《负载均衡》专题
-
如何让Jackson将JSONObject转换为有效负载中的字符串?
为了满足这个字段,我在POJO类中创建了一个属性,并将该类型设置为,这是包中的一个类型。我认为这是有意义的,因为如果我需要在代码中使用它,我可以很容易地以的形式访问信息。我的POJO课上有这样的内容: 然而,杰克逊在发送消息时似乎无法正确地将其转换为字符串。字段始终转换为字符串,作为有效负载中的空对象。 如何让Jackson在发送有效负载时将POJO类中的属性正确转换为字符串并映射为字符串?
-
如何向kubernetes工作负载提供自定义GCP服务帐户?
我正在使用GKE和Terraform配置一个高可用的kubernetes集群。多个团队将在集群上运行多个部署,我预计大多数部署将在一个自定义命名空间中,主要是出于隔离的原因。 我们的一个开放问题是如何管理集群上的GCP服务帐户。 我可以使用自定义GCP服务帐户创建集群,并调整权限,以便它可以从GCR中提取映像,日志到stackdriver等。我认为这个自定义服务帐户将被GKE节点使用,而不是默认的
-
为什么我的网站在运行JMeter负载测试时超时
我是新来的JMeter和。我遵循本教程学习JMeter。 我试图在以下条件下进行负载测试。 当我运行测试时,我尝试加载我的网站(在清除缓存后),但加载页面所需的时间比平时多。当浏览器缓存了数据时,不会出现此问题。 有人能告诉我为什么会发生这种情况吗?是因为当1000个用户加载我的网站时,它可能会崩溃还是什么? 任何形式的解释都将不胜感激。
-
如何在visual studio负载测试中计算95%的响应时间
在分析VSTS负载测试报告时,我们发现endpoint的响应时间如下 平均响应时间 :- 0.68 90% 响应时间 :- 1.18 95% 响应时间 :- 1.34 99% 响应时间 :- 1.68 采样率按照VSTS的建议设置为15秒(当我们设置为低于15秒时,我们会收到警告)。我们使用VSTS云产品来生成负载。 在性能图表(结果)中,显示的响应时间峰值约为0.7秒,高于0.7秒。当我们下载样
-
GKE工作负载标识可以用于访问Google工作表吗?
我目前正在使用GKE Workload Identity从GKE内部访问谷歌云平台资源。这对谷歌云存储和其他平台资源非常有效。 然而,当我试图使用GKE Workload Identity访问Google工作表时,我遇到了一个“身份验证范围不足”的问题。 当我为服务帐户生成密钥文件并在代码中使用它时,我可以手动将作用域设置为。它的工作原理与预期一样,我可以访问该表。如果我将范围更改为,我得到了与G
-
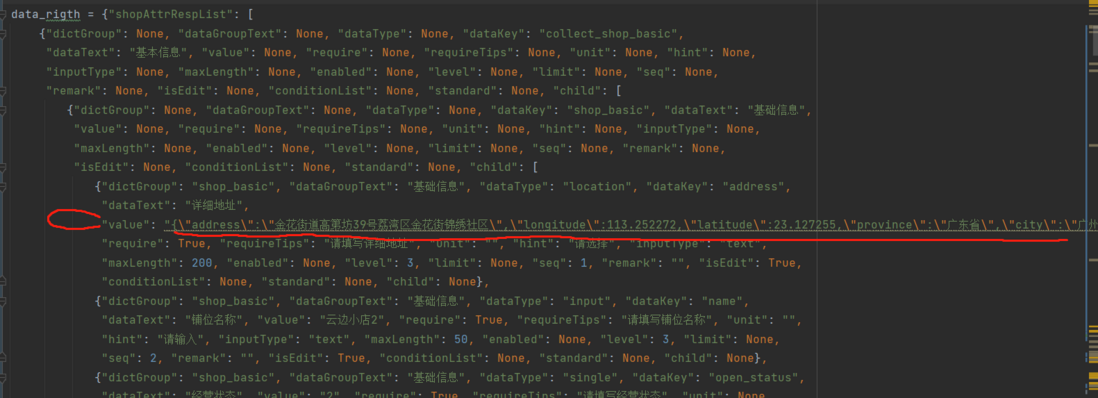 python - 如何在Python中动态修改JSON请求负载中的值?
