《拼多多2023春招》专题
-
 2023春招-面试-杉树科技-数据分析师
2023春招-面试-杉树科技-数据分析师公司:杉树科技 岗位:数据分析师 形式:视频面试 视频面试平台:腾讯会议 面试官:数据分析师、HR 时长:25分钟 流程: 数据分析师(16分钟) 1、自我介绍 2、具体描述一下之前的实习经历,特别是数据分析这一块,比如遇到了哪些问题、有什么分析逻辑、如何去解决问题。 3、深挖项目:在这些工作中有没有得到什么有意思的结论? 4、继续深挖项目。 5、对机器学习大概有一个什么程度的了解? 6、解释一下
-
 2023春招实习面经汇总(已接阿里offer)
2023春招实习面经汇总(已接阿里offer)个人情况: 普通985计算机大三,有一点竞赛和科研但都非常一般,工程项目几乎全是学校的Toy project(基本所有面试官都问我为什么会投这个岗)。没为找工做任何准备(3.12才临时决定要试试看,3.13就投了几百份简历了),没背八股(实在背不进去),全靠以前专业课还没忘光的知识硬答。 素质、智商、性格、图表测试全部乱选(10分钟填完120分钟的卷子),笔试上机除了腾讯一题完全没思路0分外全满分
-
 2023届春招 京东-Java-第8批笔试凉经
2023届春招 京东-Java-第8批笔试凉经这个笔试鼠人拖了两次了,这是第三次不得不做了。 考试时间2h,从晚上7点到9点,在牛客考试平台。 总分100分,题型 ,20道单选,40分,3道编程题,分值分别为15分,20分,25分。 单选题考察范围很广,操作系统,linux命令,sql语句,java基础,集合,多线程。鼠人好多只能蒙。 编程题1:判断两个正整数x和y,能否有两个正整数m,n满足x + m * n = y;比较简单,鼠人a出来了
-
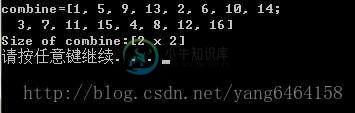 OpenCV实现多图像拼接成一张大图
OpenCV实现多图像拼接成一张大图本文向大家介绍OpenCV实现多图像拼接成一张大图,包括了OpenCV实现多图像拼接成一张大图的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了OpenCV实现多图像拼接成大图的具体代码,供大家参考,具体内容如下 开始尝试merge函数,具体如下: 定义四个矩阵A,B,C,D。得到矩阵combine。 结果如下: 显然,不是我们需要的结果。 尝试hconcat和vconcat函数,这两
-
 【春招】多益网络用户研究分析师-笔试
【春招】多益网络用户研究分析师-笔试楼主大四,数据科学与大数据技术专业,目前找工作中,岗位数据分析,除了一份简历笔试什么都没准备反正。 虽然有过一段数分实习,但这确实是楼主第一次做笔试题,同时对游戏公司不太感兴趣,看了友友分享的帖子,这家公司也emm...所以这次笔试就当长一下见识吧,记录一下需要的友友可以看看。 笔试分为三部分:综合选择、费米估算、业务问答。 综合选择:感觉全是统计学的知识,正态、分布、计算反正就是统计学的,楼主大
-
 校招如何准备ToB面试?拼多多高级产品经理带你细细梳理
校招如何准备ToB面试?拼多多高级产品经理带你细细梳理本文为产品/运营ToB求职经验分享直播课的完整复盘。 上周日我们特意邀请了前拼多多产品经理橙子老师围绕ToB产品为主题,分别以B端产品、B端产品的发展&方向和如何准备B端产品面试三个部分为大家答疑分享。 直播课复盘 什么是b端产品? B端产品,比如智齿科技是客服行业的一个独角兽明星企业,它主要提供一些客服行业的系统的解决方案,是hr系统的比较好的一个平台,拼多多后台是给商家进行供应链管理和销售管理
-
春云流处理器 单输入多行输出
我一直在尝试从 kafka 流式传输我的 json 事件,将其展平,然后使用 Spring Cloud 流将其推送回另一个主题。 输入: 压平工艺: 仅产生: 我的问题是怎么让它变成这样 所以我可以像我所做的那样推回残缺的 JSONObject 而不是单个 JSONArray? 尽管如此,Spring Cloud Stream输出只是一个单独的事件,不适合我上面的案例,无法为Kafka生成3个事件
