《一致性哈希》专题
-
哈希映射哈希码到内部表索引的转换
Hashmaps通常使用桶的内部数组(表)来实现。在通过键访问hashmap时,我们使用键类型特定(逻辑类型特定)的hash函数获得键的hashcode。然后我们需要将hashcode映射到实际的内部桶表索引。 有时,内部表可能会收缩和扩展,这取决于hashmap填充率。那么可能是散列码- 例如,我们的哈希函数返回32位无符号整数值 时刻A:内表容量为10000 时刻B:内工作台容量为100000
-
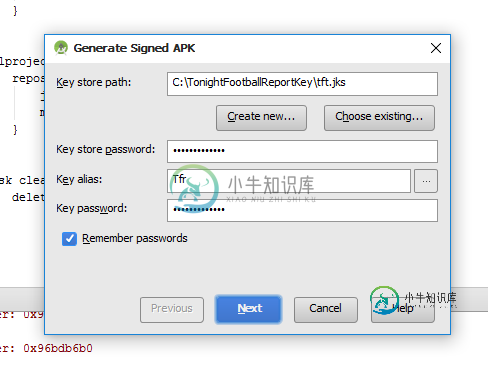 释放apk Facebook哈希键与生成的哈希键不同
释放apk Facebook哈希键与生成的哈希键不同我正在开发一款Android应用程序。在我的应用程序中,我集成了Facebook登录。我的facebook登录工作正常。但当我制作release apk并运行该应用程序并尝试登录Facebook时,它就不工作了。请看下面我的场景。 我生成如下的发布apk 然后我使用jks文件路径生成keyhash。 我得到了一个散列键,然后将其添加到开发人员配置文件设置中。 当我在我的设备上安装并运行apk并使用
-
在javascript中构建哈希表和完善的哈希函数
我正在使用Google Maps API,觉得除了大量的语句之外,还有一种更好的方法来搜索全景图像。我认为使用外部哈希表会更有效,更容易维护。每个图像都有一个唯一的,我可以定义它。阅读哈希表,我相信我的说法是正确的,我可以做一个表和完善的函数,以获得我需要的数据,在恒定的时间。有没有一个很好的资源如何构建这个?我对哈希一点经验都没有。 我的逻辑是这样的:每个图像都以的形式保存在一个目录中,其中是一
-
是否可以向Swift协议一致性扩展中添加类型约束?
问题内容: 我想扩展以增加对新协议的一致性-但仅适用于其元素本身符合特定协议的数组。 更笼统地说,我想让带有类型参数的类型(无论是协议类型还是具体类型)仅在类型参数与某些约束匹配时才实现协议。 从Swift 2.0开始,这似乎是不可能的。有什么我想念的方式吗? 例 假设我们有以下协议: 我们可以扩展现有的类型来实现它: 我们还可以扩展实现其所有元素时的实现: 在这一点上,类型本身应该实现,因为它符
-
接口上用于强制一致性的静态方法的替代方法
问题内容: 在Java中,我希望能够定义标记器接口,该标记器接口强制实现提供静态方法。例如,对于简单的文本序列化/反序列化,我希望能够定义一个看起来像这样的接口: 由于Java中的接口不能包含静态方法(如其他许多文章/线程中所述:here和here,此代码不起作用。 但是,我正在寻找一种表达相同意图的合理范例,即对称方法,其中之一是静态的,由编译器强制执行。现在,我们能想到的最好的方法是某种静态工
-
如何保持运行两个Java应用程序的Hibernate缓存一致性?
问题内容: 我们的设计有一个jvm,它是一个jboss / webapp(读/写),用于通过休眠(使用jpa)将数据维护到数据库。该模型具有10-15个持久类,其中关系的深度为3-5个级别。 然后,我们有一个单独的jvm,它是使用此数据的服务器。由于它持续运行,因此只有一个长数据库会话(只读)。 当前不涉及内部jvm缓存-因此我们手动用信号通知另一个jvm。 现在,当webapp更改某些数据时,它
-
PHP一致性hash分布式算法封装类定义与用法示例
本文向大家介绍PHP一致性hash分布式算法封装类定义与用法示例,包括了PHP一致性hash分布式算法封装类定义与用法示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了PHP一致性hash分布式算法封装类定义与用法。分享给大家供大家参考,具体如下: 一、无虚拟节点实现 二、运行结果: save key1 in server: 192.168.1.4 save key2 in server
-
使用spring数据的ElasticSearchTemplate时,是否可以指定写一致性级别?
