《特来电》专题
-
在条件成立时,可以使用SQL约束来防止更改特定值吗?
问题内容: 我知道SQL约束会强制数据满足有效性标准。但是,诸如“仅在’finallyed’标志为假时才可以更新学生的成绩”之类的标准呢?应用程序是否必须处理此类更新条件? 问题答案: 简短的答案:不,当Finalized为’true’时,SQL约束本身不能阻止对列Grade的更改(但允许其他更改)。 有几种SQL约束:CHECK,DEFAULT,NOT NULL,UNIQUE,主键和外键。 这些
-
ARCORE:通过单击此可渲染文件来删除特定的可渲染文件
我正在使用ARCore的Sceneform进行一个项目。我基于ARCore提供的HelloSceneform示例开发它。我想做的是通过点击添加一个可渲染对象,然后当我点击屏幕上的特定可渲染对象时删除它。我尝试了以下方法AnchorNode.setOnTapListener,但它不起作用(没有响应): 我还尝试了以下方法,这会导致意外的接近: 是否有任何方法可以实现此功能?
-
 找不到一种方法来给曼德尔布罗特设定的目标上色
找不到一种方法来给曼德尔布罗特设定的目标上色我已经成功地为Mandelbrot集上色,尽管我不能放大太远,直到它变得“模糊”并且图案停止。我通过增加max_迭代来解决这个问题,这是可行的,但在*1放大时,我得到的颜色很少,很多颜色只有在放大时才会出现。我理解为什么会发生这种情况,因为在一个“真实”的Mandelbrot集合中没有颜色,而增加max_迭代只会使它更接近这一点。但我的问题是,像youtube上这样的缩放在整个缩放过程中是如何拥有
-
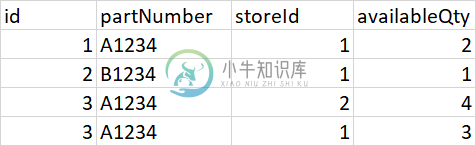 MySQL-如何通过连接三个表和过滤器来获得特定列的和
MySQL-如何通过连接三个表和过滤器来获得特定列的和有三张桌子 库存-包含库存信息 订单-包含订单的存储信息 OrderParts-包含与订单关联的部分 库存表 订单表 订购零件表 需要生成以下预期报告 查询试图实现上述结果 获取已订购数量为空 请告诉我如何得到预期的累计订货量。提前道谢。
-
通过用正则表达式模式否定Unicode字母来验证特殊字符?
这个regex:匹配这些字符"示例字符串的ASKJKSDJKDSJÄÖÅüé" "ASKJKSDJK_-。;,DSJ!”#€% 我想匹配多种语言中任何和所有不是字母或数字的字符。 一个负正则表达式可能是一个自然的方向吗? 我应该提到我想找到的正则表达式的一个预期用途是验证规则的密码: 它需要包含至少一个特殊字符,我定义为不是数字也不是字母。 如果可能的话,似乎应该避免定义特殊字符的范围,因为为什么
-
所以我想通过java中的枚举,使用特定的字符来移动obect
我仍在学习,希望得到任何帮助:) 我肯定我没有正确地解释自己,所以这里是这个特定部分的uml,以防万一它可以为我在这里试图做的事情增加任何清晰度: 我很感激任何花时间来看看这个并帮助整个n00b的人。这一部分让我有点疯狂:)
-
在Android上拦截来电
我想为我的Android手机写一个软件,拦截来电,并播放一个简短的音频剪辑,指示来电者按“1”继续通话。这是打电话推销员的。 备注: > 很难得到一个明确的答案,因为在2012年,Android2.3(姜饼)删除了一些与修改手机状态相关的重要API,见这里。然而,Android7(“牛轧糖”)似乎支持呼叫阻塞(见这里),所以我希望当前的API支持拦截呼叫。 我不想像这里建议的那样将呼叫转发到某个服
-
拦截来电Android/iOS/Hybrid
null 任何帮助都是欢迎的,谢谢。
-
 来未来Java后端实习生二面
来未来Java后端实习生二面自我介绍+项目介绍:5分钟左右; 如果说不用Redis来做分布式锁,你刚刚提到的超卖问题有什么解决方案吗?基于乐观锁的CAS思想。 Redis的分布式锁你们是自己写的呢还是用的Redission?我们自己实现了的,共享对象作为lock_key,加锁的客户端的唯一标识作为value,配置上NX参数表示只在lock_key不存在时,才对lock_key进行设置操作,同时也需要配置一下EX也就是超时时间
-
特征抽取和转换 - 特征选择
VectorSlicer是一个转换器,输入一个特征向量输出一个特征向量,它是原特征的一个子集。这在从向量列中抽取特征非常有用。 VectorSlicer接收一个拥有特定索引的特征列,它的输出是一个新的特征列,它的值通过输入的索引来选择。有两种类型的索引: 1、整数索引表示进入向量的索引,调用setIndices() 2、字符串索引表示进入向量的特征列的名称,调用setNames()。这种情况需
-
特征抽取和转换 - 特征转换
规则化器缩放单个样本让其拥有单位$L^{p}$范数。这是文本分类和聚类常用的操作。例如,两个$L^{2}$规则化的TFIDF向量的点乘就是两个向量的cosine相似度。 Normalizer实现VectorTransformer,将一个向量规则化为转换的向量,或者将一个RDD规则化为另一个RDD。下面是一个规则化的例子。 import org.apache.spark.SparkConte
-
特征抽取和转换 - 特征抽取
1 介绍 词频-逆文档频率法(Term frequency-inverse document frequency,TF-IDF)是在文本挖掘中广泛使用的特征向量化方法。 它反映语料中词对文档的重要程度。假设用t表示词,d表示文档,D表示语料。词频TF(t,d)表示词t在文档d中出现的次数。文档频率DF(t,D)表示语料中出现词t的文档的个数。 如果我们仅仅用词频去衡量重要程度,这很容易过分强调
-
皮查姆的特金特惹了麻烦
第一职位;原谅任何错误。 我最近刚刚开始学习Python,并通过一些基本的在线教程涵盖了基础知识,我想学习如何在Python中创建图形用户界面。明确地说,我是初学者,所以我可能会犯一些愚蠢的错误,但是出于某种原因,我不能让tkinter在PyCharm中工作。 一些信息: > OS: MacOS Catalina 10.15.3 PyCharm:PyCharm CE(昨天刚从站点重新下载) 已经安
-
科特林:康斯特瓦尔vs瓦尔
我知道在Kotlin中,用于声明常量,用于只读属性。然而,我想知道在以下情况下,哪一个更适合使用。 假设我有一个片段,它需要一个用于和的键。我想知道以下两个选项中哪一个更好: 我更喜欢#选项2,因为它清楚地表明是一个常量,值是在编译时确定的。然而,由于它是在顶层声明的,它需要在编译后的java代码中创建一个类,即(假设文件名是)。在#选项1中,没有生成额外的类,尽管的值将在运行时分配,而不是恒定的
-
科特林-拉泰尼特VS任何?=null
或 我很困惑为什么需要lateinit关键字,如果我们可以让var为空并在以后分配它。每种方法的利弊是什么?每种方法应该在什么情况下使用?