《朴朴》专题
-
stanford-nlp朴素贝叶斯分类器训练
作为理解用于分类的斯坦福nlp api的一部分,我在一个非常简单的训练集(3个标签=>['快乐'、'悲伤'、'中立'])上训练朴素贝叶斯分类器。此训练数据集为
-
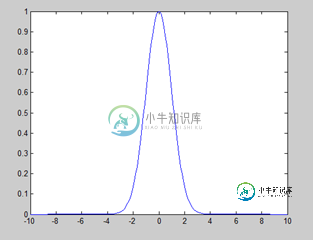 python中如何使用朴素贝叶斯算法
python中如何使用朴素贝叶斯算法本文向大家介绍python中如何使用朴素贝叶斯算法,包括了python中如何使用朴素贝叶斯算法的使用技巧和注意事项,需要的朋友参考一下 这里再重复一下标题为什么是"使用"而不是"实现": 首先,专业人士提供的算法比我们自己写的算法无论是效率还是正确率上都要高。 其次,对于数学不好的人来说,为了实现算法而去研究一堆公式是很痛苦的事情。 再次,除非他人提供的算法满足不了自己的需求,否则没必要"重复造轮
-
 朴素贝叶斯算法的python实现方法
朴素贝叶斯算法的python实现方法本文向大家介绍朴素贝叶斯算法的python实现方法,包括了朴素贝叶斯算法的python实现方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了朴素贝叶斯算法的python实现方法。分享给大家供大家参考。具体实现方法如下: 朴素贝叶斯算法优缺点 优点:在数据较少的情况下依然有效,可以处理多类别问题 缺点:对输入数据的准备方式敏感 适用数据类型:标称型数据 算法思想: 比如我们想判断一个邮件是
-
朴素贝叶斯分类器与训练数据
当用整个集合测试时,当使用分类器对一组新的tweet进行测试时,它只返回“中性”作为标签,但当使用30个时,它只返回正,这是否意味着我的训练数据不完整或过于“加权”中性条目,以及我的分类器在使用大约4000个tweet时只返回中性的原因? 我已经在下面包括了我的完整代码。
-
朴素贝叶斯 - 共和党还是民主党
我们来看另一个数据集——美国国会投票数据,可以从 机器学习仓库 获得。 每条记录代表一个选民,第一列是分类名称(democrat, republican),之后是16条法案,用y和n表示该人是否支持。 残疾婴儿法案 用水成本分摊 预算改革 医疗费用 萨瓦尔多援助 校园宗教组织 反卫星武器 尼加拉瓜援助 MX导弹 移民法案 合成燃料缩减 教育支出法案 有毒废物基金 犯罪 出口免税 南非出口管控 文件
-
问题:朴素贝叶斯(naive Bayes)法的要求是?
本文向大家介绍问题:朴素贝叶斯(naive Bayes)法的要求是?相关面试题,主要包含被问及问题:朴素贝叶斯(naive Bayes)法的要求是?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 贝叶斯定理、特征条件独立假设 解析:朴素贝叶斯属于生成式模型,学习输入和输出的联合概率分布。给定输入x,利用贝叶斯概率定理求出最大的后验概率作为输出y。
-
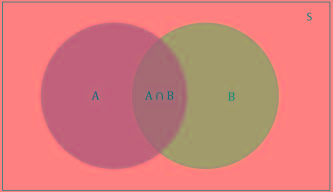 朴素贝叶斯基本原理和预测过程
朴素贝叶斯基本原理和预测过程本文向大家介绍朴素贝叶斯基本原理和预测过程相关面试题,主要包含被问及朴素贝叶斯基本原理和预测过程时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 朴素贝叶斯分类和预测算法的原理 决策树和朴素贝叶斯是最常用的两种分类算法,本篇文章介绍朴素贝叶斯算法。贝叶斯定理是以英国数学家贝叶斯命名,用来解决两个条件概率之间的关系问题。简单的说就是在已知P(A|B)时如何获得P(B|A)的概率。朴素贝叶斯(N
-
为什么lambda IntStream.anyMatch()比朴素的实现慢10个?
问题内容: 我最近在分析代码,发现其中一个有趣的瓶颈。这是基准: 结果: 如果显示Array包含通过lambda进行的操作比使用简单循环的朴素实现慢10倍。我知道lambda应该会慢一些。但是十倍?我做错了lambda还是这是java的问题? 问题答案: 您的基准测试实际上并不衡量性能,而是衡量流开销。与非常简单的操作(如五元素数组查找)相比,此开销可能会很明显。 如果我们从相对数转为绝对数,增速
-
朴素贝叶斯算法和非结构化文本
这一章我们会尝试使用朴素贝叶斯算法来对非结构化文本进行分类。我们是否能够判断出Twitter上的一片影评是正面评价还是负面的呢? 内容: 非结构化文本的分类算法 训练阶段 使用朴素贝叶斯进行分类 新闻组语料库 朴素贝叶斯与情感分析
-
在NLTK中保存朴素贝叶斯训练分类器
问题内容: 关于如何保存经过训练的分类器,我有些困惑。就像在其中一样,每次我想使用分类器时都要对其进行重新训练显然很糟糕而且很慢,如何保存它并在需要时再次加载它?代码如下,在此先感谢您的帮助。我正在将Python与NLTK朴素贝叶斯分类器一起使用。 问题答案: 保存: 稍后加载:
-
NLTK中词袋朴素贝叶斯分类器的实现
-
为什么说朴素贝叶斯是高偏差低方差?
本文向大家介绍为什么说朴素贝叶斯是高偏差低方差?相关面试题,主要包含被问及为什么说朴素贝叶斯是高偏差低方差?时的应答技巧和注意事项,需要的朋友参考一下 它简单假设了各个特征之间是无关的,是一个被严重简化了的模型,所以,对于这样一个简单模型,大部分场合都会bias部分大于variance部分,也就是高偏差低方差
-
如何指定scikit-learn的朴素贝叶斯的先验概率
问题内容: 我正在将scikit-learn机器学习库(Python)用于机器学习项目。我使用的算法之一是高斯朴素贝叶斯实现。 GaussianNB() 函数的属性之一如下: 我想手动更改该类,因为我使用的数据非常不正确,并且召回其中一个类非常重要。通过为该类别分配较高的先验概率,召回率应会增加。 但是,我不知道如何正确设置属性。我已经阅读了以下主题,但他们的答案对我不起作用。 如何在scikit
-
关于使用朴素贝叶斯进行分类,改进结果
我有一个数据集,有10个类,每个类40个示例(总共400个示例) 我为每个示例提取了大约27个特征。我使用了朴素贝叶斯分类器,使用十倍交叉验证,获得了大约96.75%的准确率。 我从混淆矩阵中注意到,十个类中只有两个类混淆了几个示例,而其余的类总是分类正确。然后,我决定删除除这两个类之外的所有其他类,保留相同数量的特征,并重新运行朴素贝叶斯分类器;它总是能够将示例正确地分为两类。 我很困惑为什么会
-
朴素贝叶斯 - 为什么我们需要贝叶斯法则?
首先回顾一下贝叶斯公式: 再看看微软购物车的数据: 比如,我们为居住在邮编为88005地区的客户设置两个事件:买或不买Sencha绿茶,即: P(h1|D) = P(买绿茶|88005) P(h2|D) = P(┐买绿茶|88005) 你也许会问,这两个概率我们都可以直接从数据中计算得到,为什么还要计算下面这个公式呢? 那是因为在现实问题中要计算P(h|D)往往是很困难的。 以上一节中的医学示例来