《字节跳动265》专题
-
Amazon EC2,mysql中止启动,因为InnoDB:mmap(x字节)失败;埃尔诺12
问题内容: 我已根据此处的内容在EC2上设置了 微型 实例服务器 mysql服务器频繁失败,并且第三次mysql服务器不见了。日志仅显示 到底是什么?以及如何给我更多的空间/内存或进行修复所需的一切。 我每次通过重新启动整个系统并删除所有日志并重新启动mysql服务器来解决此问题。但是我知道我的配置有问题。 我的“ my.cnf”也如下所示: 问题答案: 当我尝试在没有RDS的微型实例上运行wor
-
如何将字节写入服务器套接字
问题内容: 我正在编写一个Java套接字程序来从服务器读取数据,我无法控制服务器,以下是协议的约定, 2字节:幻数 2字节:数据长度 N字节:ASCII字符串数据有效载荷 大尾数表示幻数和数据长度 例如:如果我的请求是“ command / 1 / getuserlist”,如何构造以上协议的请求匹配并将响应读回到List 我是套接字编程的新手,也不知道如何构建我的请求并读回响应。 有人可以指导我
-
Java中字符的大小不是2字节吗?
问题内容: 我以前是byte从文本文件中读取的。 为什么我看到一个完整的字符被读取? 问题答案: A 表示Java 中的字符。它长2个字节(至少这是有效值范围所建议的大小)。 这并不一定意味着一个字符的每个表示都长2个字节。实际上,许多编码只为每个字符保留1个字节(或为最常见的字符使用1个字节)。 当调用构造函数你问的Java的转换至使用平台的默认编码。由于平台默认编码通常是1字节编码(例如ISO
-
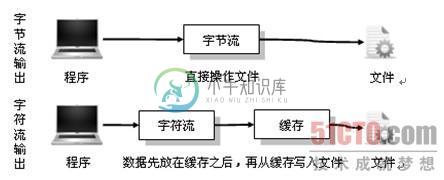 java 字节流和字符流的区别详解
java 字节流和字符流的区别详解本文向大家介绍java 字节流和字符流的区别详解,包括了java 字节流和字符流的区别详解的使用技巧和注意事项,需要的朋友参考一下 字节流与和字符流的使用非常相似,两者除了操作代码上的不同之外,是否还有其他的不同呢? 实际上字节流在操作时本身不会用到缓冲区(内存),是文件本身直接操作的,而字符流在操作时使用了缓冲区,通过缓冲区再操作文件,如图所示。 下面以两个写文件的操作为主进行比较,但是在操作时
-
为什么Java中没有字节或短文字?
问题内容: 我可以通过将L附加到值来创建文字。为什么我不能以类似的方式创建字面量的short或byte?为什么我需要在转换时使用int文字? 如果答案是“因为C中没有短文字”,那么为什么C中没有短文字? 这实际上并没有以任何有意义的方式影响我的生活;写(短)0而不是0S很简单。但是这种矛盾使我感到好奇。这是当您深夜起床时困扰您的事情之一。有人在某个时候做出了设计决定,使得可以为某些原始类型输入文字
-
将字符串打印为十六进制字节?
问题内容: 我有这个字符串:我想使用Python作为打印它。 仅适用于整数。 怎么做到呢? 问题答案: 您可以将字符串转换为int生成器,对每个元素应用十六进制格式,并使用分隔符插入:
-
协议缓冲区是否支持字节[]字段?
我正在尝试更新Android BluetoothChat示例的代码,以使用Protobuf进行更结构化的数据交换。我还需要byte[]数组字段来发送任意数据,如图像字节数组,但在尝试编译时。proto文件,我得到以下错误。 协议文件/蓝牙消息。proto:8:18:应为字段名。 下面是我的. proto文件。 stackoverflow上的其他几个帖子提到byte[]可以用作文件,下面的页面也说了
-
将字符串打印为十六进制字节
我有这个字符串:并且我想使用Python将其打印为48:65:6c:6c:6f:2c:20:57: 6f: 72:6c: 64:21。 仅适用于整数。 怎样才能做到呢?
-
如何在Python中处理多字节字符串
问题内容: PHP中有多字节字符串函数来处理多字节字符串(例如:CJK脚本)。例如,我想通过使用python中的函数来计算一个多字节字符串中有多少个字母,但是它返回的结果不准确(即该字符串中的字节数) PHP中有像mb_strlen这样的软件包或函数吗? 问题答案: 使用Unicode字符串: 注意字符串前面。 要将字节字符串转换为Unicode,请使用:
-
PDO DBLIB多字节(中文)字符编码-SQL server
在Linux机器上,我使用PDO DBLIB连接到MSSQL数据库,并将数据插入表。问题是,当我尝试插入中文字符(多字节)时,它们被插入为
-
相同字符、不同长度和字节[重复]
从韩国网站下载文件时,文件名经常被错误编码/解码,最终变得混乱不堪。我发现通过用iso-8859-1编码并用euc-kr解码,我可以解决这个问题。然而,我有一个新问题,看起来一样的角色实际上是不同的。看看Python shell的下面: 可以使用“iso-8859-1”对第一个字符串进行编码。后者并非如此。因此,问题是: 这两个字符串之间有什么区别 为什么从同一个网站下载的内容会有不同格式的相同字
-
将IPV4地址从字节转换为字符串
我目前正在尝试创建一个聊天服务器作为一个分配,并希望每个消息包含一个头。它将包含ipv4地址,后跟一个字母,然后是用户名 我可以很容易地从字节中解码字符串字母,但现在我很难从字节中解码ipv4地址 我只需要一种方法来尝试和解码四个字节的整数到一个字符串或一些沿这些线的东西 谢谢:D
-
哈希字符串的字节转换,java vs python
我对将纯java Curve25519函数转换为Python等效函数存在问题,具体问题与将哈希字符串转换为字节等效函数的摘要函数有关,java实现: 数据示例: sP=“这是一个用于测试目的的密码短语示例” 生成此字节输出: 82, -57, 124, 58, -105, 76, 123, 3, 119, -21, 121, 71, -54, 73, -75, 54, 31, -33, -49,
-
MQTT Kafka源连接器:有趣的字节字符
mqttpublisher.py mqttsubscriber.py py ConsumerRecord(Topic='mqtt.',partition=0,offset=225,timestamp=1545117270870,timestamp_type=0,key=b'\x00\x00\x00\x01\x16sensor/dist“,value=b'\x00\x00\x00\x00\x01\x
-
字节缓冲到Java中的字符串[重复]
我有这行代码 其中缓冲区是字节缓冲区。 有没有一种方法可以在不分配新字符串和/或复制字符数组的情况下将字节缓冲符转换为字符串?(也就是说,有没有办法将字符串的char[]值安全地指向字节缓冲区的byte[]hb?) 谢谢