《匹配》专题
-
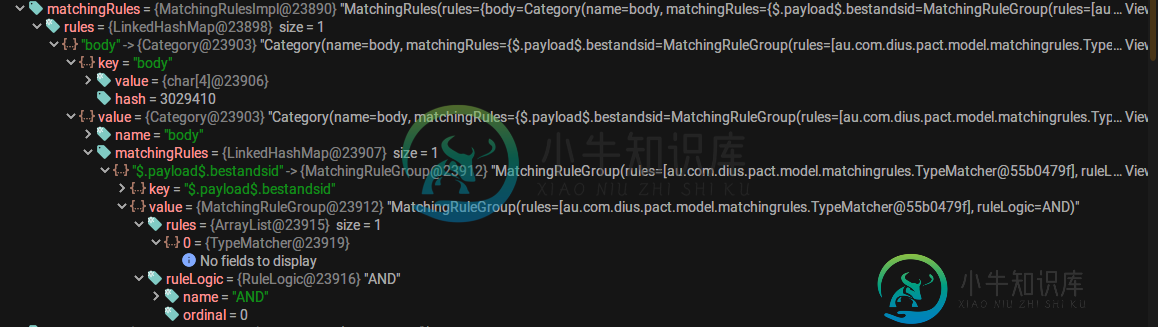 AMQ消息的V3.0合同中的stringType匹配器执行文字匹配而不是类型匹配
AMQ消息的V3.0合同中的stringType匹配器执行文字匹配而不是类型匹配我有一个使用stringType匹配文件名的协定。契约还指定了type上的匹配器,但当我在提供者端运行测试时,它会执行字面匹配。我在调试时包含了合同、发送的JSON和一个屏幕截图。我注意到TypeMatcher是在MatchingRuleGroup中初始化的,但它没有字段。我不确定这是否正确 我尝试了3种方案: > StringValue(“bestandSID”,“20190219_foo_20
-
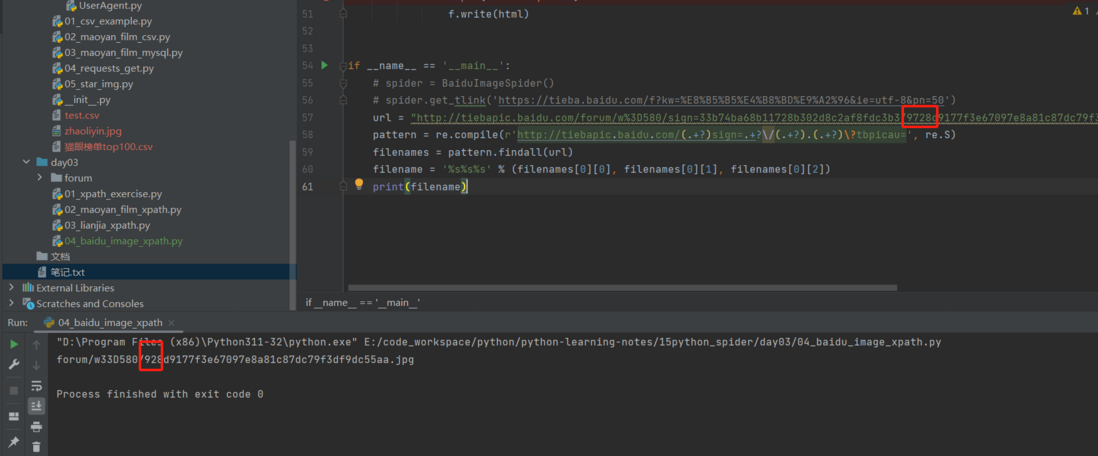 python 我是用的是分组非贪婪匹配 正则匹配,为什么匹配结果少了7?
python 我是用的是分组非贪婪匹配 正则匹配,为什么匹配结果少了7?python 正则匹配,为什么匹配结果少了7?我是用的是分组非贪婪匹配 代码如下: //输出结果: //期望输出结果: 为什么结果中928d9177f3e67097e8a81c87dc79f3df9dc55aa.jpg 少了7?
-
使用匹配器的分组方法时,“找不到匹配项”
问题内容: 我正在使用/ 来获取HTTP响应中的响应代码。返回1,但是尝试获取异常!知道为什么吗? 这是代码: 这是输出: 问题答案: 总是会创建一个新的匹配器,因此您需要再次致电。 尝试:
-
正则表达式匹配-为什么不匹配并返回None?
问题内容: 我不明白为什么这个简单的正则表达式匹配不返回匹配对象。它返回None我在做什么错? 我完全是newby(昨天开始),想编写一个小程序来搜索文件夹树中的某些文件,打开这些文件并在这些文件中找到某些行,然后将这些行打印到一个新文件中。为了完成第一步,我想匹配os.walk返回的文件名,并使用某种模式进行匹配。因此,现在我正在检查正则表达式的工作方式,并且据我所知,以下代码应该匹配,但是当我
-
使用typefirst,如何将匹配的用户输入视为匹配?
