《负载均衡》专题
-
问题:训练集中类别不均衡,哪个参数最不准确?
本文向大家介绍问题:训练集中类别不均衡,哪个参数最不准确?相关面试题,主要包含被问及问题:训练集中类别不均衡,哪个参数最不准确?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 准确度(Accuracy) 解析:举例,对于二分类问题来说,正负样例比相差较大为99:1,模型更容易被训练成预测较大占比的类别。因为模型只需要对每个样例按照0.99的概率预测正类,该模型就能达到99%的准确率。
-
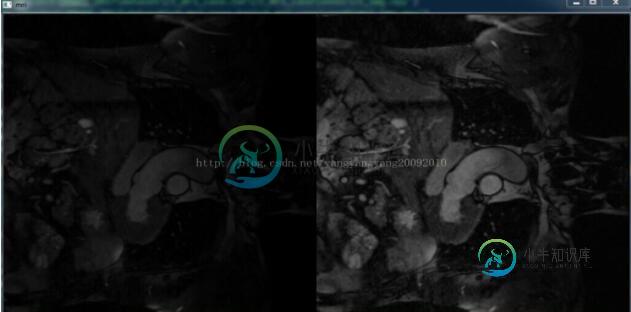 Python cv2 图像自适应灰度直方图均衡化处理方法
Python cv2 图像自适应灰度直方图均衡化处理方法本文向大家介绍Python cv2 图像自适应灰度直方图均衡化处理方法,包括了Python cv2 图像自适应灰度直方图均衡化处理方法的使用技巧和注意事项,需要的朋友参考一下 __author__ = 'Administrator' 均衡化前、后对比效果 以上这篇Python cv2 图像自适应灰度直方图均衡化处理方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持呐喊教程
-
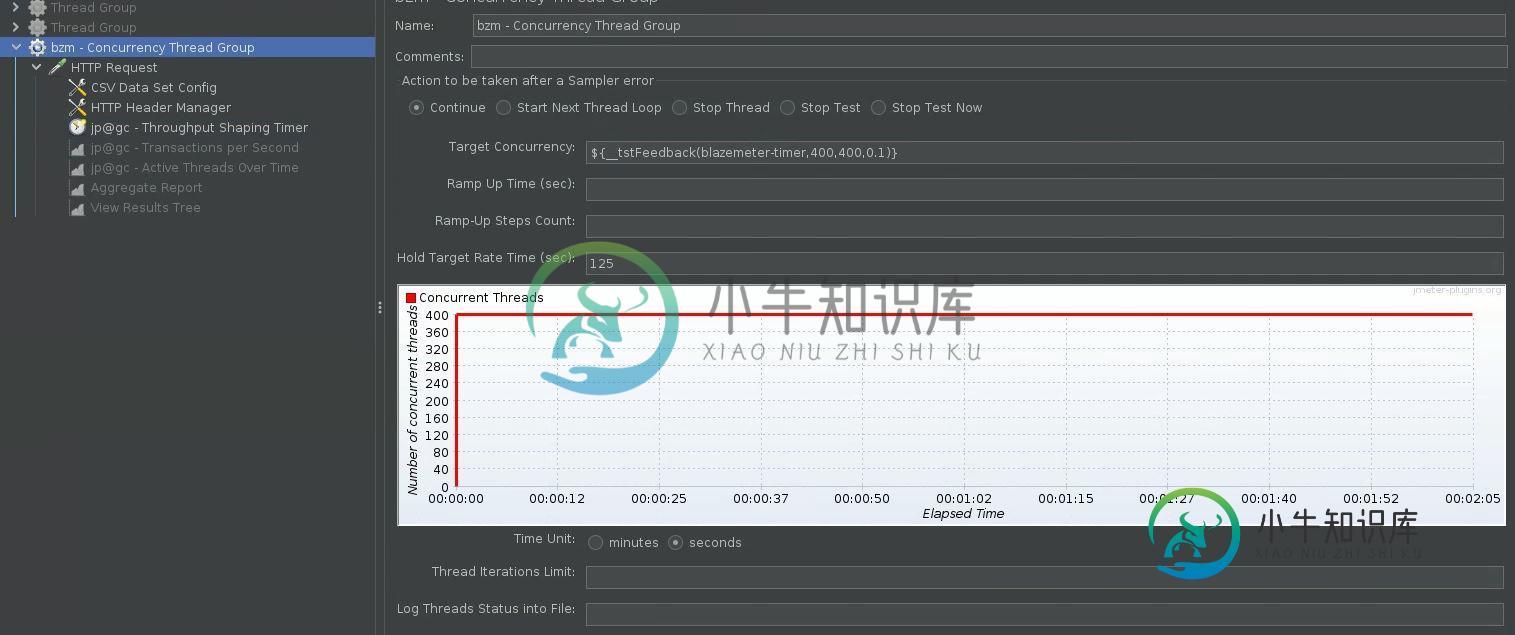 如何使用并发线程组和吞吐量成形计时器组合保持400个RPS的恒定负载
