《高仙机器人》专题
-
伊奥。微型机器人。运行时。Micronaut-未找到嵌入式容器
我试图构建一个静态编程语言应用程序,但是,即使成功构建,我也会面临以下错误。我做错了什么? 以下是我的构建状态: 这是我毕业典礼的一部分。生成文件:
-
多处理器机器中posix线程的并发性
问题内容: 我对多处理器机器中posix线程的并发性有一些疑问。我在SO中发现了类似的问题,但没有找到最终的答案。 以下是我的理解。我想知道我是否正确。 Posix线程是用户级线程,内核不知道。 内核调度程序会将Process(及其所有线程)视为一个用于调度的实体。依次是线程库选择要运行的线程。它可以在可运行线程之间划分内核给定的cpu时间。 用户线程可以在不同的cpu内核上运行。即让线程T1和T
-
使用容器名称从主机访问Docker容器
问题内容: 我正在开发服务,并在那里使用docker compose来旋转诸如postgres,redis,elasticsearch之类的服务。我有一个基于RubyOnRails的Web应用程序,并从所有这些服务中进行读写操作。 这是我的 我可以在此网络中ping容器 到目前为止,一切都很好。现在我想在主机上的Rails应用程序上运行ruby,但是能够像目前这样使用url访问postgres实例
-
在单独的机器上运行火花驱动器
目前,我正在群集模式(独立群集)下使用Spark 2.0.0,群集配置如下: 工作线程:使用了4个内核:总共32个,使用了32个内存:总共54.7 GB,使用了42.0 GB 我有4个奴隶(工人)和1台主机。火花盘有三个主要部件-主部件、驱动部件、工作部件(参考) 现在我的问题是,驱动程序正在其中一个工作节点中启动,这阻碍了我在其全部容量(RAM方面)中使用工作节点。例如,如果我在运行spark作
-
 画布getImageData方法是否依赖机器/浏览器?
画布getImageData方法是否依赖机器/浏览器?一位客户需要一个提取产品图像主色调的程序的帮助。 我能够用Javascript快速实现这一点;下面的算法仅对图像上3x3网格的中心正方形进行采样,以便快速估计图像中的t恤颜色。 有问题的图像是这个(预览如下)。 但是,在上述代码中处理此图像的结果在不同的机器/浏览器中有所不同:是我在运行Windows7和使用Firefox 32的机器上看到的结果。我运行Mac的客户端在Safari和Firefox
-
高级特征 - 高级类型
Rust 的类型系统有一些我们曾经提到但没有讨论过的功能。首先我们从一个关于为什么 newtype 与类型一样有用的更宽泛的讨论开始。接着会转向类型别名(type aliases),一个类似于 newtype 但有着稍微不同的语义的功能。我们还会讨论 ! 类型和动态大小类型。 这一部分假设你已经阅读了 “高级 trait” 部分的 newtype 模式相关内容。 newtype 模式可以用于一些其
-
更高级的语法高亮
我们甚至可以为Vim里面的语法高亮另开一本书了。 我们将在此讲解它最后的重要内容,然后继续讲别的东西。 如果你想要学到更多,去读:help syntax并阅读别人写的syntax文件。 高亮字符串 Potion,一如大多数编程语言,支持诸如"Hello,world!"的字符串字面量。 我们应该把这些高亮成字符串。为此我们将使用syntax region命令。 在你的Potion syntax文件中
-
使用Selenium Grid时,如何从Hub机器访问节点机器中下载的文件?
以下是我的设想: 我使用的是Selenium Grid的概念,我们从Hub(机器1)触发测试脚本执行,并在节点机器(机器2)的chrome浏览器上执行脚本。在我的一个测试脚本中,当我点击导出按钮时,它会在节点机器(即机器2)的默认下载文件夹中下载一个excel文件 问题:在脚本中,我需要进一步读取下载文件的内容,但由于下载的文件位于节点计算机中,脚本无法从中心访问它。 那么,我们如何从Hub机器访
-
从主机浏览器访问虚拟盒/流浪汉计算机上的Web服务器?
