《拓维信息》专题
-
提交拓扑时找不到Storm?
当我站在上面提交拓扑时,我在storm jar中遇到了问题 我写 打出来的 没有找到Storm指令 我想知道怎么了? Storm罐之间的区别是什么。。。。和 都在提交拓扑?
-
php - AMH安装intl拓展失败?
AMH安装intl拓展失败 LNMP环境intl已安装但是拓展安装失败 最后一行报错: configure: error: Package requirements (icu-uc >= 50.1 icu-io icu-i18n) were not met: No package 'icu-uc' found No package 'icu-io' found No package 'icu-i1
-
java - spring的拓展点有哪些?
spring的拓展点有哪些?
-
 前端 - 微信小程序生成微信支付二维码失败是什么原因?
前端 - 微信小程序生成微信支付二维码失败是什么原因?html 可以打印到dom也获得了二维码地址,dom的情况
-
尝试处理多维数据集,但在模拟信息中出现错误
问题内容: 我在Business Development Intelligent Studio(BIDS)中使用一些名为“ Test_cube”的数据库构建了一个多维数据集,该数据库由“产品”维表,“客户”维表和“订单事实”表组成。 产品表属性:prodID主键,产品名称,产品类型,产品成本 。客户表属性:custID主键,客户名称,custloc 订单表属性:orderID,prodID,客户I
-
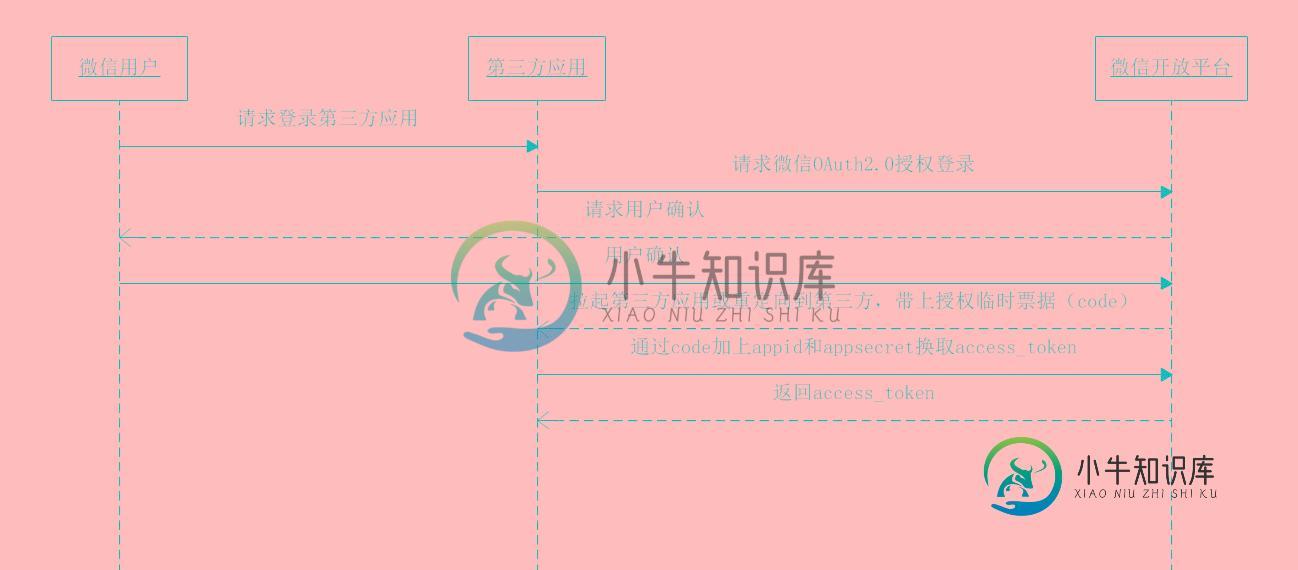 js微信扫描二维码登录网站技术原理
js微信扫描二维码登录网站技术原理本文向大家介绍js微信扫描二维码登录网站技术原理,包括了js微信扫描二维码登录网站技术原理的使用技巧和注意事项,需要的朋友参考一下 微信扫描二维码登录网站是微信开放平台下网站应用的一种接口实现的功能。微信开放平台的网址是https://open.weixin.qq.com 准备工作 网站应用微信登录是基于OAuth2.0协议标准构建的微信OAuth2.0授权登录系统。 在进行微信OAuth2.在进
-
维特。x2->Vert。x 3通过事件总线进行通信
我有一个很快的问题——有人试过同时运行这两个版本吗。x2和垂直。集群中的x 3应用程序,通过EventBus进行通信? 理论上这应该是可能的,但有人做过吗?;) 干杯,米莎
-
通信信息
一、简介 查看和管理系统用户通信信息。 二、功能演示 1.查看和管理通信信息 查看通信信息,选择不需要的通信信息进行删除。如下图:
-
暴风-Kafka-示例应用程序或暴风拓扑的git链接,维护Kafka分区级别的顺序?
