《花旗》专题
-
 同花顺二面
同花顺二面10.13面的,蛮碎的,记得的一些内容 自我介绍 项目音乐滚动条和歌词浮动怎么实现的 了解过函数式编程吗 知道面向对象吗 怎么看待Vue的学习难度 实习期间主要干什么 实习时写过组件吗,有什么收获 有做过可视化相关的吗 CSS3了解吗,flex和grid了解多少 ES6最喜欢的部分 了解过V8引擎吗 偏向PC端还是移动端 说说webpack,现在最火的打包工具是啥 编程题,开始说出正则题,我说不熟
-
火花行到JSON
我想从Spark v.1.6(使用scala)数据帧创建一个JSON。我知道有一个简单的解决方案,就是做。 但是,我的问题看起来有点不同。例如,考虑具有以下列的数据帧: 我想在最后有一个数据帧 其中C是包含、、的JSON。不幸的是,我在编译时不知道数据框是什么样子的(除了始终“固定”的列和)。 至于我需要这个的原因:我使用Protobuf发送结果。不幸的是,我的数据帧有时有比预期更多的列,我仍然会
-
聚合火花流
我试图从聚合原理的角度来理解火花流。Spark DF 基于迷你批次,计算在特定时间窗口内出现的迷你批次上完成。 假设我们有数据作为- 然后首先对Window_period_1进行计算,然后对Window_period_2进行计算。如果我需要将新的传入数据与历史数据一起使用,比如说Window_priod_new与Window_pperid_1和Window_perid_2的数据之间的分组函数,我该
-
雪花-TABLE命令
我正在搜索TABLE命令的官方文档(它与TABLE( ))不同。 我搜索了所有命令/查询语法,但没有太多成功。
-
火花UDF过载
我有一个要求,火花UDF必须超载,我知道UDF超载是不支持火花。因此,为了克服spark的这一限制,我尝试创建一个接受任何类型的UDF,它在UDF中找到实际的数据类型,并调用相应的方法进行计算并相应地返回值。这样做时,我得到一个错误 以下是示例代码: 有可能使上述要求成为可能吗?如果没有,请建议我一个更好的方法。 注:Spark版本-2.4.0
-
JDBC火花连接
我正在研究建立一个JDBC Spark连接,以便从r/Python使用。我知道和都是可用的,但它们似乎更适合交互式分析,特别是因为它们为用户保留了集群资源。我在考虑一些更类似于Tableau ODBC Spark connection的东西--一些更轻量级的东西(据我所知),用于支持简单的随机访问。虽然这似乎是可能的,而且有一些文档,但(对我来说)JDBC驱动程序的需求是什么并不清楚。 既然Hiv
-
 JavaScript 秘密花园
JavaScript 秘密花园JavaScript 秘密花园是一个不断更新,主要关心 JavaScript 一些古怪用法的文档。 对于如何避免常见的错误,难以发现的问题,以及性能问题和不好的实践给出建议, 初学者可以籍此深入了解 JavaScript 的语言特性。 JavaScript 秘密花园不是用来教你 JavaScript。为了更好的理解这篇文章的内容, 你需要事先学习 JavaScript 的基础知识。在 Mozill
-
 同花顺一面
同花顺一面前几天hr打电话问愿不愿意转Android,那当然得同意了。 面了大约40多分钟吧,手撕了得有10分钟,很气,在提示了一次后,还写了一会才写出来 设计模式原则;设计模式有了解哪些; hashmap工作原理;哈希冲突是什么 什么会造成内存泄漏(我说弱引用;线程未关闭;但是弱引用好像又可以解决内存泄漏,butbut在ThreadLocal中弱引用会导致内存泄漏的呀) http;https;加密传输 项
-
 同花顺一面
同花顺一面时长:40min base:杭州 1、为什么选择前端、如何学习 2、看过哪些与前端或者软件工程相关的书 3、书籍阅读的收获感触 4、技术选型、工程搭建如何考虑与落地 5、项目落地过程中遇到的坑 6、跨域解决方式,细说CORS 7、项目在工程上面还可以做哪些优化 8、uniapp与vue之间的关系 9、手撕全排列 10、个人规划 11、是否使用过gpt、copilot 12、如何判断AI给的答案是否
-
 同花顺一面
同花顺一面自我介绍 项目 MySQL:索引分类,回表,索引覆盖 Redis:RDB,AOF相关 软件开发所遵守的一些原则 Spring:底层一些优秀的设计模式 SpringBoot:自动装配,starter组件 JVM:垃圾回收器 怎么积累技术 手撕股票最大收益(lc122) 未来几年内的工作规划 面试官人很好,没有问很刁钻的问题,表达不清楚的点面试官也会帮助表达
-
JavaScript 秘密花园
这篇文章的作者是两位 Stack Overflow 用户, 伊沃·韦特泽尔 Ivo Wetzel(写作) 和 张易江 Zhang Yi Jiang(设计)。
-
妙码生花 - BuildAdmin
项目是基于Thinkphp6、Vue3、TypeScript、Vite、Pinia、Element Plus等最新稳定技术栈的后台管理系统,支持CRUD代码生成、内置WEB终端可直接执行npm install等命令、还内置了管理员管理/附件管理/会员管理/数据全局回收站/敏感数据修改记录等功能,无需授权即可免费商用,希望可以帮助大家快速开发。 主要特性 �� CRUD代码生成 一行命令即可生成数据
-
火花流后立即使用火花RDD过滤器
我正在使用火花流,我从Kafka读取流。阅读此流后,我将其添加到hazelcast地图中。 问题是,我需要在读取Kafka的流之后立即从地图中过滤值。 我正在使用下面的代码来并行化地图值。 但在这个逻辑中,我在另一个逻辑中使用JavaRDD,即JavaInputDStream.foreachRDD,这会导致序列化问题。 第一个问题是,如何通过事件驱动来运行spark作业? 另一方面,我只是想得到一
-
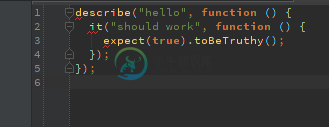 WebStorm茉莉花集成-JSHint无法识别茉莉花
WebStorm茉莉花集成-JSHint无法识别茉莉花我使用文件在 Webstorm 8.0.4 中设置了茉莉花集成 这与语法突出显示的工作方式一样,我可以跳转到声明,文档显示正确。所以连接看起来很好。然而,JSHint仍然为每个关键字抱怨它没有被定义,例如 另请参见以下屏幕截图。正如您所看到的,语法突出显示很好,但我仍然收到一个错误。
-
火花SQL:为什么火花不一直做广播
我在aws s3和emr上使用Spark 2.4进行项目,我有一个左连接,有两个巨大的数据部分。火花执行不稳定,它经常因内存问题而失败。 集群有10台m3.2xlarge类型的机器,每台机器有16个vCore、30 GiB内存、160个SSD GB存储。 我有这样的配置: 左侧连接发生在 150GB 的左侧和大约 30GB 的右侧之间,因此有很多随机播放。我的解决方案是将右侧切得足够小,例如 1G