问题内容: 使用elasticsearchJava客户端时,可以为每个查询指定写入一致性级别和超时: 我没有找到与Spring Data的ElasticSearchTemplate相同的API。 你知道有没有办法? 问题答案: 在devoxx与Spring人员核对之后,似乎没有一种方法可以使用SpringData的ElasticSearchTemplate指定每个查询的写入一致性和超时。
-
浮点文字到IEEE-754二进制模式跨编译器的一致性
这里有一个关于“跨平台浮点一致性”的问题和答案,但它只讨论运行时一致性(IEEE浮点)。 我对编译时一致性感兴趣,特别是: 如果我有一个特定的浮点数,并想在我的源代码中加入一个浮点文字,并让每个针对IEEE-754架构的编译器将其编译成与浮点(或双精度)相同的位模式:我需要做什么? 一定数量的数字 (我知道多年来一直存在争议,关于如何将浮点值从IEEE格式往返到十进制表示法,然后再往返,我不知道这
-
将ConfigurationProperties与内部类一起使用会导致“属性未绑定”异常
我有一个名为LibraryConfig的带有注释的配置属性类。它使用内部类作为属性/配置结构的类型定义。当类是内部类而不是独立类时,我得到“元素[…]“未绑定”错误/异常。为什么会这样?我如何修复它? application.yml 库配置。Java语言
-
分布式(非关系型数据库)数据库中的一致性效应
每当我读到有关NoSQL分布式数据库的内容时,他们都会提到CAP定理,这意味着在分区系统中,您可以具有完全一致性,完全可用性或两者兼而有之,但不能完全两者兼而有之。 我不太清楚他们在谈论什么类型的一致性: 是数据新鲜度的一致性,其中一些客户端可能会获得比其他客户端更旧的数据吗? 或者是一致性,即事务可能仅部分完成,这可能会使数据处于不一致的状态? 第二种解释对我来说听起来很危险,不能真正接受。第一
-
不可共性类数据成员的统一初始化导致 gcc 错误
假设我们有这样的代码: 此代码在最新的 GCC 9.2、叮当 9.2 和 MSVC 19.22 上编译。 但当我将默认析构函数更改为GCC返回错误
-
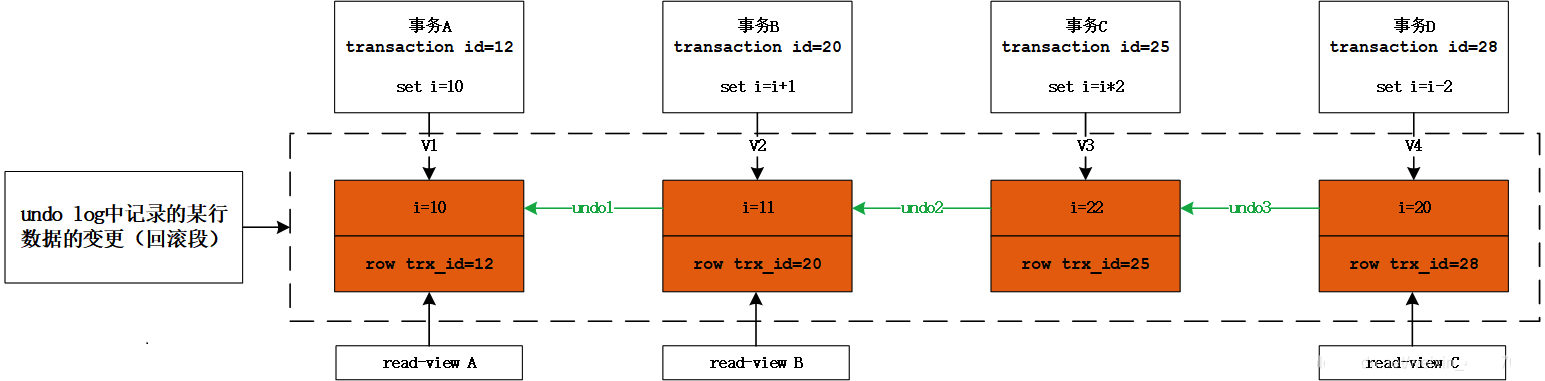 MySQL事务隔离级别以及MVCC一致性视图的实现原理
MySQL事务隔离级别以及MVCC一致性视图的实现原理主要内容:1 事务隔离级别的实现,2 一致性视图的具体实现,3 可重复读的普通查询原理,4 可重复读的更新原理,5 读已提交的原理,6 总结详细介绍MySQL数据库事务隔离级别的实现原理,以及MVCC一致性视图的概念和实现。 下面我们来看看MySQL事务隔离级别的实现原理,以及经常被提到的MVCC一致性视图到底是什么。 1 事务隔离级别的实现 可重复读和读已提交的事务隔离级别在实现上,数据库里面会创建一个视图,访问的时候以视图的逻辑结果为准。 在“可重复读”隔离级别下,这个视图是在事务启动时创建
-
纯唯一性
对于任何实例,一旦编写了,就唯一地确定了。假设您有和,它们都遵守法律。然后 但是这样使用法则感觉像是一种欺骗。有没有一种方法可以避免这种情况而不诉诸于参数性呢?
-
hashCode唯一性
问题内容: 的两个实例是否可能具有相同的值? 从理论上讲,对象是从其内存地址派生的,因此所有对象都应该是唯一的,但是如果对象在GC中移动,该怎么办? 问题答案: 给定合理的对象集合,很可能会有两个具有相同的哈希码。在最好的情况下,它成为生日问题,与数以万计的对象发生冲突。在实践中,使用相对较小的可能的哈希码池创建的对象,仅数千个对象就很容易发生冲突。 使用内存地址只是获得一个稍微随机数的一种方法。