《内推》专题
-
如果刷新AJAX请求的内容(ob_flush),将加载该内容吗?
问题内容: 我的意思是……让我们只是发出AJAX请求,然后将结果插入div#result中。 在后端脚本中,使用 ob_flush() 发送标头,但直到请求终止(使用 exit 或 ob_flush_end )后才终止请求 仅当请求终止( exit 或 ob_flush_end )时,内容才会加载到#result中,否则,每次脚本由 ob_flush 发送标头时,内容都会加载到 #result中
-
C中静态内存分配与动态内存分配的成本
问题内容: 当您知道on上对象/项目的确切数量时,我非常想知道哪种内存分配方法对性能(例如,运行时间)有利,这对性能有好处。少量对象(少量内存)和大量对象(大量内存)的成本。 与 请告诉我。谢谢。 注意:我们可以对此进行基准测试,并且可能知道答案。但是我想知道解释这两种分配方法之间性能差异的概念。 问题答案: 静态分配将更快。静态分配可以在全局范围和堆栈上进行。 在全局范围内,静态分配的内存内置在
-
何时在Linux内核中使用内核线程vs工作队列
问题内容: 在Linux内核中有许多安排工作的方法:计时器,tasklet,工作队列和内核线程。什么时候使用一个对另一个的准则是什么? 有明显的因素:计时器功能和小任务无法进入睡眠状态,因此它们无法等待互斥量,条件变量等。 在驱动程序中为我们选择哪种机制的其他因素是什么? 首选的机制是什么? 问题答案: 如您所说,这取决于手头的任务: 工作队列将工作推迟到内核线程中-您的工作将始终在流程上下文中运
-
预期2.6.16和2.6.26内核版本之间的“内核太旧”错误
问题内容: 我在运行带有内核2.6.26-2-amd64的Linux(Debian)的计算机上构建了一个应用程序,我想在运行运行内核2.6.16.60-0.21-smp的Linux(Suse)的另一台计算机上运行此应用程序,但是出现了错误“致命:内核太旧”。 我从互联网上的研究中得知,如果针对未编译为支持较早内核版本的glibc库进行构建,则可能会发生这种情况,但它通常涉及2.4版。是否有可能针对
-
 Python中集合的内建函数和内建方法学习教程
Python中集合的内建函数和内建方法学习教程本文向大家介绍Python中集合的内建函数和内建方法学习教程,包括了Python中集合的内建函数和内建方法学习教程的使用技巧和注意事项,需要的朋友参考一下 集合内建函数和内建方法 (1)标准类型函数 len():把集合作为参数传递给内建函数 len(),返回集合的基数(或元素的个数)。 (2)集合类型工厂函数 set()和 frozenset()工厂函数分别用来生成可变
-
在AngularJS中的Ajax调用后呈现动态HTML(angularjs内容)内容
问题内容: 我是刚接触Angular的人,在拨打Ajax电话后被卡住了。注入DOM后,如何呈现/编译html内容,以便仍可以使用AngularJs函数。 由于后端的设置方式,我必须通过ajax($ http)获取内容。我正在制作没有jQuery的应用。我尝试了$ compile和$ apply,但是没有用。我在这里想念什么。 我在http://jsfiddle.net/rexonms/RB7FQ/
-
Android 如何获取手机总内存和可用内存等信息
本文向大家介绍Android 如何获取手机总内存和可用内存等信息,包括了Android 如何获取手机总内存和可用内存等信息的使用技巧和注意事项,需要的朋友参考一下 在android开发中,有时候我们想获取手机的一些硬件信息,比如android手机的总内存和可用内存大小。 这个该如何实现呢? 通过读取文件"/proc/meminfo"的信息能够获取手机Memory的总量,而通过ActivityMan
-
