《慢查询》专题
-
较慢的mongodb查询大型文档
我有一个只有2个文档的mongodb数据库。两者具有相同的结构: 小文档在消息中有0个对象,大文档有1000个。我数了数这两份文件上的标牌:小:28000大:450000 我使用nodeJS和常规mongodb驱动程序访问文档,并且我将索引设置为“general.sid”。 现在我要他们的将军提供文件。而且这两个文档的时间差别很大!我接收文档,进行一些计算并更新文档。 我打印接收和更新文档之前和之
-
MYSQL查询执行速度非常慢
问题内容: 我已经开发了一个用户批量上传模块。有两种情况,当数据库有零条记录时,我批量上传了20000条记录。大约需要5个小时。但是,当数据库已经有大约30 000条记录时,上传速度将非常缓慢。上载2万条记录大约需要11个小时。我只是通过fgetcsv方法读取CSV文件。 下面是运行的查询。(我正在使用Yii框架) 如果存在,请更新用户: 如果用户不存在,请插入新记录。 表引擎类型为MYISAM。
-
使用IN的postgres查询非常慢
问题内容: 我有一个表,其中有一个索引(A列,B列)。我正在运行一个查询,如下所示: 这个查询很慢!该计划如下所示: Postgres似乎没有一次对5000个值进行一次索引扫描,而是一次对5000个值进行了一次索引扫描,这解释了为什么查询如此缓慢。 实际上,这样做是更快的方法: 获取结果,然后在应用程序内的B列上进行过滤(python)。 我真的更希望结果已经由Postgres在合理的运行时间下进
-
JDBC自动查询变得非常慢
问题内容: 我正在维护一个通过JDBC创建Oracle DB的应用程序。从今天开始,此查询: 由于某些oracle内部机制,开始变得非常缓慢,因为我的所有分支似乎都一样。 有人知道一个可能的原因以及如何面对吗? 问候,努齐奥 问题答案: 数据字典或固定对象统计信息可能很旧,请尝试重新收集它们: 即使这样,也不一定能收集 所有 系统对象的统计信息。有些对象(例如)必须手动收集。尽管这是一个罕见的数据
-
使用Left Join的MySQL查询太慢
问题内容: 询问: 两个表都有8k记录,但是为什么它却很慢,需要2-3分钟,有时还要多一些? OMG,该查询使mysql服务器停机。将在一秒钟内回复你们人民:( 建议所有为这些索引编制索引的人都是正确的。是的,我写的查询既傻又马车。感谢纠正我。 问题答案: 还考虑对表建立索引。我们正在100万以上的记录表上运行多个左联接,这些联接不需要一两秒钟就能返回结果。
-
sp_executesql导致我的查询非常慢
问题内容: 在数据库表上运行sp_executesql时遇到一些问题。我使用的是ORM(NHibernate),在这种情况下,该ORM(NHibernate)生成查询一个表的SQL查询。该表中大约有700万条记录,并且已被高度索引。 当我运行没有sp_executesql的ORM吐出的查询时,它运行非常快,并且探查器显示它具有85次读取。当我使用sp_executesql运行相同的查询时,它的读取
-
使用where子句的查询缓慢
问题内容: 我有以下只需1秒即可执行的sql查询: 但是我需要一个结果集来获取比率大于0的结果。因此,当我将查询更改为此时,需要7分钟的时间来执行: 为什么这会使查询时间从1秒增加到7分钟?由于b表很大,因此我什至尝试使用CTE,但这也没有提高性能。我认为使用CTE可以从中筛选出较小的一组值,因此应该更快一些,但这无济于事: 我不能包括执行计划,因为除了查询之外,我没有对数据库的权限。 问题答案:
-
Spring NamedParameterJdbcTemplate查询的性能非常慢
我正在处理一个需要JDBC调用Oracle数据库的项目。我已经设置了UCP池化来与SpringJDBC一起工作。我有一个相当简单的查询,我正在执行如下... 我的java代码来设置这个查询看起来像下面... 只要数组中只有一个id,这一切都可以正常运行。当我添加第二个ID时,查询需要将近5分钟的时间运行。如果我获取精确的查询并在SQLDeveloper中执行它,则需要.093秒。 我的代码或配置一
-
场景示例 - MySQL慢查询日志
MySQL 有多种日志可以记录,常见的有 error log、slow log、general log、bin log 等。其中 slow log 作为性能监控和优化的入手点,最为首要。本节即讨论如何用 logstash 处理 slow log。至于 general log,格式处理基本类似,不过由于 general 量级比 slow 大得多,推荐采用 packetbeat 协议解析的方式更高效的
-
elasticsearch - ES查询速度慢的问题?
现在有三台ES服务器,索引里大概有7000条数据,每条数据是内容放到txt中大概300kb以上,按某个查询条件查询的结果数量是4000多条数据。当size设置成9999的时候,需要查询30秒以上,这是为什么呢,有没有优化方案。
-
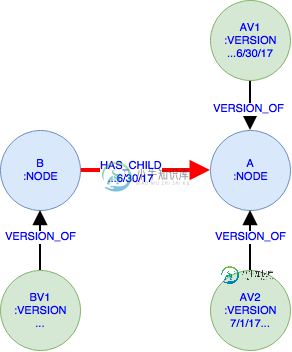 Neo4j Cypher查询查找未连接的节点太慢
Neo4j Cypher查询查找未连接的节点太慢假设我们有下面的Neo4j模式(简化了,但它显示了重要的一点)。有两种类型的节点和<代码>版本s通过关系的s可以通过关系连接。同样,这些关系有两个属性和,表示有效时间跨度-其中一个或两个可以(在Neo4j术语中不存在)表示无限。 编辑:节点和关系的有效性日期是独立的(尽管示例巧合地显示它们是对齐的)。 该示例显示了两个
-
MySQL 开启慢查询日志的方法
本文向大家介绍MySQL 开启慢查询日志的方法,包括了MySQL 开启慢查询日志的方法的使用技巧和注意事项,需要的朋友参考一下 1.1 简介 开启慢查询日志,可以让MySQL记录下查询超过指定时间的语句,通过定位分析性能的瓶颈,才能更好的优化数据库系统的性能。 1.2 登录数据库查看 因为没有设置设置密码,有密码的在 mysql –uroot –p 接密码 1.2.1 进入MySql 查询是否开了
-
超级慢查询''我做错了什么?
问题内容: 诸位令人惊奇。在过去的两天里,我已经在这里发布了两次-一个新用户- 我对帮助感到震惊。因此,我认为我会采用软件中最慢的查询,看看是否有人可以帮助我加快查询速度。我使用此查询作为视图,因此务必要快(不是!),这一点很重要。 首先,我有一个联系人表,用于存储我公司的客户。该表中有一个JobTitle列,其中包含一个在Contacts_Def_JobFunctions表中定义的ID。还有一个
-
与SQL相比,Hibernate JPQL查询非常慢
已定义查询的Dao: 来自Hibernate调试日志的SQL: 当我在数据库上执行这个查询时,大约需要15ms,从代码上执行大约需要1.5秒。我在代码中注释掉了这一行,滞后消失了,所以问题肯定是这个jpql选择。 数据库连接配置: 更新1: debug.log:
-
一般处理流程 - 获取慢查询
SLOWLOG GET 10 结果为查询ID、发生时间、运行时长和原命令 默认10毫秒,默认只保留最后的128条。单线程的模型下,一个请求占掉10毫秒是件大事情,注意设置和显示的单位为微秒,注意这个时间是不包含网络延迟的。 slowlog get 获取慢查询日志 slowlog len 获取慢查询日志条数 slowlog reset 清空慢查询