《空指针》专题
-
非空判断
大家在使用 Lua 的时候,一定会遇到不少和 nil 有关的坑吧。有时候不小心引用了一个没有赋值的变量,这时它的值默认为 nil。如果对一个 nil 进行索引的话,会导致异常。 如下: local person = {name = "Bob", sex = "M"} -- do something person = nil -- do something print(person.name)
-
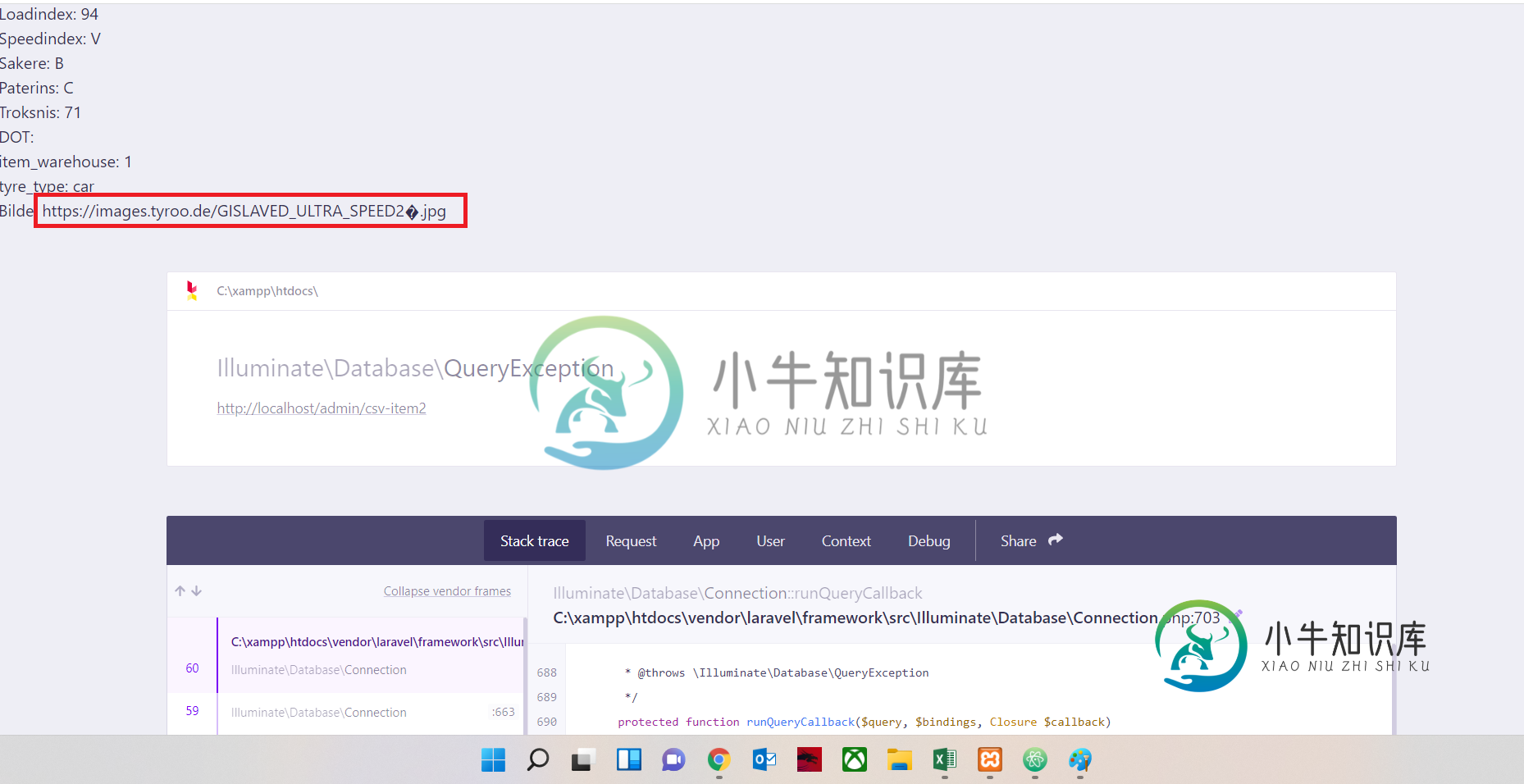 删除空白
删除空白我遇到了损坏的CSV问题,它在图像链接中有空白。 CSV文件由我的客户业务合作伙伴自动创建,约22000行。CSV中大约有30个链接被破坏,我无法修复。因为它每3小时更新一次。 所以,我试图想出一个自动的解决方案,但似乎没有任何效果。 问题在于图像链接,如以下链接:https://images.tyroo.de/GISLAVED_ULTRA_SPEED2�.jpg 它以前有空间。一些文件有3个空格
-
空csv文件
我正在尝试运行我的scrapy spider,它不会返回错误,但会输出一个空的csv文件 我正在通过命令行scrapy crawl AnimeReviews-o AnimeReviews.csv-t csv启动蜘蛛 这是我用过的图书馆 这是我的蜘蛛 这是爬行后的原木 如果你需要更多的信息,请告诉我。
-
Java堆空间
我面临一些关于内存问题的问题,但我无法解决它。非常感谢您的帮助。我不熟悉Spark和pyspark功能,试图读取大约5GB大小的大型JSON文件,并使用 每次运行上述语句时,都会出现以下错误: 我需要以RDD的形式获取JSON数据,然后使用SQLSpark进行操作和分析。但是我在第一步(读取JSON)本身就出错了。我知道要读取如此大的文件,需要对Spark会话的配置进行必要的更改。我遵循了Apac
-
JavaScript空检查
如果在除 之外的任何上下文中访问未定义的变量,您将得到一个错误 我发现,在Ryan的回答中♦, maerics和nwellnhof,即使没有为函数提供参数,其参数变量也总是声明的。这一事实也证明下面列表中的第一项是错误的。 据我了解,可能会出现以下情况: > 函数的参数为(或),在这种情况下,已保护内部代码,呈现
-
javax.servlet.ServletException:java.lang.OutOfMemoryError:Java堆空间
我想从网页上选定的文本中提取名词,并在文本显示时突出显示它们。所以我使用OpenNLP库来解析和获取名词列表。它在java类中运行良好,没有内存问题,尽管在显示输出之前花费了6-7秒,但当我在jsp页面中运行代码时,我得到了以下错误: 根本原因 我读到的一些解决方案建议通过这样做来增加apache tomcat的堆内存大小: 所以我将其设置为-Xmx2g,但仍然会产生相同的错误。我认为我不需要修改
-
Android emulator空白
每当我在片段的OnCreateView中添加这段代码时,我的模拟器就会变成空白??我有一个活动,在按下一个按钮后,它变为空白,因为包含这个片段的另一个活动被称为。 知道吗?这是日志 12-26 19:50:25.575 2254-2304/com。实例乌梅拉西夫。带OpenGLRenderer的chattris:未能在表面0xa36f3080上设置EGL\u交换行为,错误=EGL\u成功 12-2
-
HystrixRequestContext.GetContextForCurrentThread()变为空
