《负载均衡》专题
-
Python:滑动窗口均值,忽略丢失的数据
问题内容: 我目前正在尝试处理实验性时间序列数据集,该数据集缺少值。我想在处理nan值的同时计算该数据集随时间的滑动窗口平均值。对我而言,正确的方法是在每个窗口内计算有限元素的总和,然后将其除以它们的数量。这种非线性迫使我使用非卷积方法来面对这个问题,因此在该过程的这一部分中我遇到了严重的时间瓶颈。作为我要完成的工作的代码示例,我提出以下内容: 输出: 可以在不使用for循环的情况下通过numpy
-
GridLayout(不是GridView)如何均匀拉伸所有孩子
我想要一个2x2的网格,里面有一个按钮。这只是ICS,所以我尝试使用新的GridLayout。 以下是我的布局的XML: 问题是,我的视图在每一行的拉伸并不均匀。这会在GridLayout的右侧产生大量额外空间。 我尝试设置布局重力,但这只适用于行上的最后一个视图。这意味着单元格1会一直延伸,为单元格0提供足够的空间。 如何解决这个问题?
-
在Java范围内均匀生成安全随机数
如何在一定范围内生成安全的统一随机数?范围可能在0到100之间。(上限不是2的幂)。 <代码>java。安全SecureRandom似乎提供了范围0。。2^n。
-
如何使用WHERE id IN(1,2,3,4)获得均匀分布
问题内容: 我有一个查询,该查询从表中拉出喜欢特定对象的用户。等级存储在表格中。到目前为止,我提出的查询看起来像这样: 当每个ID仅需要3个左右的结果时,我希望能够在此查询上放一个,以避免返回所有结果。例如,如果我仅放置一个,则可能会获得8个记录,每个记录具有一个ID,其他ID分别为1或2个记录-即ID分布不均。 有没有一种写此查询的方法来保证(假设一个对象被“点赞”了至少3次),对于列表中的每个
-
提薪后获得低于平均工资的员工
问题内容: 我需要获得fname,lname,比平均工资低400.00美元的员工薪水,即使在加薪10%之后。 我能够使薪水低于平均薪水的员工,但不确定如何使加薪后的薪水低于400美元的员工。 我正在使用MySQL。谢谢你。 这给了我工资低于平均工资的员工: 我当时在想这样的事情,但这是行不通的。未知专栏新闻: 问题答案: 您有一个正确的想法,就是不能在这样的子句中使用别名。只需直接使用公式,就可以
-
Kafka不会均匀地填充主题中的分区
我想有一个主题与10个分区。我使用的是Kafka的默认配置。我用帮助器脚本创建了一个有10个解析的主题,现在我将为它生成消息。 问题是,消费者似乎只有5个分区可以从中获取数据。 让我们更详细地描述一下。 我知道每个分区需要一个使用者线程。我希望能够提交每个分区的偏移量,这是可能的,只有当我有一个线程每个消费连接器每个分区(我是使用高级消费)。 当我这样做10次时,我有10个消费者,每个分区每个线程
-
Flink-如何同时计算求和和和平均值?
Flink(批处理/流式处理)中是否有方法同时计算字段的平均值和总和?使用聚合方法,我可以计算groupBy结果中字段的和,但如何同时计算平均值呢?下面的示例代码。
-
K-均值迭代失败处理输出/群集-2
我刚学了几天Hadoop,当我在Hadoop中执行Mahout的示例代码时,我得到了以下错误: 代码段
-
inflxdb:用于计算StatsD“ExecutionTime”值平均值的查询
我需要更改我的架构吗,还是可以使用当前的设置来更改?
-
如何从laravel获取db中的列的平均值
我的事务表有4列(其他与查询无关) trans_id:整数,pk user_id:整数,fk 金额:双倍 bus_id:整数 我试图通过对列求平均值来获得他们的平均消费金额,但我的回答一直是“找不到”列。 我的迁徙 我路过 它们也都列在我的模型下 但我还是有错误: Illumb\Database\QueryException:SQLSTATE[42S22]:未找到列:“where子句”中的1054
-
如何获得YouTube视频的平均观看时间?
根据YouTubeAnalytics留档,您只能获取上传到自己频道的视频的观看时间,而无法获取播放列表视频(除了在播放列表的上下文中,这对我来说毫无用处)。留档还指出,如果您想访问观看时间信息,则需要频道所有者的许可。https://developers.google.com/youtube/reporting/#Report_Contents 是否有可能使用youtube数据API或分析API或
-
你知道如何计算OOP中的平均值吗?
我知道如何在过程编程中计算平均值,除了在oop中我不知道如何做这个: 我有2个对象,我想计算一下平均年龄: 在我的班上,我有这个 在我的CalculateAverage()方法中,我看不出如何做这个?我的循环有问题。
-
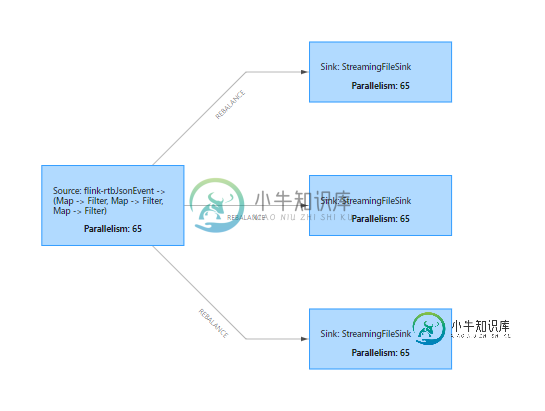 使用Flink Kafka连接器均匀地消耗事件
使用Flink Kafka连接器均匀地消耗事件我正在使用Flink处理Kafka的流数据。流程非常基本,从Kafka开始消耗,数据丰富,然后汇到FS。 在我的例子中,分区的数量大于Flink并行级别。我注意到Flink并没有均匀地消耗所有分区。 有时,在一些Kafka分区中会创建滞后。重新启动该应用程序有助于Flink“重新平衡”消费,并快速关闭滞后。然而,过了一段时间,我看到其他分区出现了滞后等现象。 看到这种行为,我试图通过使用flink
-
最近1分钟的查询平均响应时间
我们使用普罗米修斯和eclipse显微轮廓。在我的endpoint上有一个计时器度量,所以我可以在Prometheus中看到以下度量:count、meanRate、oneMinRate、fiveMinRate、fifteenMinRate、min、max、mean、stddev、p50、P**等。 所以我想要得到我的endpoint的平均响应时间,但仅限于最后一分钟。根据我的经验,平均度量是从应用
-
使用 dplyr 计算某些列的平均值::突变
我想使用dplyr::mutate计算一些列的平均值。 我想包含来计算平均值的列只有BL1到BL9,所以我这样做了。 这行不通。我注意到如果我一个接一个的列,它会工作 我怀疑这是因为我给出的是字符串而不是“列”。 有人能解释这种行为吗?对此最好的解决办法是什么?