
Python实现朴素贝叶斯的学习与分类过程解析

概念简介:
朴素贝叶斯基于贝叶斯定理,它假设输入随机变量的特征值是条件独立的,故称之为“朴素”。简单介绍贝叶斯定理:
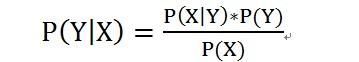
乍看起来似乎是要求一个概率,还要先得到额外三个概率,有用么?其实这个简单的公式非常贴切人类推理的逻辑,即通过可以观测的数据,推测不可观测的数据。举个例子,也许你在办公室内不知道外面天气是晴天雨天,但是你观测到有同事带了雨伞,那么可以推断外面八成在下雨。
若X 是要输入的随机变量,则Y 是要输出的目标类别。对X 进行分类,即使求的使P(Y|X) 最大的Y值。若X 为n 维特征变量 X = {A1, A2, …..An} ,若输出类别集合为Y = {C1, C2, …. Cm} 。
X 所属最有可能类别 y = argmax P(Y|X), 进行如下推导:
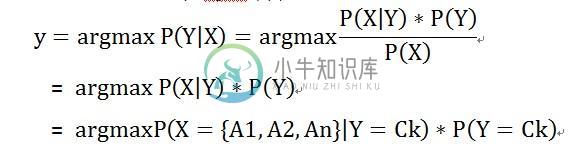
朴素贝叶斯的学习
有公式可知,欲求分类结果,须知如下变量:
各个类别的条件概率,

