《分库分表》专题
-
需求分页和细分之间的区别
本文向大家介绍需求分页和细分之间的区别,包括了需求分页和细分之间的区别的使用技巧和注意事项,需要的朋友参考一下 内存管理是必不可少的功能之一,它可以为执行过程分配内存,并在不再需要该进程时取消分配内存。为此,基本上有两种方法-需求分页和分段。两者之间的差异定义如下。 以下是需求分页和细分之间的重要区别- 序号 键 需求分页 分割 1 定义 分页是一种内存管理技术,其中,进程地址空间分为大小相同的块
-
如何在ng-grid中设置分组分组
问题内容: 我想查看网格中每个组的总计(或者通常是任何聚合函数)。 已请求并按问题完成此操作:https : //github.com/angular-ui/ng-grid/issues/95(但不幸的是,没有任何示例)。 我能够通过config选项重新定义默认模板https://github.com/angular-ui/ng- grid/blob/master/src/templates/ag
-
 Django自定义分页与bootstrap分页结合
Django自定义分页与bootstrap分页结合本文向大家介绍Django自定义分页与bootstrap分页结合,包括了Django自定义分页与bootstrap分页结合的使用技巧和注意事项,需要的朋友参考一下 django中有自带的分页模块Paginator,想Paginator提供对象的列表,就可以提供每一页上对象的方法。 这里的话不讲解Paginator,而是自定义一个分页类来完成需求: 利用bootstrap的css,生成好看的html
-
Spring-Cloud-stream消费者分区重新分配
场景: 运行从名为“test”的具有10个分区的分区中消耗的Spring Boot项目。分区分配发生在13:00:00 在~13:00:30使用: 在~13:05:30触发分区重新分配。 我运行了几次这些步骤,看起来每5分钟就有一次重新分配 是否有办法更改重新分配检查操作频率 编辑: 我的用例如下:我们有引导微服务的集成测试。当主题的使用者首先引导时,如果主题不存在并且它创建的分区数等于配置的并发
-
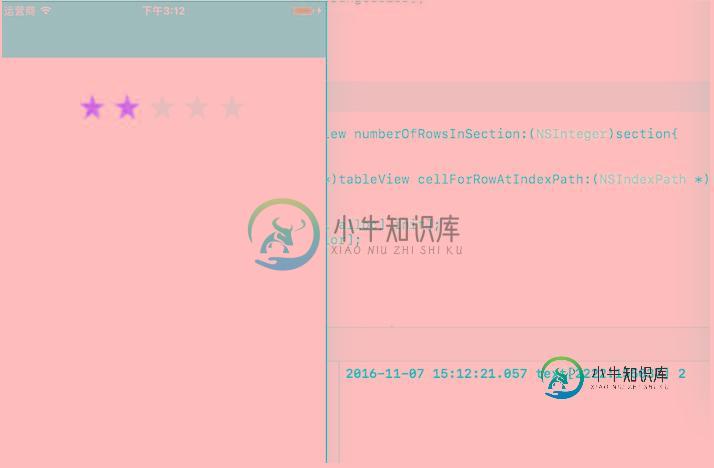 iOS评分(评价)星星图打分功能
iOS评分(评价)星星图打分功能本文向大家介绍iOS评分(评价)星星图打分功能,包括了iOS评分(评价)星星图打分功能的使用技巧和注意事项,需要的朋友参考一下 下载地址:https://github.com/littleSunZheng/StarGradeView 起因:项目中往往涉及到用户的评分反馈,在我的“E中医”项目中,涉及到几处。对此我参考了美团和滴滴的评分图。 评分视图分为展示和评分两种: (1)多数情况下“评分功能
-
ElasticSearch-聚合/分组依据:排序和分页
我正在尝试使用Elasticsearch(2.4)聚合对使用该查询的多个索引按“productId”分组 1) 我想按分数排序,所以我尝试使用 哪个返回 2) 此外,我正在尝试使用分页,“size”键实际起作用,但“from”键不起作用 **更新-聚合结果示例** 希望有人能帮忙
-
如何分配实际未分配的碎片?