如何使用并发线程组和吞吐量成形计时器组合保持400个RPS的恒定负载我想制作一个测试用例来使用Jmetm发送50,000个具有400 RPS的请求。有人建议我在此用例中使用并发线程组和吞吐量整形计时器的组合,我尝试了以下链接:https://www.blazemeter.com/blog/using-jmeters-throughput-shaping-timer-plugin. 这里的问题是,我在csv中只记录了约28K个响应,而不是50K个响应 无论前一秒发送
-
Chrome开发工具网络选项卡中的“请求有效负载”和“表单数据”之间有什么区别
我必须支持一个旧的web应用程序(我没有编写)。 当我填写表格并提交,然后检查Chrome中的“网络”选项卡时,我会看到“请求有效负载”,通常我会看到“表格数据”。两者之间有什么区别?何时发送一个而不是另一个? 谷歌搜索了这一点,但没有找到任何解释这一点的信息(只是人们试图让javascript应用程序发送“表单数据”而不是“请求负载”)。
-
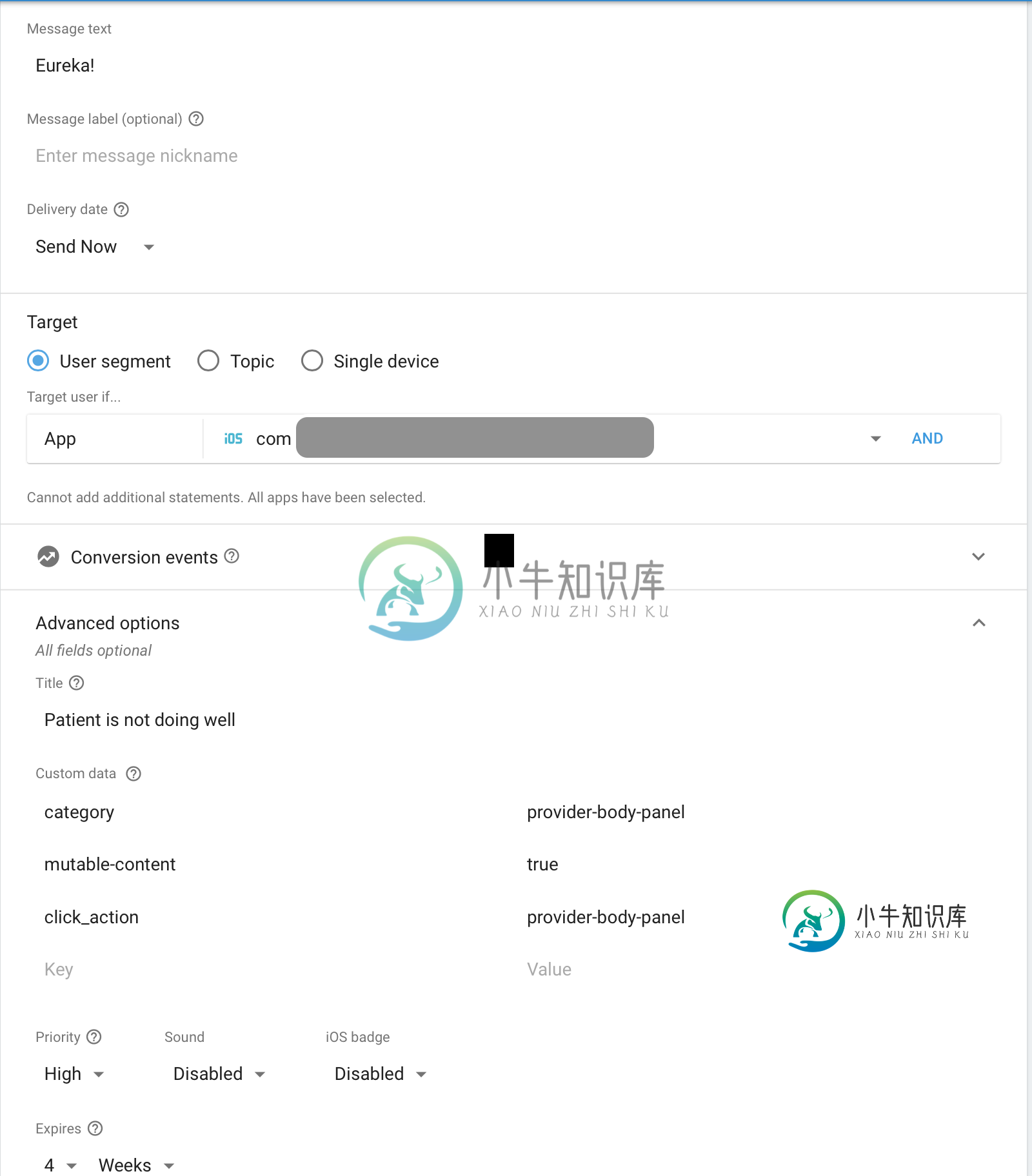 Firebase Cloud消息未以正确格式发送用于iOS通知内容和服务扩展的aps有效负载
Firebase Cloud消息未以正确格式发送用于iOS通知内容和服务扩展的aps有效负载我正在尝试使用Firebase实现通知。当应用程序处于后台或前台时,会正确接收通知。所以,基本的机制起作用了。 现在我已经为应用程序添加了内容扩展和服务扩展。Content扩展在我使用本地通知时起作用,但Firebase消息负载似乎不正确,因为考虑了可选字段。这里有一个指向我的控制台映像的链接: 下面是遇到的Firebase远程通知负载(为了匿名而编辑了一些长的Google号码:
-
