《阿里云》专题
-
如何获取阿帕奇Kafka中的所有话题?
我是apache kafka的新手。现在,有几天想和动物园管理员一起了解Kafka。我想获取与动物园管理员相关的主题。所以我尝试了以下几点 a:)首先我创建了一个动物园管理员客户端,如下所示: 但是使用Java代码执行时主题是空白集。我不明白这里有什么问题。我的动物园管理员道具如下:字符串zkConnect="127.0.0.1:2181";动物园管理员运行得非常好。 请帮助伙计们。
-
php阿拉伯数字转中文人民币大写
本文向大家介绍php阿拉伯数字转中文人民币大写,包括了php阿拉伯数字转中文人民币大写的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了php阿拉伯数字转中文人民币大写的实现代码,供大家参考,具体代码如下 代码1:php阿拉伯数字转中文人民币大写,有详细的注释 代码2:php阿拉伯数字转中文大写金额 希望本文所述对大家学习php程序设计有所帮助。
-
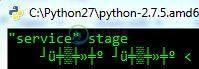 如何使cmd正确显示阿拉伯语脚本?
如何使cmd正确显示阿拉伯语脚本?问题内容: 我正在运行Windows 7,并使用python脚本将一些阿拉伯语字符串输出到Windows cmd。这是我得到的: 如何配置cmd正确显示阿拉伯字符串? 问题答案: 将您的代码页更改为要输出的编码: 这是Windows的阿拉伯语代码页如果您要输出其他编码,则只需在代码页的整个列表中找到它们,然后更改为命令中所需的标识符即可。 提示:UTF-8是65001 注意:要显示以外的其他字符,
-
极大极小与阿尔法贝塔修剪算法
我最近实现了极小极大和阿尔法贝塔修剪算法,我100%确定(自动分级器)我正确地实现了它们。但是当我执行我的程序时,它们的行为不同。我99%确定极小极大和阿尔法贝塔的结束状态应该是相同的。我说得对吗?它们在实现结果的路径上会有所不同吗?因为我们忽略了min将选择的一些值,而max不会选择这些值,反之亦然。
-
阿夫罗。io。AvroTypeException:数据不是模式{…}的示例
我们正在努力将Apache Storm与Kafka的Confluent框架集成在一起。我们正在使用名为“Pyleus”的storm python包装器 我们设置了一个监控数据库表的ConFluent-Kafka JDBC连接器,每当DB发生变化时,新记录将作为Avro格式的Kafka消息发送。 在Pyleus bolt中,我们能够获取Kafka消息,但是,我们无法将其反序列化为JSON。 我们正在
-
组织。阿帕奇。Android Studio build中的commons。gradle文件
我有一个旧的Android项目,版本如下。gradle文件: 将项目与gradle文件同步会导致: 但是,我认为根据这一点,我得到了正确的语法: https://search.maven.org/#artifactdetails|组织。阿帕奇。commons | commons-lang3 | 3.4 | jar 有谁能告诉我我错过了什么吗? N、 B.如果我下载jar并将其放在项目的libs目录
-
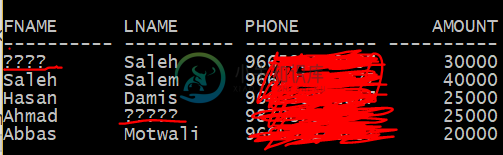 在Oracle 12C上插入/检索阿拉伯文数据
在Oracle 12C上插入/检索阿拉伯文数据我正面临着从Oracle数据库12c获取阿拉伯语内容的问题,我已经回答了大多数问题,但没有任何问题与我一起工作。 我的阿拉伯字符返回如下“?????” 即使在java上,当我获得数据时,它也不会返回阿拉伯值 windows 10笔记本电脑(使用windows 10管理用户登录) Oracle 12C(使用系统用户登录) Java版本“1.8.0_152” 我在这里和网上找到了很多问题,比如: 无法
-
地理编码器。getFromLocation()返回阿拉伯语地址
