《操作数》专题
-
 RxJava 转换操作符
RxJava 转换操作符主要内容:RxJava 转换操作符 介绍,RxJava 转换操作符 示例RxJava 转换操作符 介绍 以下是用于转换从 Observable 发出的信息的运算符。 运算符 描述 Buffer 定期将 Observable 中的项目收集到包中,然后发出包而不是项目。 FlatMap 用于嵌套的 observable。将项目转换为 Observable。然后将项目展平为单个 Observable。 GroupBy 将一个 Observable 分成按键组织的一组 Obs
-
 RxJava 创建操作符
RxJava 创建操作符主要内容:RxJava 创建操作符 介绍,RxJava 创建操作符 示例RxJava 创建操作符 介绍 以下是用于创建 Observable 的运算符。 运算符 描述 Create 从头开始创建一个 Observable 并允许以编程方式调用观察者方法。 Defer 在观察者订阅之前不要创建 Observable。为每个观察者创建一个新的 observable。 Empty/Never/Throw 创建一个行为受限的 Observable。 From 将对象/数据结构
-
 Tableau过滤器操作
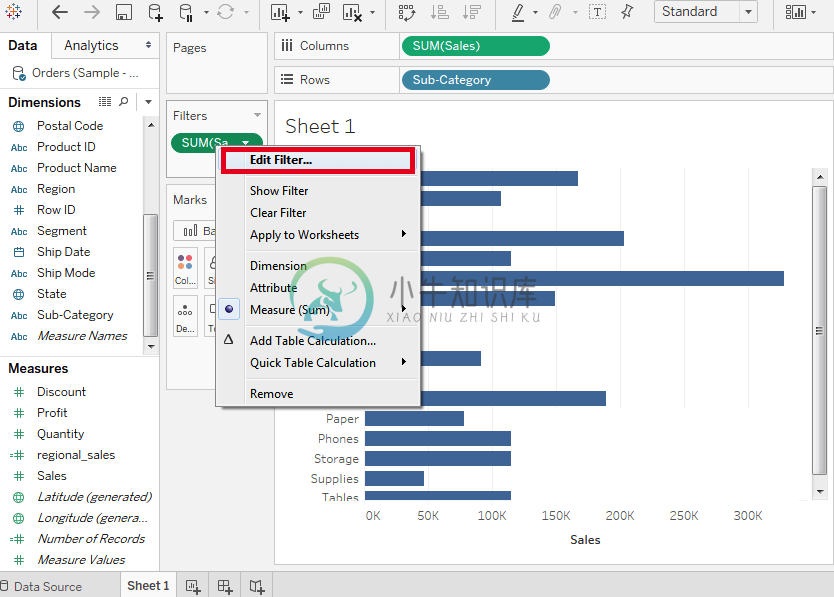
Tableau过滤器操作主要内容:1. 创建过滤器,2. 创建度量过滤器,3. 创建维度过滤器,4. 如何清除过滤器任何数据分析和可视化工作都涉及使用广泛的数据过滤。Tableau具有各种过滤以满足这些需求。 Tableau具有许多内置功能,可以使用度量和维度对数据应用过滤器。 对于度量,过滤器选项提供数值计算。维度的过滤器选项使用自定义值列表或从菜单中选择字符串值。 1. 创建过滤器 通过将所需字段拖到“过滤器(Filters)”功能区来设计过滤器。 然后,通过将维度(Sub-Category)拖动到行架子并
-
 OpenCV索贝尔操作
OpenCV索贝尔操作主要内容:索贝尔变体使用索贝尔(sobel)操作,可以在水平和垂直方向上检测图像的边缘。可以使用方法在图像上应用操作。以下是这种方法的语法 - 该方法接受以下参数 - src - 表示源(输入)图像的类的对象。 dst - 表示目标(输出)图像的类的对象。 ddepth - 表示图像深度的整数变量()。 dx - 表示导数的整数变量(或)。 dy - 表示导数的整数变量(或)。 示例 以下程序演示如何在给定图像上执行
-
 OpenCV形态学操作
OpenCV形态学操作主要内容:示例在前面的章节中,我们讨论了侵蚀和扩张的过程。 除了这两个,OpenCV还有更多的形态转换。 类的方法的用于在给定的图像上执行这些操作。 以下是这种方法的语法 - 该方法接受以下参数 - src - 表示此操作的源(输入图像)的对象。 dst - 表示此操作的目标(输出图像)的对象。 op - 表示形态操作类型的整数。 kernel - 表示卷积核的对象。 示例 下面的程序演示了如何使用OpenCV
-
OrientDB Python连接操作
Python的OrientDB驱动程序使用二进制协议。 PyOrient是git hub项目名称,它用于将OrientDB与Python连接起来并操作数据。 它适用于OrientDB 1.7及更高版本。 以下命令用于安装。 可以使用名为的脚本文件执行以下任务 - 创建客户端实例,也就是创建一个连接。 创建名为的数据库。 打开名为的数据库。 创建类。 创建属性ID和名称。 将记录插入类。 参考以下代
-
OrientDB Java连接操作
与RDBMS类似,OrientDB支持JDBC。 为此,首先我们需要配置JDBC编程环境。 以下是在应用程序和数据库之间创建连接的过程。 首先,我们需要下载JDBC驱动程序。 请访问以下链接 https://code.google.com/archive/p/orient/downloads 下载OrientDB-JDBC。 以下是实现OrientDB-jdbc连接的基本五个步骤。 加载JDBC驱