如何处理负载并配置tomcat 7服务器和应用程序,使其能够处理2000多个请求
我有ApacheTomcatWeb服务器,在这里我运行3-4JavaSpring和hibernate应用程序。但问题是,当有太多请求进入服务器时,服务器会给出内存不足错误或堆大小错误,最后由于服务器没有响应而导致站点关闭。有时还会出现连接错误或套接字错误。我希望我的服务器至少能处理2000个请求。 到现在为止,我用了很多方法来处理这个问题。 通过更改setenv中的大小来增加服务器的堆大小。sh文
-
 Rest保证-发送POST请求(内容类型:多部分/表单数据)与静态JSON负载和文件上传
Rest保证-发送POST请求(内容类型:多部分/表单数据)与静态JSON负载和文件上传我想发送一个邮政请求- 内容类型为“多部分/表单数据” 在“Body”部分,我有两个参数- 在Rest-Assured代码中,我能够用下面的代码获得字符串格式的静态JSON负载- 当运行此代码时,只有静态JSON有效载荷,我得到了“415”错误代码。问题- 我们怎样才能成功地打这种电话呢 当我想通过这个电话上传文件时,怎么做
-
在JMeter中,在Asp中执行负载测试时,获取登录post请求的“Object moved here”响应。网络应用
我已经在Asp中执行了负载测试。net应用程序使用JMeter。登录时,我收到“objectmovehere”消息作为响应。 在视图结果树中,我发现登录主采样器显示有两个子采样器。其中一个子采样器带有“物体移动到这里”消息。 在我的测试计划中,我处理了-CSS/JQUERY提取器来提取动态值“事件验证” 注意:登录功能请求除外 有人对此有什么解决办法吗?
