《基础组件》专题
-
C#基础之异步调用实例教程
本文向大家介绍C#基础之异步调用实例教程,包括了C#基础之异步调用实例教程的使用技巧和注意事项,需要的朋友参考一下 本文实例形式展示了C#中异步调用的实现方法,并对其原理进行了较为深入的分析,现以教程的方式分享给大家供大家参考之用。具体如下: 首先我们来看一个简单的例子: 小明在烧水,等水烧开以后,将开水灌入热水瓶,然后开始整理家务 小文在烧水,在烧水的过程中整理家务,等水烧开以后,放下手中的家务
-
C#基础之委托用法实例教程
本文向大家介绍C#基础之委托用法实例教程,包括了C#基础之委托用法实例教程的使用技巧和注意事项,需要的朋友参考一下 本文以实例形式简单介绍了C#中委托的用法,是深入学习C#程序设计所必须掌握的重要技巧。现以教程形式分享给大家供大家参考之用。具体如下: 首先,委托是C#中最为常见的内容。与类、枚举、结构、接口一样,委托也是一种类型。类是对象的抽象,而委托则可以看成是函数的抽象。一个委托代表了具有相同
-
当File.listFiles返回null时检索基础错误
问题内容: 根据javadoc的File.listFiles方法 如果此抽象路径名不表示目录,或者发生I / O错误,则返回null。 我知道我正在使用目录,但是已经收到结果,因此必须出现I / O错误。我对错误是什么非常感兴趣。 返回这样的结果时如何检索错误消息/代码? 问题答案: 使用(在Java 7+中),您将获得适当的例外。
-
Android蓝牙库FastBle的基础入门使用
本文向大家介绍Android蓝牙库FastBle的基础入门使用,包括了Android蓝牙库FastBle的基础入门使用的使用技巧和注意事项,需要的朋友参考一下 前言 最近在做物联网课设,过程中需要用到Android的蓝牙API,奈何原生的蓝牙API使用有点麻烦。于是上网搜索看有没有好用的Android蓝牙库,然后发现了这个宝贝,给大家分享一下。 FastBle VS 原生Android蓝牙API
-
Java开发基础日期类代码详解
本文向大家介绍Java开发基础日期类代码详解,包括了Java开发基础日期类代码详解的使用技巧和注意事项,需要的朋友参考一下 由于工作关系,很久没更新博客了,今天就给大家带来一篇Java实现获取指定月份的星期与日期对应关系的文章,好了,不多说,我们直接上代码: 一、日期工具类 二、测试类 三、测试结果 总结 本文通过代码示例向大家展示了日期工具类的几种用法,希望对大家学习Java有所帮助。 感兴趣的
-
MySQL数据库基础命令大全(收藏)
本文向大家介绍MySQL数据库基础命令大全(收藏),包括了MySQL数据库基础命令大全(收藏)的使用技巧和注意事项,需要的朋友参考一下 整理了一下mysql基础命令,分享一下 以上所述是小编给大家介绍的MySQL数据库基础命令大全,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对呐喊教程网站的支持!
