《中国农业银行》专题
-
kubernetes中的Flink部署无法启动作业
我按照以下指南在kubernetes创建了一个flink集群:https://ci.apache.org/projects/flink/flink-docs-release-1.11/ops/deployment/native_kubernetes.html 作业管理器正在运行。当作业提交给作业管理器时,它生成了一个任务管理器pod,但任务管理器无法连接到作业管理器。
-
从Spring批次中的步骤启动作业
我试图从步骤(实现接口Tasklet的类的execute方法)内部启动作业。 显然我收到了例外 Java语言lang.IllegalStateException:在JobRepository中检测到现有事务 如何使Spring批处理步骤不是事务性的? 有人能解决我从一步内启动工作的主要需求吗? 提前感谢您的帮助!
-
如何在kubernetes作业中创建init容器?
在job.yaml下面用于创建作业。未创建初始化容器。 [root@app]#kubectl版本客户端版本:version.info{Major:“1”,Minor:“15”,GitVersion:“v1.15.5”,GitCommit:“”,GitTreeState:“Clean”,BuildDate:“2019-10-15T19:16:51Z”,GoVersion:“Go1.12.10”,编译
-
生产中需要的后台作业框架
如果知道是否存在一个解决以下问题的框架,那就太好了: 由于Spring Batch在一个Tomcat容器(1个java进程)中运行,因此任何作业/步骤中的任何小更新都将导致Tomcat服务器的重新启动。这将导致硬停止所有正在运行的作业,从而导致数据不完整/陈旧。 我想要的是:捆绑所有的jar,并将每个作业作为一个单独的进程运行。框架应该存储PID,并且应该能够根据需要管理(停止/强制终止)作业。这
-
在Spring批处理中排队作业实例
我们使用spring-core和spring-beans 3.2.5、spring-batch-integration 1.2.2、spring-integration-core 3.0.5、spring-integration-file、-http、-sftp、-stream 2.0.3
-
在simple webapp中使用quartz schedular调度作业
我是否需要? 我需要吗?我不能使用类/servlet做同样的事情吗? 如何初始化计划程序以及谁将触发作业? 我有一个执行作业独立程序,我可以在任何servlet的init中编写,并在容器启动时启动servlet。这样做对吗?
-
在Unix中以30分钟启动cron作业
我想从9:30到12点每两分钟运行一次cron作业。我该怎么做? 这是正确的吗?我应该在哪里加30?
-
ADLS文件中的数据块作业微件
我有一个文本小部件,用户需要在批处理id说“201906”饲料,这是一年与月。所以这个特定批次的数据被处理。那么,现在我如何从位于ADLS容器中的CSV或文件名中获取该值,并在databricks dropdown小部件中使用它,以便用户不能自由输入不需要处理或限制处理的batchid?因此,基本上我想给用户的选择与所需的批处理,但不是一个完整的字段来输入他想要的任何东西。
-
如何从程序中停止flink流作业
我正在尝试为Flink流媒体作业创建JUnit测试,该作业将数据写入kafka主题,并分别使用和从同一kafka主题读取数据。我正在通过生产中的测试数据: 以及检查来自消费者的数据是否与以下数据相同: 使用。 通过打印流,我能够看到来自消费者的数据。但无法获得Junit测试结果,因为即使消息完成,使用者仍将继续运行。所以它并没有来测试这个部件。 在或中是否有任何方法停止进程或运行特定时间?
-
在c中首先调度最短的作业
所以我正在研究调度,包括FCFS和最短作业优先。我首先真的在纠结我最短的工作,我看不到我的逻辑错误。我把它打印出来,有些数字是正确的,但不是全部。我使用的测试文件包含以下文本: 我使用 任何帮助,指针或代码,将不胜感激! 编辑我认为我的问题是基于sfj函数的逻辑。对于输入,第一列是进程id,第二列是到达时间,第三列是突发时间或进程需要cpu多长时间。 我得到的输出是: 当我真正期望时:
-
火花作业中的Kryo序列化错误
IOException:找不到键类'com.test.serializetest.toto'的序列化程序。如果使用自定义序列化,请确保配置“io.serializations”配置正确。在org.apache.hadoop.io.sequenceFile$writer.init(sequenceFile.java:1179)在org.apache.hadoop.io.sequenceFile$wr
-
带Spring Boot的Google app engine中的Cron作业
还有关于如何在App Engine中创建Cron作业的链接 我正在使用Spring Boot for Google App Engine,那么我如何使用Spring Boot进行Cron作业呢?