Linux下Java的虚拟内存使用率,使用的内存过多
问题内容: 我在Linux下运行的Java应用程序有问题。 当启动应用程序时,使用默认的最大堆大小(64 MB),我看到使用tops应用程序为该应用程序分配了240 MB的虚拟内存。这会给计算机上的某些其他软件带来一些问题,这是相对有限的资源。 据我了解,保留的虚拟内存无论如何都不会使用,因为一旦达到堆限制,OutOfMemoryError就会抛出。我在Windows下运行了相同的应用程序,并且看
-
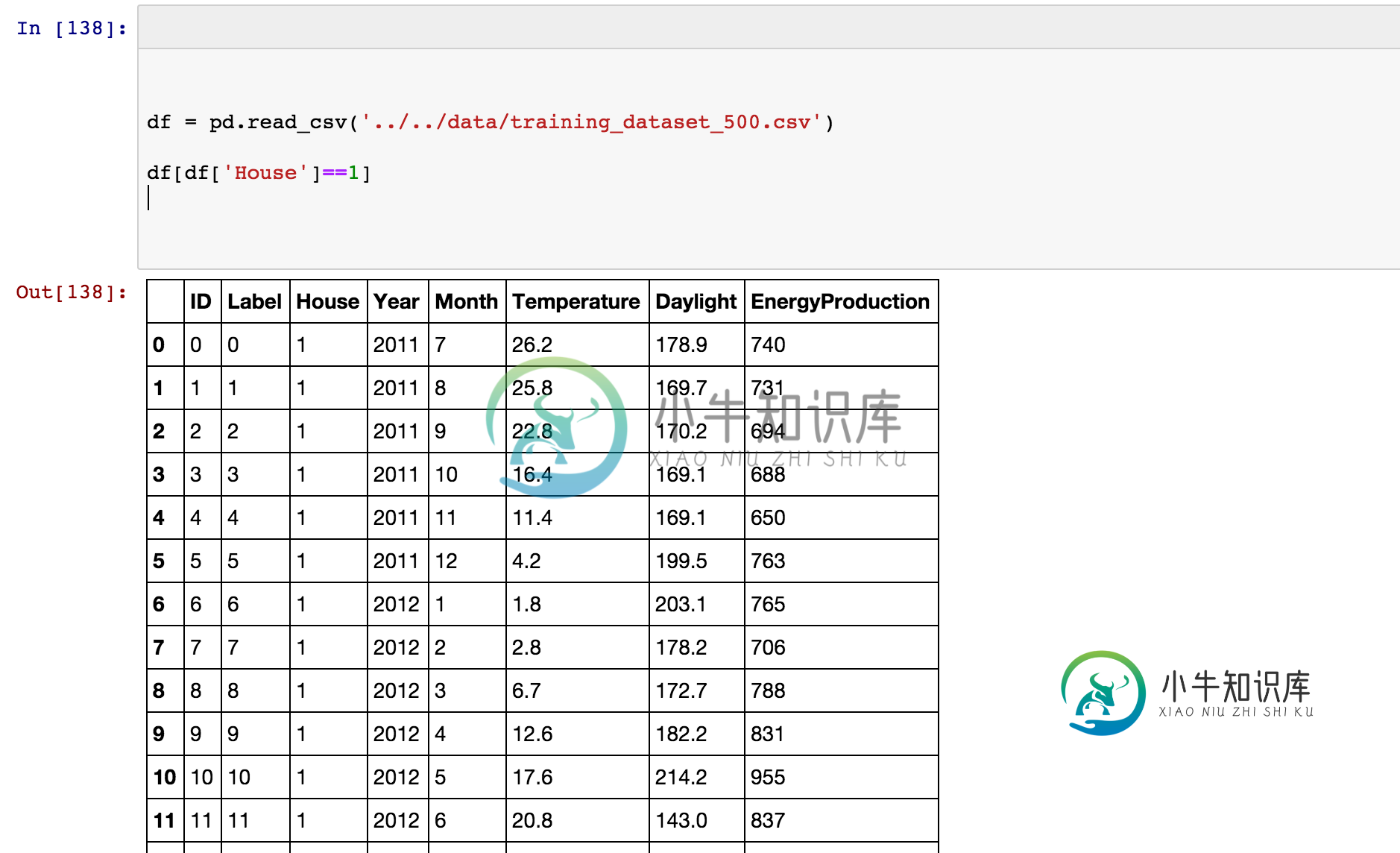 如何在熊猫数据帧中使用内/内运算符?[重复]
如何在熊猫数据帧中使用内/内运算符?[重复]我想从我的CSV文件中选择数据。 虽然我可以在哪一列中获取数据 如下所示,我不知道如何从何处获取数据
-
什么是Spark中的驱动内存和执行器内存?[副本]
我是一个新的spark框架,我想知道什么是驱动内存和执行器内存?从两者中获得最大性能的有效方法是什么?
-
G1GC会导致内存逐渐增长,而全GC会降低内存
我正在centos 6上运行java应用程序,使用G1GC运行openjdk版本“1.8.0_232”。我看到堆的总使用量逐渐增加,导致应用程序崩溃。当我对活动对象进行堆转储时,转储大小仅为1.6GB,但我使用的总堆容量为32GB。 用于获取dump:jmap-dump:live、format=b、file=/tmp/dump的命令。hprof 从某个地方读到,jmap dump命令会触发一个完整
-
 JVM消耗的本机内存与java进程总内存使用量
JVM消耗的本机内存与java进程总内存使用量我有一个很小的java控制台应用程序,我想在内存使用方面进行优化。它是在Xmx设置为仅64MB的情况下运行的。根据不同的监视工具(htop、ps、pmap、Dynatrace)显示进程的总体内存使用量超过250MB。我主要在Ubuntu18上运行它(也在其他操作系统上测试)。 我使用了-xx:nativeMemoryTracking,java param和jcmd的本地内存跟踪,以找出为什么在堆之
-
 如何在node.js中跟踪堆内对象以发现内存泄漏?
如何在node.js中跟踪堆内对象以发现内存泄漏?我有内存泄漏,我知道它在哪里(我想是这样的),但我不知道为什么会发生。负载测试以下endpoint(使用服务器)时发生内存泄漏: 我非常肯定对象没有被(垃圾回收器)释放。在每一个请求中,应用程序使用的内存都在增长。我做了一些附加测试: 因此,在每个请求中,我都将big object分配给对象作为其属性。我观察到,有了这个附加属性,内存增长得快得多。在60秒内每完成1000个请求,内存会增加100M
-
第6章 OpenCL主机端内存模型 - 6.3 共享虚拟内存
OpenCL 2.0的一个重要的修订就是支持共享虚拟内存(SVM)。共享虚拟内存属于全局内存,其相当于在主机内存区域上做的扩展,其允许上下文对象上的所有设备能和主机共享这块内存。SVM能将结构体指针作为参数传入内核,这相较之前的标准方便许多。例如,在未使用SVM之前,在主机端创建的链表结构无法传递到内核中,只能一个节点一个节点的传入。那么,2.0之后如何将链表实例通过传参的形式传入内核呢?将内存块
-
OpenPyXL +如何在Excel的单元格中搜索内容,如果内容符合搜索条件,则更新内容?
问题内容: 我正在使用Python项目(使用2.7)在Excel文件中搜索正在更改的服务器的UNC路径,然后使用新的UNC路径更新单元格。我是python的新手,我能够找到该单元格并使用以下命令进行打印: 但是,我不知道如何用新的字符串更新单元格,并且工作簿似乎处于只读模式。可能是因为ws仅在获取信息。 我在网上找到了很多资源来搜索单元格和打印信息,但是没有找到有关信息后如何更新单元格的资源。关于