Express应用程序,并尝试部署到Heroku。该应用程序在本地运行良好,我相信我在Heroku上的设置一直很好,直到启动服务器时出现以下错误: 这是目前我在app.js中拥有的所有内容 我也按照Heroku入门中所述运行了此程序。 我相信我只需要设置生产端口即可?谢谢。 问题答案: 您可以显示调用的整个代码部分吗?您应该检查过程环境变量PORT,而
-
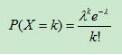 Python数据可视化:泊松分布详解
Python数据可视化:泊松分布详解本文向大家介绍Python数据可视化:泊松分布详解,包括了Python数据可视化:泊松分布详解的使用技巧和注意事项,需要的朋友参考一下 一个服从泊松分布的随机变量X,表示在具有比率参数(rate parameter)λ的一段固定时间间隔内,事件发生的次数。参数λ告诉你该事件发生的比率。随机变量X的平均值和方差都是λ。 代码实现: 以上这篇Python数据可视化:泊松分布详解就是小编分享给大家的全部
-
数据之间松耦合的最佳实践
假设我们有一个带有s的表示一行注释。这些笔记存储在某个地方(本地数据库、网络等),每次调用时,都会根据存储的数据绘制正确数量的s。 现在,假设用户想要删除注释,解析特定 返回到其存储实体的最佳方式是什么? 目前,我知道的唯一方法是使用< code >视图。标签,并有一些管理器将它转换成数据实体,但它看起来相当混乱。 还有其他选择吗?