《网关》专题
-
 网络爬虫是什么
网络爬虫是什么主要内容:认识爬虫,爬虫分类,爬虫应用,爬虫是一把双刃剑,为什么用Python做爬虫,编写爬虫的流程网络爬虫又称网络蜘蛛、网络机器人,它是一种按照一定的规则自动浏览、检索网页信息的程序或者脚本。网络爬虫能够自动请求网页,并将所需要的数据抓取下来。通过对抓取的数据进行处理,从而提取出有价值的信息。 认识爬虫 我们所熟悉的一系列搜索引擎都是大型的网络爬虫,比如百度、搜狗、360浏览器、谷歌搜索等等。每个搜索引擎都拥有自己的爬虫程序,比如 360 浏览器的爬虫称作 360Spider,搜狗的爬虫叫做
-
空手道网络能力
我们一直在围绕空手道netty的模拟功能进行一些概念验证工作,我们想知道以下方面的潜在未来功能: 在服务器启动后动态添加/删除模拟功能(例如,将模拟功能更紧密地耦合到单个测试用例) 在启动时利用多个模拟功能(或嵌套功能) 谢了麦克
-
 支柱2 磁贴 网豆
支柱2 磁贴 网豆我是Struts2的初学者,并且已经成功实现了简单的示例。 我对瓷砖有意见 我从这个网站推荐 http://www.dzone.com/tutorials/java/struts-2/struts-2-example/struts-2-tiles-example-1.html 我的文件和上面提到的那个网站上的完全一样 我使用的是:Netbeans ide 7.3、struts 2、glassfis
-
Hyperledger Fabric:物联网用例
用例:一个智能家居,它从里面的所有传感器收集原始数据,处理它们,并从中提取高级信息。房子的主人可能想与其他人分享这些信息,如医生、家人、朋友...因此,我试图找出处理这些数据的访问权限的最佳方式。现在,所有的信息都被仔细地加密并存储在数据库中(不可信),只有拥有正确密钥的人才能正确地解密这些数据。 我的想法是:我想使用Hyperledger Fabric来存储和管理对这些文件的访问权限,并存储所收
-
 网易传媒一面 (70min)
网易传媒一面 (70min)有点听不清楚面试官讲话,后面搞了半天,面试官好像也有点不耐烦,呜呜呜,大概面了 70 min 顺序乱排的哦 1. 自我介绍 2. flex 布局,三个值代表什么,光用 flex 会不会有什么问题? 3. 场景:左边固定宽,右边自适应,几种方案 4. 水平垂直居中? 5. js数据类型? 6. cmj 和 esm 的异同? 7. 响应式怎么做? 8. 输出题: const obj = { a: 2,
-
 招银网络二面40min
招银网络二面40min后续:16号约HR面了 许愿HR面 1、项目20分钟 2、如何做依赖隔离 3、用到哪些设计模式 4、微信扫码登录全流程(问得非常详细,直至不会。。) 5、长轮询和短轮询 6、sleep(0)的作用 7、http状态码 8、消息队列浅问 #招商银行##银行##Java开发##面经#
-
 微派网络笔试9.16
微派网络笔试9.1610道选择题2道编程 编程题: 1、分母异位词 242. 有效的字母异位词 - 力扣(LeetCode) 2、单词拆分 139. 单词拆分 - 力扣(LeetCode) 本来是核心代码模式,但是那个模板是别的题的,得重写自己写过。 #微派##武汉微派#
-
 招银网络一二面
招银网络一二面一面(25min)主要问基础 0.自我介绍 1.ArrayList和LinkedList(区别,优缺点,扩容等) 2.HashMap(hash冲突,扩容,与concurrentHashMap区别) 3.new String("ab")创建了几个对象 4.StringBuilder和StringBuffer区别,举个使用场景的例子 5.jvm内存区域有哪几块,存放什么东西 6.垃圾回收算法有哪些 7
-