我正在为一个Wordpress插件项目做出贡献,该项目使用推特字体提前(和猎犬)和JQuery。 该插件包含有关组织组的信息。当用户键入他们希望添加到数据库中的组的名称时,类型前进/猎犬会根据现有组提供建议(弹出)。如果用户使用鼠标或箭头键从弹出窗口中的建议中选择一个现有的组,或者当显示所需的自动完成组名称但用户仅部分完成时按下选项卡,则选择匹配并为该组选择其余元素/字段从数据库中填充。这是工作所
-
Pact:如何匹配键与正则表达式匹配的对象?
我正在尝试编写一个pact消费者测试来匹配下面的响应。 每个schedule对象由与一个简单正则表达式匹配的未知数量的键组成。但是我没有看到一种方法可以使用正则表达式来匹配键,同时将值映射到一个简单的布尔值。 但这需要一个新的对象作为值,而不是一个基元类型。 有没有办法在pact-jvm中指定映射到基元值的不精确键?
-
javascript - js 匹配url正则,可匹配参数,要怎么修改?
/^(?=^.{3,255}$)(http(s)?:\/\/|ftp:\/\/)?(www\.)?[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(\.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+(:\d+)*(\/\w+\.\w+)*$/ 如何修改下这个正则 能匹配到地址栏上的参数,可有可无 匹配如http://www.baidu.com?params1=123&pa
-
Hamcrest Isnot匹配器与包装的自定义匹配器一起-描述不匹配不按预期工作
最近,我为jaxb生成的元素做了一个自定义匹配器,遇到了这样的场景: 先决条件: 我有一个自定义Matcher,它扩展了BaseMatcher,覆盖了方法describeTo和DescribeMatch(当然还有matches…) 我使用的是assertThat(actualObject,而不是MyMatcherStaticRunMethod(expectedObject)) 当断言失败时,结果是
-
根据值匹配数组
问题内容: 我正在使用以下代码来解析yaml并应将输出作为对象,并且该函数应更改数据结构并根据以下结构提供输出 这是我尝试过的方法,但是我不确定如何从yaml中获取的值 替换 函数运行器中 的硬代码值 与来自 这就是我尝试过的所有想法,该怎么做? 问题答案: 将runners对象的名称分配给名称的struct 字段,并使用与名称匹配的函数命令将命令列表附加到type字段: 操场上的工作代码
-
匹配任何unicode字母?
问题内容: 在.net中,您可以使用它来匹配任何字母,如何在Python中进行匹配?即,我想匹配任何大写,小写和带重音的字母。 问题答案: Python的模块尚不支持Unicode属性。但是您可以使用该标志编译正则表达式,然后字符类速记也将与Unicode字母匹配。 由于还将匹配数字,因此您需要从字符类中减去数字以及下划线: 将匹配任何Unicode字母。
-
Chrome扩展清单“匹配”
问题内容: 我正在尝试使用简单的Chrome扩展程序,但是在为数组提供值时遇到了问题。 当我尝试将此扩展程序加载到Chrome中时,收到以下消息: 无法从“ C:\ Users \ foo \ Desktop \ Extensions \ bar”加载扩展名。 “ content_scripts”的值无效。 我看不到我的值是什么“无效”。我想做的是匹配每个URL,以便我的扩展程序可以操纵它所运行的
-
字符串完全匹配
问题内容: 我有一个字符串,其中单词“ LOCAL”多次出现。我使用该函数搜索该单词,但它也返回另一个单词“ Locally”。我如何准确匹配“本地”一词? 问题答案: 对于这种事情,正则表达式非常有用: \ b基本上表示单词边界。可以是空格,标点符号等。 编辑评论: 显然,如果您不想忽略这种情况,则可以删除flags = re.IGNORECASE。
-
SQL中的匹配算法
问题内容: 我的数据库中有下表。 每个人在工作中均按不同的属性/标准(称为“ prop”)进行排名,而绩效则称为“等级”。如示例所示,该表包含(name,prop)的多个值。我想从某些要求中获得最佳人选。例如,我需要具有和的候选人。然后,我们必须能够按候选人的排名对他们进行排序,以获得最佳候选人。 编辑:每个人都必须满足所有要求 如何在SQL中执行此操作? 问题答案:
-
Kibana查询完全匹配
问题内容: 我想知道如何查询字段以完全匹配字符串。 我实际上正在尝试这样查询: 会返回以开头的所有字符串。 问题答案: 我遇到了类似的问题,而ifound修复了“ .raw”-在您的示例中,请尝试
-
拆分pcregrep多行匹配
TL;dr:我如何用pcregrep来拆分每一个多行匹配? 长版本:我有一些文件,有些行以(小写)字符开头,有些以数字或特殊字符开头。如果我至少有两行彼此相邻,以小写字母开头,我希望在我的输出中这样做。但是,我希望每个发现都被分隔/拆分,而不是相互附加。这是正则表达式: 所以,如果我提供这样的文件: 给出的结果是 然而,我想要的是这个: 这可能吗和/或我必须开始使用Python(或类似)?即使建议