问题:我已经启动了五个elasticsearch节点,但只有66,84%的数据在kibana中可用。当我用localhost检查集群运行状况时:9200/u cluster/health?pretty=true我得到了以下信息: 除kibana指数外,我所有的指数都是红色的。 小部分:
-
给定k个分区的Python整数分区
我试图找到或开发Python的整数分区代码。 仅供参考,整数分区将给定的整数n表示为小于n的整数之和。例如,整数5可以表示为 我已经找到了很多解决方案。http://homepages.ed.ac.uk/jkellehe/partitions.php和http://code.activestate.com/recipes/218332-generator-for-integer-partition
-
分片的mongodb不会重新分配数据
我在localhost上设置了一个分片的mongo db环境,有3个配置服务器、2个分片的mongo实例和一个mongos。 集群启动后,我运行以下命令序列: 我启用数据库进行分片,并创建一个索引等。 以上所有操作的结果都是成功的。 但是一旦我做到了:db.foo.stats() 我看到所有的数据都在一个分片中结束,而没有被分发。和运行 生产: 然而,有趣的是,如果我从一个空白集合开始,并在向其中
-
拆分由'['和']'分隔的字符串[重复]
我在文件上写了一些样本数据。数据的格式如下- 我必须提取由“[”和“]”分隔的信息。所以我发现- 我不太熟悉字符串拆分。我只知道当字符串仅由一个字符分隔时(例如-string1-string2-string3-…)如何拆分字符串。
-
如何拆分逗号分隔的字符串?
在逗号处划分字符串的最佳方法是什么,这样每个单词都可以成为ArrayList的一个元素? 例如:
-
带Spring Boot和千分尺的百分位数
我正在用Spring Boot2编写一个应用程序。我的方法试图产生价值,直到价值是唯一的。每个唯一生成的值都被添加到缓存中。一般来说,它应该在第一次尝试时生成值,但是应用程序运行得越多,生成的值就有越多的机会出现重复,并且需要再次生成。 我想有度量,显示值的百分位数。 假设我的代码如下: 我使用千分尺,但不知道我应该从什么开始。因为为了计算百分位数,我需要存储的不是单个值,而是值的数组
-
查找分配给Kafka流实例的分区
我有一个Kafka流媒体应用程序,它订阅了许多主题,每个主题都有许多分区。当我创建应用程序拓扑并启动它时,我是否知道哪些主题的哪些分区分配给我的应用程序的当前实例?我想知道这个独立于任何记录是否由这个实例处理。 我知道当我得到一条记录时,我可以做和获取正在处理的当前记录的分区/主题信息。但我不是在找那个。 我正在寻找一个等效的在kafka流侧。 我也尝试了以下代码,但我得到大小s为0。
-
k部分整数划分的秩与反秩
对于正整数n和k,让“n的k-分区”是k个加起来等于n的不同正整数的有序列表,让给定n的k-分区的“秩”是它在所有这些列表的有序列表中的位置,从0开始。 例如,有两个5(n)的2分区 所以,我想做两件事: 给定n,k和n的k-划分,我想求n的k-划分的秩。 给定n,k和一个秩,我想找到n的k-划分 我能做到这一点,而不必计算n的所有k-划分,在感兴趣的k-划分之前吗? 这个问题与其他问题不同,因为
-
如何为kafka用户分配多个分区
我已经在c中创建了kafka消费者,并创建了一个具有10个分区的主题,当我尝试使用消费者读取数据时,它仅从2个分区读取,然后说没有更多的消息。我尝试使用这两种方法,即订阅和分配,但它们都不起作用。我应该如何将所有10个分区分配给单个使用者,这是将分区分配给使用者的正确方法吗?我已经使用此存储库构建了自定义消费者 https://github.com/edenhill/librdkafka/blob