-
mmap:不允许操作
问题内容: 我正在尝试在用户空间中使用mmap读取“ mem_map”开始的物理内存。它是一个包含所有物理页面的数组。这是一台运行3.0内核的i386计算机。 代码是这样的: 我以此为根。输出为: 可以肯定的是,我搜索了问题并将以下行添加到我的/etc/sysctl.conf文件中: 但这也不起作用。 谁知道为什么不允许这样的mem_map操作,以及如何解决呢? 谢谢。 问题答案: 听起来好像内核
-
执行压缩操作
一个压缩操作被执行,一直等到结束或按下“取消”按钮立即中断它。当压缩或解压时,您也可以按下“后台操作”和“暂停”按钮。“后台操作”把 WinRAR 最小化到任务栏中。当完成当前操作后或您单击任务栏上的小 WinRAR 图标它会自动复原。“暂停”按钮暂停当前操作,您需要按下“继续”来恢复它。 不管在压缩还是解压时,命令窗口上部的进度条都会显示当前文件的处理进度。 当压缩和某些解压操作期间,指示总操作
-
6.12.查找树操作
在我们看实现之前,先来看看 map ADT 提供的接口。你会注意到,这个接口与Python 字典非常相似。 Map() 创建一个新的空 map。 put(key,val) 向 map 中添加一个新的键值对。如果键已经在 map 中,那么用新值替换旧值。 get(key) 给定一个键,返回存储在 map 中的值,否则为 None。 del 使用 del map[key] 形式的语句从 map 中删除
-
6.9.二叉堆操作
我们的二叉堆实现的基本操作如下: BinaryHeap() 创建一个新的,空的二叉堆。 insert(k) 向堆添加一个新项。 findMin() 返回具有最小键值的项,并将项留在堆中。 delMin() 返回具有最小键值的项,从堆中删除该项。 如果堆是空的,isEmpty() 返回 true,否则返回 false。 size() 返回堆中的项数。 buildHeap(list) 从键列表构建一个
-
Spark Streaming 基本操作
一、案例引入 这里先引入一个基本的案例来演示流的创建:获取指定端口上的数据并进行词频统计。项目依赖和代码实现如下: <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.12</artifactId> <version>2.4.3</version> </dependen
-
Hive 常用 DML 操作
一、加载文件数据到表 1.1 语法 LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] LOCAL 关键字代表从本地文件系统加载文件,省略则代表从 HDFS 上加载文件: 从本地文件系统加载文件时, filepath
-
Hive 常用 DDL 操作
一、Database 1.1 查看数据列表 show databases; 1.2 使用数据库 USE database_name; 1.3 新建数据库 语法: CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name --DATABASE|SCHEMA 是等价的 [COMMENT database_comment] --数据库注释
-
文件系统操作
前言 准备了很久,找了好多天资料,还不知道应该如何动笔写:因为担心拿捏不住,所以一方面继续查找资料,一方面思考如何来写。作为《Shell编程范例》的一部分,希望它能够很好地帮助 Shell 程序员理解如何用 Shell 命令来完成和 Linux 系统关系非常大的文件系统的各种操作,希望让 Shell 程序员中对文件系统"混沌"的状态从此消失,希望文件系统以一种更为清晰的样子呈现在眼前。 文件系统在