《regex》专题
-
C#Regex表示可能被引号包围的单词
例如,假设我的模式是单词“hello”,我创建了这个正则表达式: 但这并没有考虑到这个词必须同时有开始括号和结束括号才能作为匹配词。例如,如果我的搜索字符串是: 我想要的是有以下4个匹配-,, 具体地说,第二匹配包括圆括号,但是第三和第四匹配不包括任何圆括号,因为它们不在"你好"的开头和结尾。 我可以使用什么样的正则表达式来实现这一点?
-
regex-将xml标签后的第一个字母大写
我正在尝试使用NotepadRegex特性将xml文件中所有标记的首字母改为大写。大概是这样的: 和 我跟随了一些其他的贴子,在这里,用户想要更改标签中的值。大概是这样的: 解决办法是: 查找:
-
使用regex获取所有js hrefs
使用Jmeter的正则表达式提取器,我试图从一个html文档中获取仅与javascript相关的所有链接或路径--即包含“.js”子字符串的hrefs。我使用了next regex表达式,但它也是get“.css”链接: 下面是html片段的相关示例: 你能帮我用右正则表达式吗?它只得到“.js”链接,而不得到包含“.css”/“svg”等的其他链接?
-
Regex用于分析数据库列,如JDBC ResultSet
我正在使用JDBC从查询结果中获取列。 例如: 我想在运行查询之前解析它们。本质上,我希望为列标签创建一个数组,该数组将与resultSet所期望的值相匹配。get**方法。出于说明的目的,我想用这个替换上面的循环,并得到相同的结果: 这看起来很简单。我可以用一个简单的正则表达式解析我的语句,该正则表达式接受SELECT和from之间的字符串,使用列分隔符创建组,并从组中构建arrayOf列。但是
-
如何在Regex中捕获多个组?
-
Regex允许使用“-”和“_”的小写字母数字,但不将“-_”包含在一起
我想使用regex检查一个字符串验证,例如,它应该包含和的小写aphanumberic,但不仅仅包含和 这是我的尝试 但我想说明,当或仅单独运行时不应允许
-
REGEX匹配器未替换backslah
匹配器中的函数忽略了带有双反斜杠的转义字符。我想把两行替换成一行\n按原样分开。这是我的代码: 输出: Lorem ipsum dolor sit amet,\nConsectetur adipiscing elit sed do eusmod tempor incidunt ut\nlabore et dolore magna aliqua Lorem ipsum dolor sit amet,
-
Java使用regex[closed]获取字符串最后一个方括号之间的文本
我需要提取字符串最后括号之间的文本。这是看起来的样子: 我需要 我试过正则表达式,但我不能使它工作。我将非常感谢一些关于获得正则表达式和子字符串的帮助。非常感谢
-
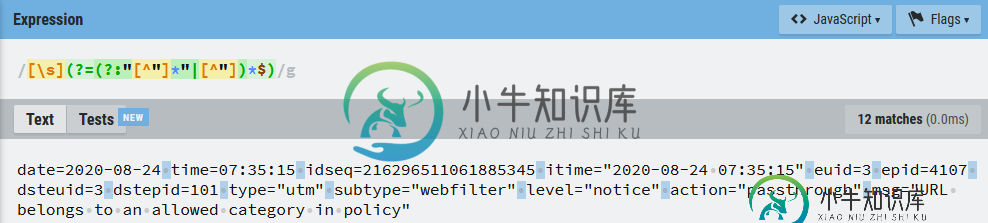 记事本正则表达式替换选择的所有文本。在RegExr中工作
记事本正则表达式替换选择的所有文本。在RegExr中工作我正在尝试用逗号替换日志文件中的所有空格(将其转换为CSV格式)。但是,有些日志条目有我不想替换的空格。这些条目以引号为界。我查看了几个示例,并得出了以下代码,这些代码似乎适用于RegExr.com和regex101.com. 但是,当我对该表达式执行查找/替换时,它会正确运行,直到它用空格打到第一个引号,然后选择文件的全部内容。 示例日志文件条目: 期望的结果: 编辑:经过多次测试,似乎只有一行
-
如何解决模式上的声纳关键问题。编译(regex,Pattern.CASE_INSENSITIVE);
使用代码时,我遇到严重的声纳问题“使用正则表达式对安全敏感” 有人能帮忙解决这个问题吗?对此有什么替代方案吗?
-
Spring Cloud Contract在regex元素的响应负载中返回“cursor”
我有一个基于java的服务作为提供者,一个节点JS应用程序作为使用者。
-
java中提取字符串中连续重复字符的REGEX
示例: 1)“aaabbaa”:b和a 2)“aabbaa”:a和b和a 3)“abba”:b 我尝试的代码: String str=“aabbbbcccd”; Pattern p=Pattern.compile(“(\w){2}”); 匹配器m=p.Matcher(str); 当(m.find()) { system.out.println(M.group(1)); } 输出: A B B C
-
奇怪的错误-std :: regex仅匹配前两个字符串
问题内容: 今天,我在应用程序中遇到了奇怪的错误。我已经测试了2个小时,但没有找到解决方案。也许您可以帮助我解决这个问题。所以这里是: 输出: 似乎该模式在第二个元素之后被丢弃了-不管我选择什么顺序(我试图交换它们,因为我认为数字会导致此错误-但事实并非如此)。现在我不知道发生了什么。 我正在使用gcc版本4.6.3(Debian 4.6.3-1)。 问题答案: 正则表达式库大多数尚未在libst
-
RegEx匹配XHTML自包含标签以外的打开标签
问题内容: 我需要匹配所有这些开始标签: 但不是这些: 我想出了这个,想确保我做对了。我只是捕捉到。 我相信它说: 找到一个小于,然后 查找(并捕获)az一次或多次,然后 找到零个或多个空格,然后 找到零次或多次贪婪的字符,除了,然后 寻找大于 我有那个权利吗?更重要的是,您怎么看? 问题答案: 尽管只有正则表达式的任意 HTML是不可能的,但有时使用它们来解析有限的已知 HTML集合是适当的。
-
regexp中是否有一个非(!)运算符?
问题内容: 我需要从给定的字符串中删除所有字符,除了剩下的几个字符。如何用regexp做到这一点? 简单测试:不应删除character [1,a,],而应从字符串“ asdf123 *”中删除所有其他字符。 问题答案: 集合中有^。 您应该能够执行以下操作: 完整样本: