《分库分表》专题
-
 分库分表:ShardingSphere
分库分表:ShardingSphere主要内容:1.ShardingSphere概念,2.功能列表,3.项目状态,4.分库分表_结果归并1.ShardingSphere概念 ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由、和 这3款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务 和 数据库治理功能,可适用于如Java同构、异构语言、云原生等各种多样化的应用场景。 Apache ShardingSphere 旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现
-
 分库分表-入门
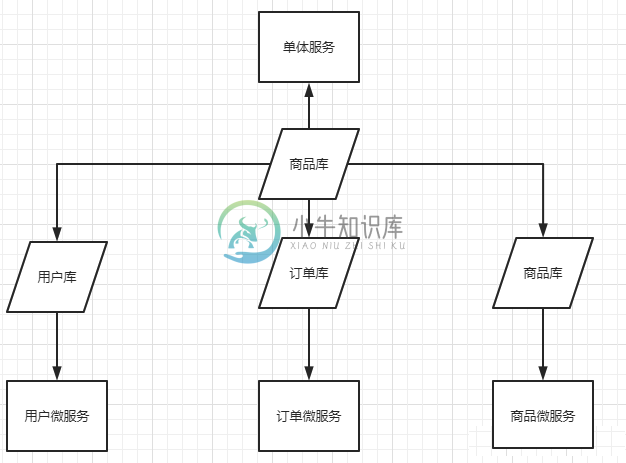
分库分表-入门主要内容:1.数据库瓶颈,2.垂直切分,3.水平切分,4.数据分片规则,5.分库分表带来的问题1.数据库瓶颈 不管是IO瓶颈,还是CPU瓶颈,最终都会导致数据库的活跃连接数增加,进而逼近甚至达到数据库可承载活跃连接数的阈值。在业务Service来看就是,可用数据库连接少甚至无连接可用。 (并发量、吞吐量、崩溃)。 1.1 IO瓶颈 第一种:磁盘读IO瓶颈,热点数据太多,数据库缓存放不下,每次查询时会产生大量的IO,降低查询速度 -> 分库和垂直分表。 第二种:网络IO瓶颈,请求的数据太多,
-
Zebra 分库分表接入
该文档主要介绍Zebra分库分表ShardDataSource的接入和使用,主要包括分库分表的背景知识、ShardDataSource的配置、分库分表规则的配置等。 2 准备 2.1 背景介绍 在一个业务刚上线时,可能使用某个单表存储数据。随着时间的推移和用户的增加,单表内的数据量会不断变大,总有一天数据量会大到一个难以处理的地步。这时仅仅一张表的数据就可能过亿甚至更多,无论是查询还是修改,对于它
-
Zebra 分库分表介绍
读写分离,主要是为了数据库读能力的水平扩展(参考:Zebra读写分离介绍) 一旦业务表中的数据量大了,从维护和性能角度来看,无论是任何的 CRUD 操作,对于数据库而言都是一件极其耗费资源的事情。即便设置了索引, 仍然无法掩盖因为数据量过大从而导致的数据库性能下降的事实 ,这个时候就该对数据库进行 水平分区 (sharding,即分库分表 ),将原本一张表维护的海量数据分配给 N 个子表进行存储和
-
分库分表中间件 ShardingSphere
ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar(计划中)这 3 款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。 架构 Sharding-JDBC 定位为轻量级 J
-
分库分表合并迁移
本文介绍了 DM 提供的分库分表的合并迁移功能,此功能可用于将上游 MySQL/MariaDB 实例中结构相同/不同的表迁移到下游 TiDB 的同一个表中。DM 不仅支持迁移上游的 DML 数据,也支持协调迁移多个上游分表的 DDL 表结构变更。 简介 DM 支持对上游多个分表的数据合并迁移到 TiDB 的一个表中,在迁移过程中需要协调各个分表的 DDL,以及该 DDL 前后的 DML。针对用户的
-
Zebra 分库分表 API 介绍
zebra API是针对分库分表场景(ShardDataSource),提供的一套可以通过手动指定一些路由参数 的方式来改变zebra默认路由行为的API。通过API,用户可以手动指定SQL本身以外的列 或值 来实现将SQL路由到任意用户想要路由的表上。 zebra API依靠ShardDataSourceHelper类提供的static接口,来实现相关的功能。 zebra API功能有哪些 ze
-
1.4.2 现在有一个未分库分表的系统,未来要分库分表,如何设计才可以让系统从未分库分表动态切换到分库分表上?
面试题 现在有一个未分库分表的系统,未来要分库分表,如何设计才可以让系统从未分库分表动态切换到分库分表上? 面试官心理分析 你看看,你现在已经明白为啥要分库分表了,你也知道常用的分库分表中间件了,你也设计好你们如何分库分表的方案了(水平拆分、垂直拆分、分表),那问题来了,你接下来该怎么把你那个单库单表的系统给迁移到分库分表上去? 所以这都是一环扣一环的,就是看你有没有全流程经历过这个过程。 面试题
-
DM 分库分表合并场景
本文介绍如何在分库分表合并场景中使用 Data Migration (DM)。使用场景中,三个上游 MySQL 实例的分库和分表数据需要迁移至下游 TiDB 集群。 上游实例 假设上游库结构如下: 实例 1 Schema Tables user information, log_north, log_bak store_01 sale_01, sale_02 store_02 sale_01, s
-
在分裂重叠上分裂[拉库]
只是为了澄清事情,我知道正确的代码是: 但我的问题是关于“错误”代码的内部工作。拉库是怎么得出那个结果的?
