《计算机》专题
-
1.5 个人计算、分布式计算与客户/服务器计算
1977年,Apple 计算机公司使个人计算(personal computer)得以普及。最初拥有一台计算机只是爱好者的梦想,随着它的价格不断降低,人们可以购买供个人或办公使用的计算机。1981年,世界上最大的计算机广家IBM公司推出了IBM个人计算机(IBM Personal computer)。一夜之间,个人计算机遍布公司、企业和政府机关。 然而这些计算机只是“独立”的个体,各自做自己的工作
-
计算所有值并计算一些值
我有这张桌子, 我想要表中的uid计数和订单价格中的uid计数 我这样做: 但我得到的结果是: 有什么问题?
-
MySQL:计算列
问题内容: 我刚开始使用SQL并遇到了问题。 在我的数据库中,我目前有两个表,电影院和剧院。我正在尝试在Cinemas表中创建一列“#Theatres#”,该表计算着Cinemas表中具有与Cinemas表中的Cinema相同的CinemaID(外键)的Theaters表中的剧院数量。我将其用作SQL查询: 但是想知道是否有可能在Cinemas表中创建一列,该列会自动执行上述查询并将值插入到每一行
-
科学计算
Python 在科学计算上的应用非常广泛,包括数学、统计学、图形学……等等, 也是科学计算领域的首选编程语言之一。 这一部分的文章主要是介绍 Python 在科学计算领域常用的库,以及科学计算在日常中可能的实际用例。 常用库介绍 IPython 和 Jupyter Notebook NumPy NumPy 是 Python 科学计算生态系统的基础,提供了多维数组操作、线性代数运算、傅立叶变换等 多
-
SimpleDateFormat周计算
问题内容: 我用SimpleDateFormat得到一些令人费解的结果,并希望有人可以阐明这个问题。输出: 我是否应该将一年的最后一个“周”视为特例?还是这是正确的解释方式?显然,当尝试顺序组织一周时,顺序是不正确的。调整初始值后,2005年12月25日被视为第53周。我还没有看过Joda,看看Joda是否产生类似的结果。 相关代码: 背景:我在JasperReports中使用交叉表(分组为星期的
-
计算时差
问题内容: 在我的程序开始和结束时, 但是,当我尝试区别时,我会遇到语法错误…。我做错了一些事情,但是我不确定发生了什么… 基本上,我只想在程序开始时将时间存储在变量中,然后将第二次时间存储在末尾的第二个变量中,然后在程序的最后一位中计算差并显示出来。我不是要为功能速度计时。我正在尝试记录用户通过某些菜单花费的时间。做这个的最好方式是什么? 问题答案: 该模块将为您完成所有工作: 如果您不想显示微
-
计算时间
我正试图在RoR上创建一个计算时间的应用程序。 当您按下开始按钮时,它会拉Time.now,然后,当您按下停止时,它会再次拉Time.now,然后计算两者之间的时间量。然后它会通过to_i将给定的秒转换为整数,然后将整数秒计算为小时:分钟:秒 然而,我的代码出了点问题,它不停地抛出一个又一个错误。 当前顺序为 nil:NilClass 的“未定义方法 '-'”
-
 矩阵计算
矩阵计算我有一个矩阵。只有唯一的颜色以不同的权重重复它们自己。从它们中,我得选择一半,另一半必须用从第一个中最接近的元素替换。 我想到了在图像中循环,并搜索最近的颜色为当前的一个。找到后,我把一个换成另一个。 但我有3个循环、、。前两个I循环通过RGB矩阵,第三个用于循环到包含最终颜色的矩阵。这需要一些时间来计算。 可以做些什么来加快它的速度? 循环如下所示: 表示选择为最终颜色的半色。 我可以考虑一些小
-
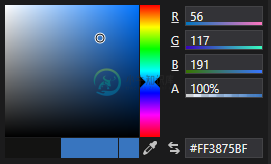 计算RGB值
计算RGB值我目前正在编码一个colorpicker并尝试创建一个函数,它需要3个介于0和255(RGB)之间的整数。 如果你看上面链接的图像,你可以看到在中心有一个彩虹-渐变。上面的所有RGB值至少包含一个0和一个255的整数。另一个可以是0到255之间的任何值。然后在图像的左边有一个正方形,它包含这个“彩虹颜色”的所有“子颜色”的渐变。 函数应该取这个子颜色的RGB值(例如,R=112,G=158,B=7
-
CRC16-CCITT计算
这是代码 更新的答案
-
计算余数
要求定义一个int型数组a,包含100个元素,保存100个随机的4位数。再定义一个int型数组b,包含10个元素。统计a数组中的元素对10求余等于0的个数,保存到b[0]中;对10求余等于1的个数,保存到b[1]中,……依此类推。 解决(python) #!/usr/bin/env python #coding:utf-8 import random if __name__=="__main__"
-
1.4.15.6 计算列
注意 当前章节中涉及的配置一般适用于关系数据库。这里展示的扩展方法在你安装了关系数据库提供程序之后就能获得(由Microsoft.EntityFrmeworkCore.Relational 程序包共享)。 计算列是值其值是在数据库中被计算出来的列。计算列可以利用数据表中的其他列来计算它的值。 惯例 按照惯例不会在模型中创建计算列。 数据注解 不能使用数据注解来配置计算列。 流式 API 可以使用流
-
数值计算
机器学习通常需要大量的数值计算。通过迭代更新估计的过程来解决数学问题,而不去求得一个公式化的结果。通常的操作包括优化和求解线性方程系统。对于采用有限的记忆储存的不能精确表述的问题,即使是估计在数值计算机上估计一个函数方程的2解都是很困难的。(注,MNIST,Mixed National Institute of Standards and Technology database,国家标准与技术研究
-
类型计算
在这一点上,如果你有兴趣像MPL一样进行类型计算,你可能会想知道Hana如何帮助你。不用担心,Hana提供了一种通过将类型表示为值来执行具有大量表达性的类型计算的方法,就像我们将编译时数字表示为值一样。 这是一种全新的接触元编程的方法,如果你想熟练使用Hana,你应该尝试将你的旧MPL习惯放在一边。 但是,请注意,现代C++的功能,如自动推导返回类型,在许多情况下不需要类型计算。 因此,在考虑做一
-
边缘计算
TBD 参考 The Birth of an Edge Orchestrator – Cloudify Meets Edge Computing K8s(Kubernetes) and SDN for Multi-access Edge Computing deployment