《朴朴》专题
-
再学贝叶斯网络 TAN 树型朴素贝叶斯算法
前言 在前面的时间里已经学习过了NB朴素贝叶斯算法, 又刚刚初步的学习了贝叶斯网络的一些基本概念和常用的计算方法。于是就有了上篇初识贝叶斯网络的文章,由于本人最近一直在研究学习<<贝叶斯网引论>>,也接触到了许多与贝叶斯网络相关的知识,可以说朴素贝叶斯算法这些只是我们所了解贝叶斯知识的很小的一部分。今天我要总结的学习成果就是基于NB算法的,叫做Tree Augmented Naive Bays,中
-
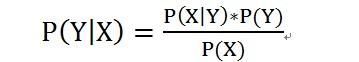 Python实现朴素贝叶斯的学习与分类过程解析
Python实现朴素贝叶斯的学习与分类过程解析本文向大家介绍Python实现朴素贝叶斯的学习与分类过程解析,包括了Python实现朴素贝叶斯的学习与分类过程解析的使用技巧和注意事项,需要的朋友参考一下 概念简介: 朴素贝叶斯基于贝叶斯定理,它假设输入随机变量的特征值是条件独立的,故称之为“朴素”。简单介绍贝叶斯定理: 乍看起来似乎是要求一个概率,还要先得到额外三个概率,有用么?其实这个简单的公式非常贴切人类推理的逻辑,即通过可以观测的数据,
-
朴素贝叶斯算法和非结构化文本 - 训练阶段
首先,我们统计所有文本中一共出现了多少个不同的单词,记作“|Vocabulary|”(总词汇表)。 对于每个单词wk,我们将计算P(wk|hi),每个hi(喜欢和讨厌两种)的计算步骤如下: 将该分类下的所有文章合并到一起; 统计每个单词出现的数量,记为n; 对于总词汇表中的单词wk,统计他们在本类文章中出现的次数nk: 最后应用下方的公式:
-
第4章 基于概率论的分类方法:朴素贝叶斯
朴素贝叶斯 概述 贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。本章首先介绍贝叶斯分类算法的基础——贝叶斯定理。最后,我们通过实例来讨论贝叶斯分类的中最简单的一种: 朴素贝叶斯分类。 贝叶斯理论 & 条件概率 贝叶斯理论 我们现在有一个数据集,它由两类数据组成,数据分布如下图所示: 我们现在用 p1(x,y) 表示数据点 (x,y) 属于类别 1(图中用圆点表示
-
Python实现的朴素贝叶斯算法经典示例【测试可用】
本文向大家介绍Python实现的朴素贝叶斯算法经典示例【测试可用】,包括了Python实现的朴素贝叶斯算法经典示例【测试可用】的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python实现的朴素贝叶斯算法。分享给大家供大家参考,具体如下: 代码主要参考机器学习实战那本书,发现最近老外的书确实比中国人写的好,由浅入深,代码通俗易懂,不多说上代码: 运行结果: 32 ['him', 'gar
-
朴素贝叶斯算法和非结构化文本 - 新闻组语料库
我们下面要处理的数据集是新闻,这些新闻可以分为不同的新闻组,我们会构造一个分类器来判断某则新闻是属于哪个新闻组的: 比如下面这则新闻是属于rec.motorcycles组的: 注意到这则新闻中还有一些拼写错误(如accesories、ussually等),这对分类器是一个不小的挑战。 这些数据集都来自 http://qwone.com/~jason/20Newsgroups/ (我们使用的是20n
-
使用Weka J48和朴素贝叶斯多项式分类器改进分类结果
我一直在使用Weka的J48和Naive Bayes多项式(NBM)分类器对RSS提要中的关键字频率进行分类,以将提要分类为目标类别。 例如,我的一个。arff文件包含以下数据提取: 以此类推:总共有570行,每行都包含一天的提要中关键字的频率。在这种情况下,10天内有57条feed,总共有570条记录需要分类。每个关键字都以代理项编号作为前缀,并以“频率”作为后缀。 我在“黑盒”的基础上对J48
-
如何在stanford分类器中使用朴素贝叶斯分类器、SVM和最大熵
目前,我正在用朴素贝叶斯算法、支持向量机和最大熵做一个引文句分类器,目前我的数据是110个非引文句和10个引文句。我用代码从斯坦福分类器的例子中进行分类,结果很好。但是分类器是拟牛顿的。如何使用朴素贝叶斯分类器、支持向量机和最大熵?我已经尝试编辑道具文件并添加“usenb=true”,但结果发现所有数据都是非引用语句类的。我已经在http://nlp.stanford.edu/nlp/javado
-
使用scikit-learn在朴素贝叶斯分类器中混合分类数据和连续数据
问题内容: 我正在Python中使用scikit-learn开发分类算法,以预测某些客户的性别。除其他外,我想使用Naive Bayes分类器,但是我的问题是我混合使用了分类数据(例如:“在线注册”,“接受电子邮件通知”等)和连续数据(例如:“年龄”,“长度”成员资格”等)。我以前没有使用过scikit,但我想高斯朴素贝叶斯适用于连续数据,而伯努利朴素贝叶斯可以用于分类数据。但是,由于我想在模型中
-
朴素贝叶斯算法和非结构化文本 - 非结构化文本的分类算法
在前几个章节中,我们学习了如何使用人们对物品的评价(五星、顶和踩)来进行推荐;还使用了他们的隐式评价——买过什么,点击过什么;我们利用特征来进行分类,如身高、体重、对法案的投票等。这些数据有一个共性——能用表格来展现: 因此这类数据我们称为“结构化数据”——数据集中的每条数据(上表中的一行)由多个特征进行描述(上表中的列)。而非结构化的数据指的是诸如电子邮件文本、推特信息、博客、新闻等。这些数据至
-
基于朴素贝叶斯和支持向量机分类器的斯坦福NLP核心情感分析
嗨,我是情感分析的新手,我目前正在使用StanfordNLP核心API。我能够从句子中得到情感,积极的,中立的和消极的。有什么例子我可以遵循使用不同的分类器算法提供的api,如朴素贝叶斯和支持向量机,以获得不同的情感得分比较。谢谢你。
-
朴素贝叶斯模型的二元分类度量评估中如何给出预测列和标签列
我对< code > binary classification metrics (ml lib)输入感到困惑。根据Apache Spark 1.6.0,我们需要从已预测概率(向量)的转换数据帧中传递< code>(RDD[(Double,Double)])类型的predicted和label 我已经从预测列和标签列创建了RDD[(Double,Double)]。在NavieBayesModel上