-
分库分表之后,id 主键如何处理?
本文向大家介绍分库分表之后,id 主键如何处理?相关面试题,主要包含被问及分库分表之后,id 主键如何处理?时的应答技巧和注意事项,需要的朋友参考一下 因为要是分成多个表之后,每个表都是从 1 开始累加,这样是不对的,我们需要一个全局唯一的 id 来支持。 生成全局 id 有下面这几种方式: UUID:不适合作为主键,因为太长了,并且无序不可读,查询效率低。比较适合用于生成唯一的名字的标示比如文件
-
 基于订单系统的分库分表实战
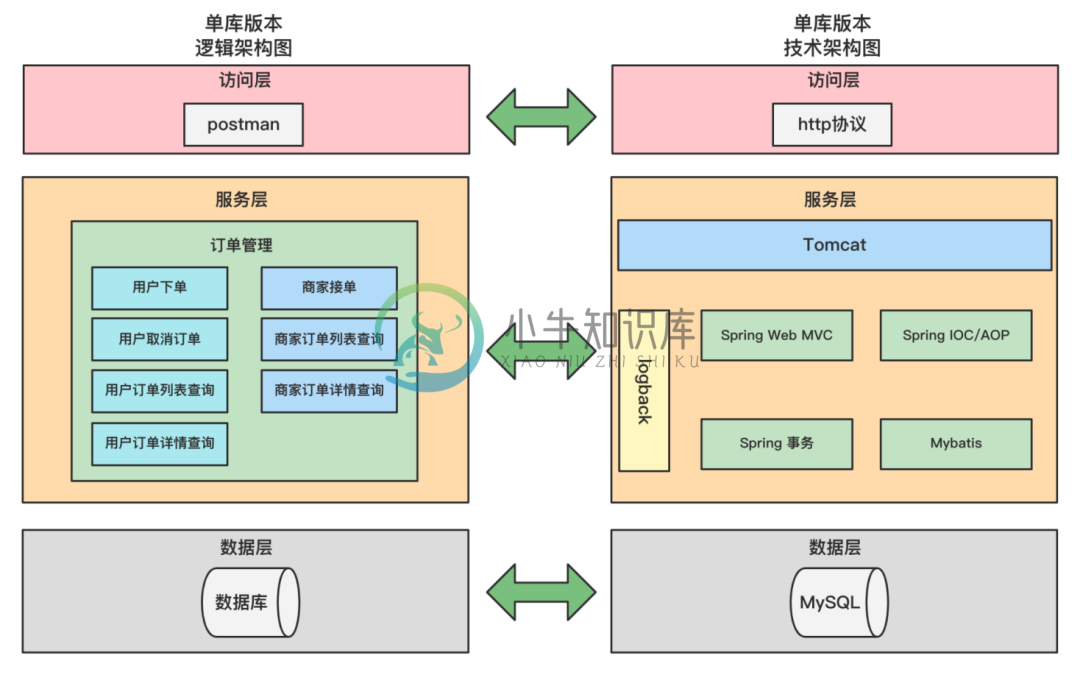
基于订单系统的分库分表实战主要内容:前 言,认识一下单库版本的订单系统,业务快速增长,驱动系统架构不断演进,来看一下分库分表版本的订单系统架构,结束语前 言 各位读者朋友,大家好,这是分库分表实战的第一篇文章,首先介绍一下"基于ShardingSphere的分库分表实战"的设计思路及内容。 本实战的重点是分库分表实战,比较适合1~3年工作经验的程序员朋友。实战主要以外卖APP中的外卖订单来作为本次实战的核心业务。 基于外卖订单业务,儒猿技术团队开发了一个外卖订单项目,通过该项目逐步分析随着订单数据量逐步增加,系统将遇到什
-
乐观模式下分库分表合并迁移
本文介绍了 DM 提供的乐观模式下分库分表的合并迁移功能,此功能可用于将上游 MySQL/MariaDB 实例中结构相同/不同的表迁移到下游 TiDB 的同一个表中。 注意: 在没有深入了解乐观模式的原理和使用限制的情况下不建议使用该模式,否则可能造成迁移中断甚至数据不一致的严重后果。 背景 DM 支持在线上执行分库分表的 DDL 语句(通称 Sharding DDL),默认使用“悲观模式”,即当
-
悲观模式下分库分表合并迁移
本文介绍了 DM 提供的悲观模式(默认模式)下分库分表合并迁移功能。此功能用于将上游 MySQL/MariaDB 实例中结构相同的表迁移到下游 TiDB 的同一个表中。 使用限制 DM 在悲观模式下进行分表 DDL 的迁移有以下几点使用限制: 在一个逻辑 sharding group(需要合并迁移到下游同一个表的所有分表组成的 group)内,所有上游分表必须以相同的顺序执行相同的 DDL 语句(
-
.NET Core实现分表分库、读写分离的通用 Repository功能
本文向大家介绍.NET Core实现分表分库、读写分离的通用 Repository功能,包括了.NET Core实现分表分库、读写分离的通用 Repository功能的使用技巧和注意事项,需要的朋友参考一下 首先声明这篇文章不是标题党,我说的这个类库是 FreeSql.Repository,它作为扩展库现实了通用仓储层功能,接口规范参考 abp vnext 定义,实现了基础的仓储层(CURD)。