我知道,storm并不能保证kafka主题的总体订购保证,但在许多文档中,storm保证消费/处理消息,并在分区级别维护订单。 我正在寻找一个示例storm拓扑,它使用/处理kafka主题的消息,在kafka分区级别维护消息的顺序。。不是全部订单!!只有分区级别的排序保证。 如果您知道任何示例应用程序,请分享。非常感谢!!
-
 拓竹科技后端秋招面经
拓竹科技后端秋招面经一面面试官说主要做客户端,我说我做不来就说帮我转到后端岗位去,扔了一道hard题给我,写出来以后就结束了。 过了几天直接约了后端的二面。 二面1h20min [实习] - [ ] 挖细节,使劲挖,海量数据怎么搞,具体 [算法]- [ ] 判断是否是回文链表(一开始写了个用了辅助数据结构的,让优化,又写了个快慢指针的,但是要反转一半链表,最后让转回来不要破坏原有链表) - [ ] 为什么想做后端 -
-
使用Javascript DFS进行拓扑排序
本文向大家介绍使用Javascript DFS进行拓扑排序,包括了使用Javascript DFS进行拓扑排序的使用技巧和注意事项,需要的朋友参考一下 有向图的拓扑排序或拓扑排序是其顶点的线性排序,这样对于从顶点u到顶点v的每个有向边UV,在该排序中u都位于v之前。这仅在有向图中有意义。 在很多地方,拓扑排序很有意义。例如,假设您正在遵循一个食谱,在这个食谱中,必须执行一些步骤才能进行下一步。但是
-
无法在Apache Storm中运行拓扑
我正在使用相同版本的petrel 0.9.3和apache storm。当我尝试运行拓扑时,会出现以下错误:
-
有向无环图的拓扑排序
如何输出有向无环图的所有可能的拓扑排序?例如,给定一个图形,其中 V 指向 W 和 X,W 指向 Y 和 Z,X 指向 Z: 如何对此图进行拓扑排序以产生所有可能的结果?我能够使用广度优先搜索来获得V,W,X,Y,Z,并使用深度优先搜索来获得V,W,Y,Z,X。但无法输出任何其他种类。
-
如何在storm拓扑中使用drools
现在我想在一个污点中使用Drools,它在LocalCluster中正常工作,但是当我把它放在生产集群中时,它有错误。污点是: 我使用官方文件创建了kiesession。误差为: 也许有些东西没有初始化。但当blot执行时,我创建了一个新的kieservice。有人能帮我吗 谢啦!
-
Storm 0.10.0是否重用拓扑设计?
因此,在某种程度上,拓扑描述了一个文件所需要的流,以计数它所拥有的唯一单词。 如果我有两个文件file1和file2,那么一个应该能够调用相同的拓扑并创建该拓扑的两个实例来运行相同的字数。 为了跟踪单词计数是否确实完成,一旦文件处理完毕,单词计数拓扑的实例应该具有完成状态。 对于文件2 更别提使用storm客户端同样上传jar 另一个问题是,一旦文件被处理,拓扑就无法完成。在我们对拓扑发出杀戮之前