 2022.09.19招银网络面试
2022.09.19招银网络面试面试时间30分钟 自我介绍以后,首先简单的聊了一下天,还学过哪些语言,为什么学习了Java,怎么接触到Java的,在学校有没有选修过Java的相关课程,你认为Java语言相较于其他语言有什么优势(我答了一个Java的跨平台优势和Spring框架的开发优势)。 你了解多态么?(第一个问题就没大想好咋回答,啰里吧嗦说了一堆,还举了Service的例子。但是面试官听完之后还是表示了对我的鼓励,说我能明白
-
 网易Java二面面经
网易Java二面面经网易互联网 9/19 45min 实习项目+深挖15min 怎么处理数据库多版本接入问题 Hbase MySQL事务隔离级别+实现 间隙锁 Mysql回表 聚簇索引、非聚簇索引 算法题:最长公共子序列,返回长度+最长序列 有点kpi的味道emmmm 但是还是希望能通过,今年太难了 #网易##网易面经##秋招##面经##网易互联网#
-
 星网锐捷C++面经
星网锐捷C++面经9.14投递简历 再官网投递的,直接发送简历到邮箱,没有网申通道 9.15hr面(5min) 就是个人情况的了解,意向工资等问题,面完之后发测评和笔试,同时面试和笔试是并行进行的 9.16 笔试测评 不知道是我做的时间比较晚的问题还是啥,笔试难度不小,20还是30个选择题好像,但是不是很简单。 4个编程题, 第一题签到题,第二第三是力扣的hard题,记得是原题, 第四题是用英文出的题目 9.17
-
 招银网络Java面经
招银网络Java面经8.25 投递 8.26 素质测评 9.5 技术测评 9.26 一面 1.用过哪些集合类,HashMap讲一下 2.垃圾回收算法 3.怎么判断对象是否需要回收 4.栈和队列的区别 5.算法题:两个栈实现队列 6.线程池作用,参数 7.线程池线程存在的方式,销毁时间 8.并发量特别大,需要对数据库做什么优化,分库分表了解吗 9.行锁和表锁的区别,SQL什么关键字会加锁 10.乐观锁和悲观锁 11.反
-
 招银网络java一面
招银网络java一面Java的限定符有哪些?默认和protected访问权限 创建线程的方式 线程池的参数 Synchronized用法 设计模式:普通工厂和抽象工厂的区别,观察者模式怎么实现的,单例模式的双重锁检测怎么实现的 hashmap底层数据结构?红黑树怎么限制为平衡二叉树 Redis持久化方式 Redis怎么实现分布式锁 @bean与@Compent的区别 @SpringBootApplication注解
-
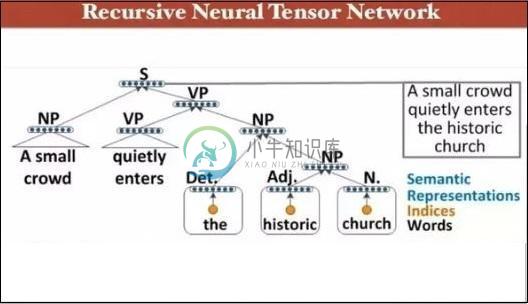 PyTorch递归神经网络
PyTorch递归神经网络深度神经网络具有独特的功能,可以帮助机器学习突破自然语言的过程。 据观察,这些模型中的大多数将语言视为单词或字符的平坦序列,并使用一种称为递归神经网络或RNN的模型。 许多研究人员得出的结论是,对于短语的分层树,语言最容易被理解。 此类型包含在考虑特定结构的递归神经网络中。 PyTorch有一个特定的功能,有助于使这些复杂的自然语言处理模型更容易。 它是一个功能齐全的框架,适用于各种深度学习,并为
-
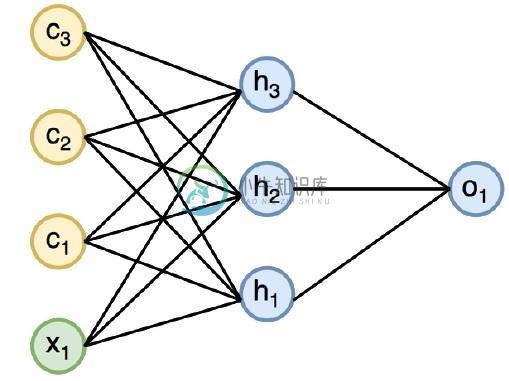 PyTorch递归神经网络
PyTorch递归神经网络递归神经网络是一种遵循顺序方法的深度学习导向算法。在神经网络中,我们总是假设每个输入和输出都独立于所有其他层。这些类型的神经网络被称为循环,因为它们以顺序方式执行数学计算,完成一个接一个的任务。 下图说明了循环神经网络的完整方法和工作 - 在上图中,,,和是包括一些隐藏输入值的输入,即输出的相应输出的,和。现在将专注于实现PyTorch,以在递归神经网络的帮助下创建正弦波。 在训练期间,将遵循模型