《花旗金融信息》专题
-
 如何优化火花sql并行运行
如何优化火花sql并行运行我是spark新手,有一个简单的spark应用程序,使用spark SQL/hiveContext: 从hive表中选择数据(10亿行) 做一些过滤,聚合,包括row_number窗口函数来选择第一行,分组,计数()和最大()等。 将结果写入HBase(数亿行) 我提交的作业运行它在纱线集群(100个执行者),它很慢,当我在火花UI中查看DAG可视化时,似乎只有蜂巢表扫描任务并行运行,其余的步骤#
-
在火花 Scala UDF 中定义返回值
想象一下下面的代码: 如何定义myUdf的返回类型,以便查看代码的人立即知道它返回了一个Double?
-
火花广播卡桑德拉连接器
我使用的是datastax提供的spark-cassandra-connector 1.1.0。我注意到了interining问题,我不知道为什么会发生这样的事情:当我广播cassandra connector并试图在执行程序上使用它时,我重复了异常,这表明我的配置无效,无法在0.0.0连接到cassandra。 示例StackTrace:
-
在雪花中无法识别数值“ABC_0011O00001Y31VPQAI”
无法识别数值“ABC_0011O00001Y31VPQAI” 检查表DDL,发现只有3列定义为NUMBER,而rest定义为VARCHAR。 我检查了SELECT查询,在这些NUMBER Datatype列中没有找到任何字符串值。我还尝试在所有Varchar列中搜索值'ABC_0011O00001Y31VPQAI',但没有找到任何 我知道一件事,雪花并不总是显示正确的错误。我是不是漏掉了什么?有什
-
莲花笔记多米诺与java jdk 11
我需要使用JAVA API从莲花笔记发送/提取电子邮件。我正在使用 JDK 11(没有其他选择) 但当我尝试创建会话时,出现了一个问题: 我有以下错误: Lotus Notes与JDK 11不兼容吗? 使它正常工作的快速方法是什么?
-
从ADF调用的雪花存储过程
代码如下:
-
类似 “花瓣” 主页的抽屉效果
实现类似 “花瓣” 主页的抽屉效果。向下滚动列表拉出大图展示,向上滚动隐藏大图展示。 该代码实现了两种效果。第一种效果是:视图刚加载时,view1隐藏在视图的顶部,当往下拖动scrollView时,view1才会出现,继续往下拖动scrollView,view1会随着列表的拖动而移动。当再次往下拖动ScrollView时,View1隐藏。见效果图1。第二种效果跟第一种效果差不多,只不过要隐藏Vie
-
各位,怎么用python画12个花瓣?
from turtle import * circle(40,step = 12) done
-
 DB2 RazorSQL显示信息
DB2 RazorSQL显示信息显示信息用于检索表的所有信息。即表所有者,表名,创建时间,更改时间,无效时间,tableid等。 DB2使用RazorSQL显示信息,按以下步骤操作: 得到以下结果:
-
 Bootstrap4 信息提示框
Bootstrap4 信息提示框主要内容:实例,提示框添加链接,实例,关闭提示框,实例,提示框动画,实例Bootstrap 4 可以很容易实现信息提示框。 提示框可以使用 .alert 类, 后面加上 .alert-success, .alert-info, .alert-warning, .alert-danger, .alert-primary, .alert-secondary, .alert-light 或 .alert-dark 类来实现: 实例 <div class="alert ale
-
Bootstrap5 信息提示框
主要内容:实例,提示框添加链接,实例,关闭提示框,实例,提示框动画,实例Bootstrap 5 可以很容易实现信息提示框。 提示框可以使用 .alert 类, 后面加上 .alert-success, .alert-info, .alert-warning, .alert-danger, .alert-primary, .alert-secondary, .alert-light 或 .alert-dark 类来实现: 实例 <div class="alert ale
-
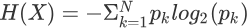 信息熵是什么
信息熵是什么主要内容:理解信息熵,信息熵公式计算,ID3算法—信息增益通过前两节的学习,我们对于决策树算法有了大体的认识,本节我们将从数学角度解析如何选择合适的“特征做为判别条件”,这里需要重点掌握“信息熵”的相关知识。 信息熵这一概念由 克劳德·香农于1948 年提出。香农是美国著名的数学家、信息论创始人,他提出的“信息熵”的概念,为信息论和数字通信奠定了基础。 在理解“信息熵”这个词语前,我们应该理解什么是“信息”。信息是一个很抽象的概念,比如别人说的一段话就包
-
 中汇信息技术
中汇信息技术10.24面试 会问什么呀 线上测评(09-30 14:50生效,于2022-10-10 23:00失效) 大易考试系统,50min,55道行测(判断推理,数字计算,言语理解,定义) 30min,90题,心理测试。 10.11 线上专业笔试 不知道考什么,有了解的朋友路过告知一下吗~~ 答:90min,计算机基础+政治题。10选择+15填空+2算法题。 #笔试##秋招#
-
OrientDB数据库信息
本章介绍如何从OrientDB命令行获取特定数据库的信息。 以下语句是命令的基本语法。 注 - 只有在连接到特定数据库后才能使用此命令,并且它将检索仅当前正在运行的数据库的信息。 示例 在这个例子中,我们将使用我们在前一章中创建的名为的数据库。 将从数据库中检索基本信息。 可以使用以下命令获取数据库信息。 如果成功执行上面命令,将获得以下输出。
-
1.2.3.3 事件元信息
本节对HubbleData的事件,事件属性以及用户信息进行介绍,方便产品方进一步了解HubbleData的事件体系。本节主要包括以下内容: 事件体系,包括内置事件,自动跟踪事件,自定义事件以及虚拟事件 事件属性,包括SDK自动采集的事件属性,以及自定义属性 用户属性,包括内置的属性以及自定义用户属性 1.1. 事件体系 HubbleData的设计中包含以下事件: 内置事件:SDK自动采集,不需要用