-
Swift学习教程之SQLite的基础使用
本文向大家介绍Swift学习教程之SQLite的基础使用,包括了Swift学习教程之SQLite的基础使用的使用技巧和注意事项,需要的朋友参考一下 前言 在我们的日常开发中,经常会遇到用户断网或者网络较慢的情况,这样用户在一进入页面的时候会显示空白的页面,那么如何避免没网显示空白页面的尴尬呢?答案就是:先在网络好的时候缓存一部分数据,这样当下次网络情况不好的时候,至少用户可以先看到之前缓存的内容,
-
java基础学习笔记之类加载器
本文向大家介绍java基础学习笔记之类加载器,包括了java基础学习笔记之类加载器的使用技巧和注意事项,需要的朋友参考一下 类加载器 java类加载器就是在运行时在JVM中动态地加载所需的类,java类加载器基于三个机制:委托,可见,单一。 把classpath下的那些.class文件加载进内存,处理后成为字节码,这些工作是类加载器做的。 委托机制指的是将加载类的请求传递给父加载器,如果父加载器找
-
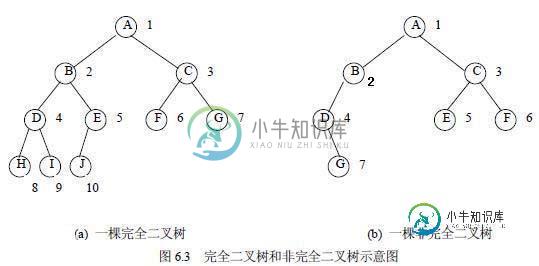 c语言 树的基础知识(必看篇)
c语言 树的基础知识(必看篇)本文向大家介绍c语言 树的基础知识(必看篇),包括了c语言 树的基础知识(必看篇)的使用技巧和注意事项,需要的朋友参考一下 第一、树的定义: 1、有且只有一个称为根的节点 2、有若干个互不相交的子树,这些子树本身也是一颗树 第二、专业术语: 树的深度:从根节点到最低层,节点的层数 ,称之为树的深度。 根节点是第一层 结点的层次:根节点为第一层,根节点的子节点为第2层,以此类推 叶子节点:
-
Java正则表达式基础入门知识
本文向大家介绍Java正则表达式基础入门知识,包括了Java正则表达式基础入门知识的使用技巧和注意事项,需要的朋友参考一下 众所周知,在程序开发中,难免会遇到需要匹配、查找、替换、判断字符串的情况发生,而这些情况有时又比较复杂,如果用纯编码方式解决,往往会浪费程序员的时间及精力。因此,学习及使用正则表达式,便成了解决这一矛盾的主要手段。 大家都知道,正则表达式是一种可以用于模式匹配和替换的规范,一
-
存在类型的理论基础是什么?
为可以转换为的东西定义类型包装。wiki提到,我们真正想要定义的是一种类型,比如 即一个真正的“存在”类型--我松散地认为这是说“数据构造函数接受实例存在的任何类型并包装它”。实际上,您可以编写一个GADT,如下所示: 我没有试过编译它,但它似乎应该可以工作。对我来说,GADT显然等同于我们想要编写的代码(2)。
-
Spark中Group By子句的基础实现SQL
Spark SQL中Group By子句的底层实现是什么?我知道Spark支持两种类型的分组操作,即GroupByKey和ReduceByKey。ReduceByKey是一种地图端reduce,与GroupByKey相比提供了更好的性能。 在我们的应用程序代码中,我们在Spark数据帧上使用Spark SQL,而不是直接创建RDD。所以,我有一个问题,Spark SQL中的GroupBy是否执行G
-
 在基础设施层使用依赖注入
在基础设施层使用依赖注入在ASP中创建示例项目时,我使用了四个层。net核心,如下所示 我还在启动中实现了依赖注入.cs我的API项目中。而且效果很好。 我有两个问题要问。 > < li> 可以在我的基础结构层而不是API层进行依赖注入吗?如果是,你能指导我怎么做吗? 如果我说错了纠正我,如果Asp.Net核心默认有依赖注入,那么我们就不需要Autofac(或者类似的第三方DI插件)。正确让我重新措辞这个问题。Asp核心
-
Android基础:在UI线程中运行代码
在UI线程中运行代码的观点中,以下两者之间有什么区别吗: 或 而且
-
在基础模型更改后更新JFace TreeViewer
我的视图中有一个树查看器,它从标准的Ecore编辑器中监听EMF模型,并用它做进一步的事情。我已经注册了一个选择监听器,它检查所选元素是否是树查看器需要作为输入的类型。因此,问题是,如果模型中有任何变化(例如,向现有元素添加新元素或新信息等),树查看器仅在用户更改选择时才显示更改后的模型,即单击任何模型元素等。 但是我需要做的是,如果底层模型发生变化,树查看器将直接得到通知,并显示新的模型元素,而