python - 如何在Python中动态修改JSON请求负载中的值?Python中发送post请求,构建请求体的时候请求负载如下, 关键的地方就是那个value的值,直接发送那个value可以,我想要根据变量修改里边的信息。用的方法是 接口没报错,但是后端处理后是海外、海外、详细地址.......,我猜应该是分割字符串的问题,我直接发送原本的写死的串就没问题。求解。 用json.dumps转整个结构体,然后发送直接报500,根据ChatGPT的思路只将这个键的值改
-
在spring boot rest中验证json有效负载,以在未知属性或空属性作为json有效负载的一部分发送时抛出错误
-
在没有粘性会话的情况下使用TCP负载平衡器代理WebSocket
问题内容: 我想使用Amazon Elastic Load Balancer将WebSocket连接代理到多个node.js服务器。由于Amazon ELB不提供实际的WebSocket支持,因此我需要使用其原始的TCP消息传递。但是,我试图了解没有某种粘性会话功能的情况如何工作。 我了解WebSocket的工作方式是首先从客户端发送HTTP升级请求,服务器通过发送正确处理密钥身份验证的响应来处理
-
如何通过云管理的kubernetes公开nginx,而不使用负载平衡器、helm等?
我正在尝试学习Kubernetes的基础知识,虽然我在本地玩过kubectl和minikube,但我想通过互联网在我可以访问的域上(例如,使用DigitalOcean管理的Kubernetes)展示基本的nginx docker映像。我的绊脚石似乎是所有与网络相关的(服务和入口控制器)。 然而,我也希望避免不得不增加大量的云资源,并且不需要使用太多的依赖项来从我这里抽象出问题,所以请不要使用负载平
-
网络负载平衡器导致长请求在120秒后返回,但响应为空
我有一个有2个节点的GKE集群,服务类型为LoadBalancer。当我在内部调用服务时,长请求不会在120秒后超时。但是,如果我调用转发到内部服务的网络负载均衡器的外部IP,我会收到“来自服务器的空回复”响应。 外部调用示例: 内部调用示例: 我试图在负载均衡器级别找到请求或套接字超时的留档,但没有遇到任何问题。有什么想法吗? 谢谢
-
TestContainer中的Spring Boot云-连接到URL而不使用负载平衡器/服务发现
我正在写一个集成测试。我有一个在Testcontainer中运行的Spring Boot 2.5应用程序。我还让StubRunnerExtension运行WireMock。 我需要Spring Boot应用程序连接到存根WireMock服务器。 发生错误是因为Spring认为是服务的名称。它不是-它是专门为这种情况提供的特殊Test容器主机名(从Test容器连接到主机)。 Wiremock存根肯定
-
使用Apache Camel和Netty对TCP流量进行负载平衡会导致事务失败
null 1.这是Apache Camel-Netty的有效用例吗?我应该看米娜还是其他人? 2.是否可以尝试将tcp通信路由到JMS或其他组件,然后最终到达tcpendpoint? 3.我是否需要编码器/解码器,或者这个配置应该工作? 编辑2: 我增加了客户端的接收超时,并立即注意到预期缓冲区长度的不匹配问题下降到小于1%。但是,我看到使用和不使用Camel时每个事务的响应时间都很大;几乎高出1
-
如何在 AWS 网络负载平衡器上保持 TCP 连接处于活动状态
架构: 我们有一系列物联网设备通过AWS网络负载平衡器(NLB)连接到后端服务器。这是一个双向通道(不是请求-响应样式,而是从任何一方传递给另一方的消息)。 目标: 如何在不活动期间保持连接(NLB的两侧)处于活动状态。 说明:客户端经常进入非活动模式,并且不会向服务器发送(或接收)任何内容。如果此状态持续时间超过 350 秒(NLB 的连接空闲超时值),LB 将以静默方式终止连接。这很糟糕,因为
-
随机分布均匀
问题内容: 我知道如果我使用Java的Random生成器,并使用nextInt生成数字,则数字将均匀分布。但是,如果我使用2个Random实例,并使用两个Random类生成数字,会发生什么。数字是否会均匀分布? 问题答案: 每个实例生成的数字将均匀分布,因此,如果将两个实例生成的随机数序列组合在一起,则它们也应均匀分布。 请注意,即使结果分布是均匀的,您也可能要注意种子,以避免两个生成器的输出之间
-
Python k均值算法
问题内容: 我正在寻找带有示例的k-means算法的Python实现来聚类和缓存我的坐标数据库。 问题答案: 更新:( 在最初回答之后十一年,可能是该进行更新的时候了。) 首先,您确定要使用k均值吗? 该页面很好地总结了一些不同的聚类算法。我建议您在图形之外,特别查看每种方法所需的参数,并确定您是否可以提供所需的参数(例如,k均值需要簇的数量,但是也许您不知道在开始之前就知道了)群集)。 以下是一