
记事本正则表达式替换选择的所有文本。在RegExr中工作

我正在尝试用逗号替换日志文件中的所有空格(将其转换为CSV格式)。但是,有些日志条目有我不想替换的空格。这些条目以引号为界。我查看了几个示例,并得出了以下代码,这些代码似乎适用于RegExr.com和regex101.com.
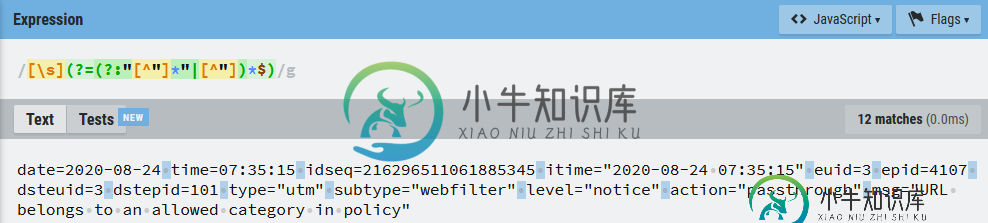
[\s](?=(?:"[^"]*"|[^"])*$)
但是,当我对该表达式执行查找/替换时,它会正确运行,直到它用空格打到第一个引号,然后选择文件的全部内容。
示例日志文件条目:
date=2020-08-24 time=07:35:15 idseq=216296511061885345 itime="2020-08-24 07:35:15" euid=3 epid=4107 dsteuid=3 dstepid=101 type="utm" subtype="webfilter" level="notice" action="passthrough" msg="URL belongs to an allowed category in policy"
期望的结果:
date=2020-08-24,time=07:35:15,idseq=216296511061885345,itime="2020-08-24 07:35:15",euid=3,epid=4107,dsteuid=3,dstepid=101,type="utm",subtype="webfilter",level="notice",action="passthrough",msg="URL belongs to an allowed category in policy"
编辑:经过多次测试,似乎只有一行,替换有效。但是,如果您有多行,它会用替换字符(在我的例子中,逗号)替换所有行。
共有2个答案

虽然很长,但如果您有一个已知的值列表,您可以简单地将它们用作替换键
-
< li >跳过第一个值,因为它不应以< code >,为前缀 < li >必须捕获标签周围的< code> 和< code>=,以便更加确定,(尽管这不能保证它不会在< code>msg字段中找到子字符串)
's/ (time|idseq|itime|euid|epid|dsteuid|dstepid|type|subtype|level|action|msg)=/,$1='
Python中的示例
import re
>>> source = '''date=2020-08-24 time=07:35:15 idseq=216296511061885345 itime="2020-08-24 07:35:15" euid=3 epid=4107 dsteuid=3 dstepid=101 type="utm" subtype="webfilter" level="notice" action="passthrough" msg="URL belongs to an allowed category in policy"'''
>>> regex = ''' (time|idseq|itime|euid|epid|dsteuid|dstepid|type|subtype|level|action|msg)='''
>>> print(re.sub(regex, r",\1=", source)) # raw string to prevent loss of 1
date=2020-08-24,time=07:35:15,idseq=216296511061885345,itime="2020-08-24 07:35:15",euid=3,epid=4107,dsteuid=3,dstepid=101,type="utm",subtype="webfilter",level="notice",action="passthrough",msg="URL belongs to an allowed category in policy"
您可能会发现一些值包含\“或类似内容,这可能会破坏非常小心的正则表达式!
另请注意,对于CSV,您可能希望完全替换字段名称

- CtrlH
- 查找内容:
“[^”\r\n]“(*跳过)(*失败)|\h - 替换为:
, - CHECK环绕
- CHECK正则表达式
- 替换所有
解释:
"[^"\r\n]+" # everything between quotes
(*SKIP)(*FAIL) # kip and fail the match
| # OR
\h+ # 1 or more horizontal spaces
截图(之前):
截图(之后):
-
问题内容: 在2个标签之间选择所有文本的最佳方法是什么-例如:页面上所有“ pre”标签之间的文本。 问题答案: 您可以使用,(用所需的任何文本替换pre)并提取第一组(对于更具体的说明,请指定一种语言),但这只是假设您拥有非常简单且有效的HTML。 正如其他评论者所建议的那样,如果您要执行复杂的操作,请使用HTML解析器。
-
例如,我有一些数据的列表,这些数据是这种格式的 单词1单词2单词3 word4 word5 word6 word7 word8 word9 但是我想把它们都分开,这样每个单词都在新行中,这样它就会变成这样: 字1 文字2 字3 文字4 字5 字6 文字7 字8 文字9 单词之间的空格是完美的分隔符,可用于搜索 谢谢
-
我正试图用正则表达式从一个文件中删除一组文本。现在我有了一个< code >字符串中的文件内容,但是< code >匹配器找不到模式。示例文件是: 我需要找到以开头和以结尾的块,然后删除它们。这是我使用的最小代码。我使用的正则表达式是,它应该查找和模式从“\开始”开始,直到第一次出现“\结束{评论}”。我在记事本上工作。 然而,使用这个java代码,它找到了第一个' \begin '和最后一个'
-
使用管道分隔的文件。目前,我使用记事本查找和替换REGEX模式,它用第5和第6个之间的空字符串替换所有行。我正在尝试以编程方式执行此过程,但是。NET不支持。我尝试了一些向后查找实例,但似乎无法理解它。
-
我有一个字符串向量,如下所示:。出于某种原因,后面有随机/不同的数字,我正在尝试删除它们。使用正则表达式,我如何告诉R移除或替换后面的数字,所以我最终得到。我对Regex了解不多,所以如果有人不仅能提供代码,还能提供对代码的简要解释,我将非常感谢。谢了!
-
问题内容: 我有这个HTML: 我只需要匹配任何HTML标记之外的单词。我的意思是,如果我想匹配“简单”和“文本”,则只能从“这是简单的html文本”和最后一部分“文本”中获得结果- 结果将是“简单” 1匹配,“文本” 2火柴。有人可以帮我吗?我正在使用jQuery。 是我要匹配的单词(在这种情况下为“简单”) 是 我需要用来包装所有选定的单词(在此示例中为“简单”)。但是我只想包装 任何 HTM