我在以色列的Android设备上使用Geocoder。直到几周前,一切都很好,当我做反向地理编码时,所有的地址都是用希伯来语收到的。但在某种程度上,我开始得到同样的阿拉伯语地址。 这是我正在运行的示例代码(lat/lon位于特拉维夫): 当我检查“地址”时,我得到以下打印输出: [Address[addressLines=[0:“عمووهلهوممه26”,1:“特拉维夫”,2:“以色列”],特
-
阿帕奇Storm找不到主要的Storm起动器
我正在建立一个ApacheStorm系统,但是在使程序持续运行方面有问题。我已经在三个服务器上建立了Storm,但是它只在一个服务器上持续运行。我认为问题出在命令的路径上。 我一直在使用Storm启动器来设置程序,并在本地使用RollingTopWords进行了测试。当我运行以下命令时,计算机会停止一秒钟,然后我得到以下错误: 无法找到或加载主类Storm。开胃菜。RollingTopWords
-
阿帕奇Storm-喷口和螺栓不存在于StormUI
我正在本地开发一个Storm拓扑。我正在使用Storm 0.9.2孵化,并开发了一个简单的拓扑。当我使用LocalCluster()选项部署它时,它工作得很好,但它不会显示在我的Storm UI中,它只是执行而已。 当我定期部署它时,它会在我的Storm UI中显示拓扑结构,但当我单击它时,不会看到喷口或螺栓。 我还尝试了许多Storm启动项目中的示例WordCountTopology。同样的行为
-
阿帕奇火花 - 无法理解斯卡拉示例
我正在尝试了解这个位置的scala代码。(我来自java背景)。 https://github.com/apache/spark/blob/master/examples/src/main/scala/org/apache/spark/examples/GroupByTest.scala 我在下面的部分感觉完全迷失了 我知道并行化和平面映射的作用。我不明白arr1是如何初始化的。它是 int 类型
-
带有阿帕奇超集的串联河童建筑
互联网上有很多关于kappa架构的信息,在经历了一些概念方面之后,我试图深入研究更具体的东西。作为我的主要来源,我使用了这个网站。 让我们想象一下你想要实现一个涉及以下技术堆栈的kappa架构: Apache Kafka Apache Spark Apache超集 现在想象一下,您要构建的对其进行数据分析的应用程序具有PostgreSQL数据库。当然,您可以轻松地将阿帕奇超集与PostgresSQ
-
阿帕奇卡珊德拉-如何强调木卫一
我已经和Cassandra合作了一段时间,并遵循了以下链接中的基准测试提示: http://www.datastax.com/dev/blog/how-not-to-benchmark-cassandra 我有4个节点运行Cassandra,2个不同的节点使用本机基准测试工具“cassandra-stress”为集群提供数据。我知道,由于Cassandra写操作的LSM特性,它们很难绑定到IO,但
-
了解阿克卡演员存在的三种方法
我正在研究akka actors(JAVA),最近我知道有3种方法(可能更多)来了解一个演员的存在。 > 解决方法之一: DeatchWatch:创建另一个参与者调用getContext()。手表(ActorWatch的ActorRef);并检查是否接收到终止的消息。这只能用于已创建的参与者。 1,2表示存在参与者和3个监视器。我想知道这三个应用程序的用例以及它们对actors邮箱和功能的影响,以
-
我有哪些安装蟒蛇阿尔法的选项
与我能安装阿尔法版或测试版的Python密切相关吗?但这个问题是关于康达锻造中的特定版本。如果Python版本(例如3.10.0b1)可以通过 https://www.python.org/download/pre-releases/ 下载,但还没有在主蟒蛇或任何其他conda频道中下载,那么我使用它的最佳选择是什么? 在康达锻造厂打开一个问题 在环境中运行python安装程序的通用conda安装