在我的springboot应用程序中,我正在用HystrixCommand注释包装一个代码块,以指示该代码块受到保护。另外,我使用线程作为hystrix执行隔离策略。由于代码块运行在一个单独的线程中(hystrix-{protected Method's commandKey}-x),我将通过编写一个自定义的HystrixCommandExecutionHook,在所有日志中添加唯一的id,以使调
-
Json空索引
我有一个ionic应用程序,它将json数据发送到使用laravel作为后端的api。 当发送请求到我的路由时,我在控制器上调用一个方法... 然后,该控制器获取数据并将其输入数据库,但有时并非所有从ionic应用程序发送的数据都在数据库中。 也就是说,我的laravel应用程序正在等待名字,姓氏,公司,有时我的离子应用程序只会发送first_name,last_name意味着公司的索引丢失。 如
-
Node.jsrequest.body是空的
尝试从MEAN应用程序中的注册表单发布,我可以使用Postman使用x-ows-form-urlencoded成功发布,但当我console.log时,应用程序中的请求正文为空。注册表单(部分): 应用程序编程接口。js(部分) 我有app.usebody Parser在server.js之前调用api.js 服务器js(部分) 我做错了什么,但看不出是什么。 为@mscdex:register添
-
FindFragmentByTag()返回空
我无法理解为什么findFragmentByTag()在我的代码中返回null。我已经在片段onCreate()上设置了RetainInstance(true),并且正在使用getSupportFragmentManager()。findFragmentByTag(),因为它是SherlockFragmentActivity。 这是我的活动代码: } 这是我的片段代码:
-
pyspark:Java.lang.OutOfMemoryError:Java堆空间
我最近一直在我的服务器上使用PySpark和Ipython,服务器上有24个CPU和32GB RAM。它只在一台机器上运行。在我的过程中,我想收集大量的数据,如下代码所示: 当我做的时候 它给了我outOfMemory错误。。此外,我不能在此错误后对Spark执行任何操作,因为它失去了与Java的连接。它给出了。 看起来堆空间很小。我怎么才能把它设置到更大的限度呢? 编辑: 运行前尝试的内容: 我
-
WebView空引用
E/AndroidRuntime:致命异常:IntentService[NotificationActionService]进程:tk.ypod.ypod,pid:24013 java.lang.NullPointerException:试图对空对象引用调用虚拟方法“Android.view.view Android.view.view.FindViewById(int)” 我试图修复这个错误几个
-
javamljava.lang.OutOfMemoryError:Java堆空间
我使用javaml训练分类器。现在,我的数据中的实例包含如下格式的向量 1 0:5 1:9 24:2 ...... 所以当我从文件中读取这些时,我使用string.split.然后将值放入稀疏实例中,然后将其添加到分类器中。 然而,我得到了一个堆空间内存错误。我读过关于字符串的文章。split()导致内存泄漏,因此我使用了新的String来避免内存泄漏。然而,我仍然面临堆空间问题 代码如下所示 /
-
PaginationAndSortingRepository返回空
下面是我的控制器代码:- 以下是我的服务代码:- 下面是我的存储库代码:-