输入随机变量的特质值的条件概率

示例代码:
import copy
class native_bayes_t:
def __init__(self, character_vec_, class_vec_):
"""
构造的时候需要传入特征向量的值,以数组方式传入
参数1 character_vec_ 格式为 [("character_name",["","",""])]
参数2 为包含所有类别的数组 格式为["class_X", "class_Y"]
"""
self.class_set = {}
# 记录该类别下各个特征值的条件概率
character_condition_per = {}
for character_name in character_vec_:
character_condition_per[character_name[0]] = {}
for character_value in character_name[1]:
character_condition_per[character_name[0]][character_value] = {
'num' : 0, # 记录该类别下该特征值在训练样本中的数量,
'condition_per' : 0.0 # 记录该类别下各个特征值的条件概率
}
for class_name in class_vec:
self.class_set[class_name] = {
'num' : 0, # 记录该类别在训练样本中的数量,
'class_per' : 0.0, # 记录该类别在训练样本中的先验概率,
'character_condition_per' : copy.deepcopy(character_condition_per),
}
#print("init", character_vec_, self.class_set) #for debug
def learn(self, sample_):
"""
learn 参数为训练的样本,格式为
[
{
'character' : {'character_A':'A1'}, #特征向量
'class_name' : 'class_X' #类别名称
}
]
"""
for each_sample in sample:
character_vec = each_sample['character']
class_name = each_sample['class_name']
data_for_class = self.class_set[class_name]
data_for_class['num'] += 1
# 各个特质值数量加1
for character_name in character_vec:
character_value = character_vec[character_name]
data_for_character = data_for_class['character_condition_per'][character_name][character_value]
data_for_character['num'] += 1
# 数量计算完毕, 计算最终的概率值
sample_num = len(sample)
for each_sample in sample:
character_vec = each_sample['character']
class_name = each_sample['class_name']
data_for_class = self.class_set[class_name]
# 计算类别的先验概率
data_for_class['class_per'] = float(data_for_class['num']) / sample_num
# 各个特质值的条件概率
for character_name in character_vec:
character_value = character_vec[character_name]
data_for_character = data_for_class['character_condition_per'][character_name][character_value]
data_for_character['condition_per'] = float(data_for_character['num']) / data_for_class['num']
from pprint import pprint
pprint(self.class_set) #for debug
def classify(self, input_):
"""
对输入进行分类,输入input的格式为
{
"character_A":"A1",
"character_B":"B3",
}
"""
best_class = ''
max_per = 0.0
for class_name in self.class_set:
class_data = self.class_set[class_name]
per = class_data['class_per']
# 计算各个特征值条件概率的乘积
for character_name in input_:
character_per_data = class_data['character_condition_per'][character_name]
per = per * character_per_data[input_[character_name]]['condition_per']
print(class_name, per)
if per >= max_per:
best_class = class_name
return best_class
character_vec = [("character_A",["A1","A2","A3"]), ("character_B",["B1","B2","B3"])]
class_vec = ["class_X", "class_Y"]
bayes = native_bayes_t(character_vec, class_vec)
sample = [
{
'character' : {'character_A':'A1', 'character_B':'B1'}, #特征向量
'class_name' : 'class_X' #类别名称
},
{
'character' : {'character_A':'A3', 'character_B':'B1'}, #特征向量
'class_name' : 'class_X' #类别名称
},
{
'character' : {'character_A':'A3', 'character_B':'B3'}, #特征向量
'class_name' : 'class_X' #类别名称
},
{
'character' : {'character_A':'A2', 'character_B':'B2'}, #特征向量
'class_name' : 'class_X' #类别名称
},
{
'character' : {'character_A':'A2', 'character_B':'B2'}, #特征向量
'class_name' : 'class_Y' #类别名称
},
{
'character' : {'character_A':'A3', 'character_B':'B1'}, #特征向量
'class_name' : 'class_Y' #类别名称
},
{
'character' : {'character_A':'A1', 'character_B':'B3'}, #特征向量
'class_name' : 'class_Y' #类别名称
},
{
'character' : {'character_A':'A1', 'character_B':'B3'}, #特征向量
'class_name' : 'class_Y' #类别名称
},
]
input_data ={
"character_A":"A1",
"character_B":"B3",
}
bayes.learn(sample)
print(bayes.classify(input_data))
总结:
朴素贝叶斯分类实现简单,预测的效率较高
朴素贝叶斯成立的假设是个特征向量各个属性条件独立,建模的时候需要特别注意
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
还是让我们回到运动员的例子。如果我问你Brittney Griner的运动项目是什么,她有6尺8寸高,207磅重,你会说“篮球”;我再问你对此分类的准确度有多少信心,你会回答“非常有信心”。 我再问你Heather Zurich,6尺1寸高,重176磅,你可能就不能确定地说她是打篮球的了,至少不会像之前判定Brittney那样肯定。因为从Heather的身高体重来看她也有可能是跑马拉松的。 最后,
-
上例的数据格式如下: both sedentary moderate yes i100 both sedentary moderate no i100 health sedentary moderate yes i500 appearance active moderate yes i500 appearance moderate aggressive yes i500
-
训练阶段 朴素贝叶斯需要用到先验概率和条件概率。让我们回顾一下民主党和共和党的例子:先验概率指的是我们已经掌握的概率,比如美国议会中有233名共和党人,200名民主党人,那共和党人出现的概率就是: P(共和党) = 233 / 433 = 0.54 我们用P(h)来表示先验概率。而条件概率P(h|D)则表示在已知D的情况下,事件h出现的概率。比如说P(民主党|法案1=yes)。朴素贝叶斯公式中,我
-
我们会在这章探索朴素贝叶斯分类算法,使用概率密度函数来处理数值型数据。 内容: 朴素贝叶斯 微软购物车 贝叶斯法则 为什么我们需要贝叶斯法则? i100、i500健康手环 使用Python编写朴素贝叶斯分类器 共和党还是民主党 数值型数据 使用Python实现
-
在所有的机器学习分类算法中,朴素贝叶斯和其他绝大多数的分类算法都不同。对于大多数的分类算法,比如决策树,KNN,逻辑回归,支持向量机等,他们都是判别方法,也就是直接学习出特征输出Y和特征X之间的关系,要么是决策函数Y=f(X),要么是条件分布P(Y|X)。但是朴素贝叶斯却是生成方法,也就是直接找出特征输出Y和特征X的联合分布P(X,Y),然后用P(Y|X)=P(X,Y)/P(X)得出。 朴素贝叶斯
-
朴素贝叶斯 概述 贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。本章首先介绍贝叶斯分类算法的基础——贝叶斯定理。最后,我们通过实例来讨论贝叶斯分类的中最简单的一种: 朴素贝叶斯分类。 贝叶斯理论 & 条件概率 贝叶斯理论 我们现在有一个数据集,它由两类数据组成,数据分布如下图所示: 我们现在用 p1(x,y) 表示数据点 (x,y) 属于类别 1(图中用圆点表示