我在运行Ubuntu的VirtualBox/Vagrant机器上有一个Django Web服务器。 我已经按照这个指南创建了一个Django项目:https://docs.djangoproject.com/en/dev/intro/tutorial01/ 我有一个Web服务器运行在在我的客户机内。这是我第一次运行Django Web服务器。它应该是一个hello world应用程序。 如何从主机
-
高密度手机默认使用哪个可绘图文件夹?
如果我在“drawable xhdpi”文件夹中有一个额外的高质量图像,在“drawable mdpi”文件夹中有一个同名的中等质量图像,那么高密度手机会使用这两种图像中的哪一种? 编辑1:纳恩的回答没有回答我的问题。他引用的文章与屏幕大小有关,而我的问题与屏幕密度有关。不过,我遵循了Nanne提供的链接(谢谢Nanne),确实找到了这篇有用的文章: “…当您使用屏幕密度限定符提供替代可绘制资源时
-
 第二次面试,易诚高科手机测试实习面试
第二次面试,易诚高科手机测试实习面试1.自我介绍:介绍了很长一段,因为面试官一直在打电脑边嗯嗯敷衍我,我就一直观察他眼色一边继续介绍,后来我问了还有什么要补充的吗才停下。——总结,自我介绍准备的不够充分,准备少了,并且不要老是观察面试官脸色。 2.是不是一个很敏感的人。我寻思我也不是啊,结果面试官说我自己介绍的时候四处乱瞄,我说我在思考(我真的在思考)。——下次,面试的时候看面试官或固定前面的桌子思考。 3.是否了解过软件测试。——
-
 OD高级人才
OD高级人才我可能还真面试不过
-
 高并发高可用高性能的解决方案
高并发高可用高性能的解决方案主要内容:1.难题与方案,2.具体措施,3.九种技术架构1.难题与方案 1、亿级流量电商网站的商品详情页系统架构 面临难题:对于每天上亿流量,拥有上亿页面的大型电商网站来说,能够支撑高并发访问,同时能够秒级让最新模板生效的商品详情页系统的架构是如何设计的? 解决方案:异步多级缓存架构+nginx本地化缓存+动态模板渲染的架构 2、redis企业级集群架构 面临难题:如何让redis集群支撑几十万QPS高并发+99.99%高可用+TB级海量数据+企业级数
-
MySQL中实现高性能高并发计数器方案(例如文章点击数)
本文向大家介绍MySQL中实现高性能高并发计数器方案(例如文章点击数),包括了MySQL中实现高性能高并发计数器方案(例如文章点击数)的使用技巧和注意事项,需要的朋友参考一下 现在有很多的项目,对计数器的实现甚是随意,比如在实现网站文章点击数的时候,是这么设计数据表的,如:”article_id, article_name, article_content, article_author, art
-
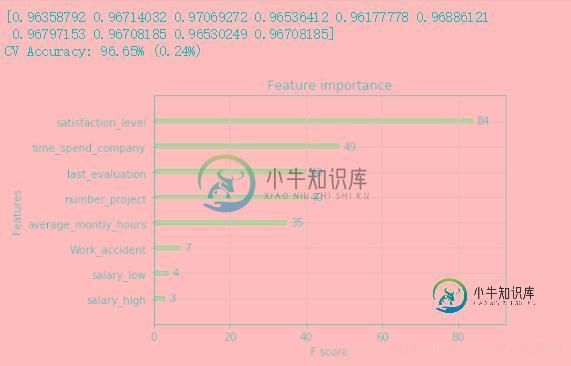 python机器学习库xgboost的使用
python机器学习库xgboost的使用本文向大家介绍python机器学习库xgboost的使用,包括了python机器学习库xgboost的使用的使用技巧和注意事项,需要的朋友参考一下 1.数据读取 利用原生xgboost库读取libsvm数据 使用sklearn读取libsvm数据 使用pandas读取完数据后在转化为标准形式 2.模型训练过程 1.未调参基线模型 使用xgboost原生库进行训练 使用XGBClassifier进行