-
Apache Flink作业中的多数据流支持
其他流式框架(如Apache Samza、Storm或Nifi)是否可以实现这一点? 我们非常期待得到答复。
-
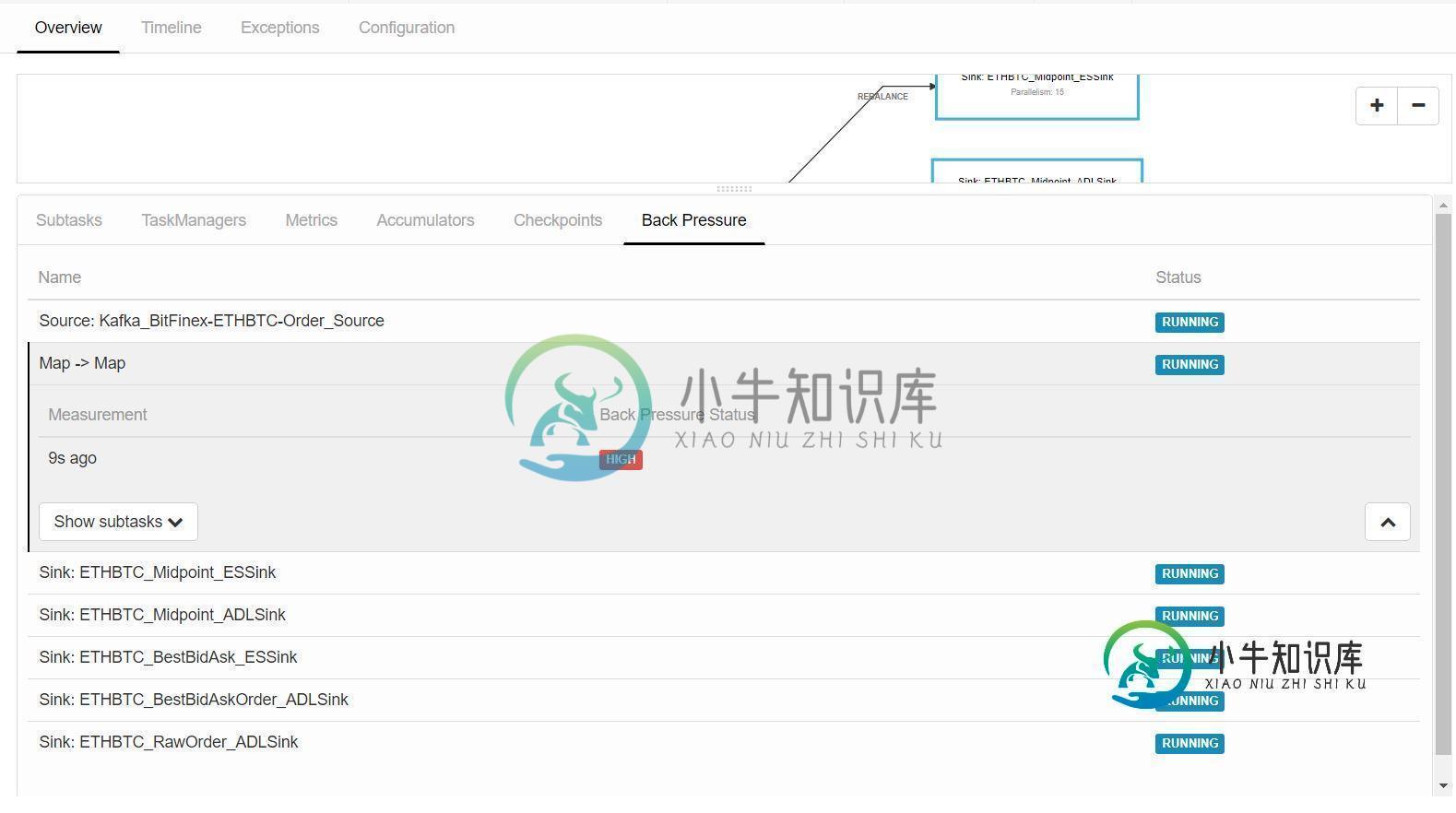 如何处理flink流作业中的背压?
如何处理flink流作业中的背压?我正在运行一个流式flink作业,它消耗来自kafka的流式数据,在flink映射函数中对数据进行一些处理,并将数据写入Azure数据湖和弹性搜索。对于map函数,我使用了1的并行性,因为我需要在作为全局变量维护的数据列表上逐个处理传入的数据。现在,当我运行该作业时,当flink开始从kafka获取流数据时,它的背压在map函数中变得很高。有什么设置或配置我可以做以避免背压在闪烁?
-
列出业务网络中的所有身份
当向参与者发放新身份或者将现有身份绑定到参与者时,在已部署的业务网络中的身份库中一个身份与参与者之间的映射被创建。当该参与者使用该身份将事务提交到已部署的业务网络时,Composer运行时会在身份库中查找该身份的有效映射。这种查找是使用公钥签名或指纹完成的,指纹本质上是证书内容的散列(对证书和身份唯一的)。 为了在已部署的业务网络中执行身份管理操作,你需要列出和查看身份库中的一组身份。 在你开始之