-
 为什么“JMeter”响应时间与“微博视觉工作室 Web 性能和负载测试”响应时间不同?
为什么“JMeter”响应时间与“微博视觉工作室 Web 性能和负载测试”响应时间不同?“Microsft Visual Studio Web性能和负载测试”和“JMeter”的响应时间不同。“JMeter”总是显示更高的响应时间。 我找不到关于这个问题的具体原因,是“Microsft Visual Studio Web性能和负载测试”还是“JMeter”的故障? “Microsft Visual Studio Web性能和负载测试”响应时间与浏览器响应时间类似。 例如,加载到“go
-
运行移动应用程序负载测试时遇到响应代码401响应消息未经授权错误
我使用jmetm运行加载测试我的脚本记录的移动应用程序。当我运行记录的脚本,然后我得到响应代码401响应消息在运行移动应用程序负载测试时出现未经授权的错误 线程名称:线程组1-1示例开始:2017-09-07 06:52:06 UTC加载时间:37连接时间:0延迟:37字节大小:468发送字节:969头字节大小:293正文字节大小:175示例计数:1错误计数:1数据类型(“文本”|“bin”|“”
-
当android应用处于kill状态时,我如何从推送通知(使用FCM)中获得“数据有效负载”?
我的推送通知(使用FCM)在前台和后台状态下工作正常,但在kill状态下,我只能从系统托盘接收通知,但不能获得“数据有效负载”。我知道onMessageReceived()不是在kill状态下调用的(如果我错了请纠正我),还有什么方法可以在kill状态下调用这个方法或者其他任何方法来获得“数据有效负载”。请救命!
-
为什么两个火花流作业从具有相同组id的相同Kafka主题拉消息不平衡负载,但得到相同的消息?
Kafka 0.8官方文档对Kafka消费者描述如下: “消费者用一个消费者组名称给自己贴标签,发布到主题的每条消息都被传递到每个订阅消费者组中的一个消费者实例。消费者实例可以在不同的进程中或在不同的机器上。如果所有消费者实例都有相同的消费者组,那么这就像传统的队列平衡消费者的负载一样。” 我用Kafka0.8.1.1设置一个Kafka集群,并使用Spark Streaming作业(Spark 1
-
打开其中之一后,所有通知均消失
问题内容: 我有一台向我发送推送通知的服务器,假设我的手机上有5条通知。如果我打开其中一个,所有其他通知都会消失。我只希望单击一个消失。 这是我处理接收通知的方式: 问题答案: 通过将设置为,您还可以从通知中心删除所有通知。 此外,不可能以编程方式删除单个通知,但是从iOS8开始,当用户点击单个通知时,操作系统将为您处理该通知。
-
使用熊猫/数据框计算加权平均值
问题内容: 我有下表。我想根据以下公式计算按每个日期分组的加权平均值。我可以使用一些标准的常规代码来执行此操作,但是假设此数据在pandas数据框中,是否有比通过迭代更简单的方法来实现此目的? 2012年1月1日w_avg = 0.5 (60 / sum(60,80,100))+ .75 (80 / sum(60,80,100))+ 1.0 *(100 / sum(60,80,100)) 2012
-
 Java 实现将List平均分成若干个集合
Java 实现将List平均分成若干个集合本文向大家介绍Java 实现将List平均分成若干个集合,包括了Java 实现将List平均分成若干个集合的使用技巧和注意事项,需要的朋友参考一下 1.初衷是由于调用银行接口的批量处理接口时,每次最多只能处理500条数据,但是当数据总数为510条时。我又不想第一次调用处理500条,第二次调用处理10条数据,我想要的是每次处理255条数据。 下面展示的是我的处理方法 2.写了一个简单的ListUti