-
 【华为OD机试2023】去除多余空格(Python)
【华为OD机试2023】去除多余空格(Python)题目描述: 去除文本多余空格,但不去除配对单引号之间的多余空格。给出关键词的起始和结束下标,去除多余空格后刷新关键词的起始和结束下标。 条件约束: 1,不考虑关键词起始和结束位置为空格的场景; 2,单词的的开始和结束下标保证涵盖一个完整的单词,即一个坐标对开始和结束下标之间不会有多余的空格; 3,如果有单引号,则用例保证单引号成对出现; 4,关键词可能会重复; 5,文本字符长度length取值范围
-
多对多表内多对多
问题内容: 我有一个包含 产品* 列表的表 订单 。对于与特定订单相对应的每个 产品 ,我需要存储一个 地址 列表,在该 地址 中应将单个产品(每个订单基于每个产品)发送到 * 所以我有这张表,在 订单 和 产品 上有很多很多,我需要的是将上表中的每个条目映射到 地址 列表。所以我需要像 并将上表中的条目映射到地址列表,我需要上述PK和地址ID(我的地址表的主键)上的多对多表 这里PK_Order
-
 【前端校招面经】快手2023春招前端面经
【前端校招面经】快手2023春招前端面经base: bj 岗位: 前端 业务: 快手电商 背景: 这次是上一次电商一面后的二面 自我介绍 过往项目经历 讲讲你实现过的 React 组件 讲一讲你在过往实习经历里面, 最让你有成就感的事情是什么 如何衡量前端性能 前端页面如何排查 bug 事件循环: 看代码说结果 代码题: 获取一个数组中前 n 个最大的值, 你能想到几种方法 如果大数组的 length < n, 则递归处理小的子数组 反
-
从Pyspark中的多个目录读取拼花文件
我需要从不是父目录或子目录的多个路径读取拼花地板文件。 例如, 从dir1\u 1和dir1\u 2读取拼花文件 现在,我正在读取每个目录并使用“unionAll”合并数据帧。有没有一种方法可以不使用unionAll从dir1\u 2和dir2\u 1读取拼花地板文件,或者有没有什么奇特的方法可以使用unionAll 谢谢
-
sqlalchemy多态多对多
问题内容: 我正在寻找以下列方式属于父类的对象的列表: SQLAlchemy examples文件夹具有简单的多对一关系,在我的示例中,类B和C是A的“父”类(而不是相反),但是我一生都无法解决如何将其逆转为一对多,然后添加双向关系以使其变为多对多。 谁能帮我这个忙吗? 问题答案: 这有点痛苦,并且显然需要更多的抛光,但是就像这样:
-
3.6 多态多对多
还是就这之前标签的例子,但是为了不破坏之前的代码,这回新建一个scopeManyToMany.ts文件。代码如下。 scope 里面指定的值, 就是在连接表创建数据的时候,会自动把里面设定好的字段填充好,并且查询的时候会自动把这个条件当做 where 的一项,所以这样我们就能做出区分了。 import Sequelize from 'sequelize'; const sequelize = n
-
多对多
多对多关联模型 满足条件:一个学生可以选择多个课程,一个课程也可以被多个学生选择 示例: student 学生表 class 课程表 student_has_class 中间表 >[danger] 多对多,需要借助第三个中间表,中间表包含了2个外键,分别是两个表的主键 我们假设有这样的一个场景,文章(Post)可以有多个标签(Tag),同样,一个Tag也可以对应多个Post,我们需要一张关联表Po
-
春季批处理csv:向csv添加多个标头
问题内容: 如何在csv中编写多头标头,以便第二个标头值应来自数据库 //预期的输出 //以下是用于弹簧批处理写入csv的代码段 问题答案: 您可以在中执行查询,并将结果附加到标题的第一行。