《操作数》专题
-
Git推送(push)操作
在本文章教程中,我们将演示如何查看 Git 存储库的文件和提交文件记录,并对存储库中的文件作修改和提交。 注意:在开始学习本教程之前,先克隆一个存储库,有关如何克隆存储库,请参考: http://www.yiibai.com/git/git_clone_operation.html 在前面的文章中,都在要本地编写文件代码和提交,维护管制自己的文件版本,然后这种“自娱自乐”的方式,意义不是很大,在这
-
 7.2 Verilog 文件操作
7.2 Verilog 文件操作主要内容:实例,实例,实例,实例,实例,实例,实例,实例,实例Verilog 提供了很多可以对文件进行操作的系统任务。经常使用的系统任务主要包括: 文件开、闭:$fopen, $fclose, $ferror 文件写入:$fdisplay, $fwrite, $fstrobe, $fmonitor 字符串写入:$sformat, $swrite 文件读取:$fgetc, $fgets, $fscanf, $fread 文件定位:$fseek, $ftell,
-
ionic 单选框操作
实例中,根据选中的不同选项,显示不同的值。 HTML 代码 JavaScript 代码 css 代码: 尝试一下 » 效果如下所示:
-
Pandas执行SQL操作
主要内容:SELECT,WHERE,GroupBy,LIMIT我们知道,使用 SQL 语句能够完成对 table 的增删改查操作,Pandas 同样也可以实现 SQL 语句的基本功能。本节主要讲解 Pandas 如何执行 SQL 操作。 首先加载一个某连锁咖啡厅地址分布的数据集,通过该数据集对本节内容进行讲解。 输出结果如下: SELECT 在 SQL 中,SELECT 查询语句使用 把要查询的每个字段分开,当然您也可以使用 来选择所有的字段。如下所示: 对
-
Pandas index操作索引
主要内容:创建索引,设置索引,重置索引索引(index)是 Pandas 的重要工具,通过索引可以从 DataFame 中选择特定的行数和列数,这种选择数据的方式称为“子集选择”。 在 Pandas 中,索引值也被称为标签(label),它在 Jupyter 笔记本中以粗体字进行显示。索引可以加快数据访问的速度,它就好比数据的书签,通过它可以实现数据的快速查找。 创建索引 通过示例对 index 索引做进一步讲解。下面创建一个带有 i
-
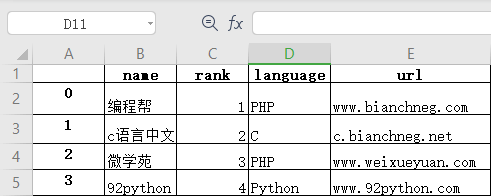 Pandas Excel读写操作
Pandas Excel读写操作主要内容:to_excel(),read_excel()Excel 是由微软公司开发的办公软件之一,它在日常工作中得到了广泛的应用。在数据量较少的情况下,Excel 对于数据的处理、分析、可视化有其独特的优势,因此可以显著提升您的工作效率。但是,当数据量非常大时,Excel 的劣势就暴露出来了,比如,操作重复、数据分析难等问题。Pandas 提供了操作 Excel 文件的函数,可以很方便地处理 Excel 表格。 to_excel() 通过 to_ex
-
Pandas concat连接操作
主要内容:concat(),append()Pandas 通过 concat() 函数能够轻松地将 Series 与 DataFrame 对象组合在一起,函数的语法格式如下: pd.concat(objs,axis=0,join='outer',join_axes=None,ignore_index=False) 参数说明如下所示: 参数名称 说明 objs 一个序列或者是Series、DataFrame对象。 axis 表示在哪个轴方向
-
Pandas merge合并操作
主要内容:使用how参数合并Pandas 提供的 merge() 函数能够进行高效的合并操作,这与 SQL 关系型数据库的 MERGE 用法非常相似。从字面意思上不难理解,merge 翻译为“合并”,指的是将两个 DataFrame 数据表按照指定的规则进行连接,最后拼接成一个新的 DataFrame 数据表。 merge() 函数的法格式如下: pd.merge(left, right, how='inner', on=
-
Pandas groupby分组操作
主要内容:创建DataFrame对象,创建groupby分组对象,查看分组结果,遍历分组数据,应用聚合函数,组的转换操作,组的数据过滤操作在数据分析中,经常会遇到这样的情况:根据某一列(或多列)标签把数据划分为不同的组别,然后再对其进行数据分析。比如,某网站对注册用户的性别或者年龄等进行分组,从而研究出网站用户的画像(特点)。在 Pandas 中,要完成数据的分组操作,需要使用 groupby() 函数,它和 SQL 的 操作非常相似。 在划分出来的组(group)上应用一些统计函数,从而达到
-
 Linux Vim基本操作
Linux Vim基本操作主要内容:Vim 打开文件,使用 Vim 进行编辑,Vim 保存退出文本《 Vim三种工作模式》一节给大家详细介绍了 Vim 的 3 种工作模式,本节来学习如何使用 Vim 编辑文件。 首先学习如何使用 Vim 打开文件。 Vim 打开文件 使用 Vim 打开文件很简单,例如在命令行模式下打开一个自己编写的文件 /test/vi.test,打开方法如下: [root@itxdl ~]# vim /test/vi.test 刚打开文件时 Vim 处于命令模式,此时文件的
-
Stream操作Collection集合
Java 8 还新增了 Stream、IntStream、LongStream、DoubleStream 等流式 API,这些 API 代表多个支持串行和并行聚集操作的元素。上面 4 个接口中,Stream 是一个通用的流接口,而 IntStream、LongStream、 DoubleStream 则代表元素类型为 int、long、double 的流。 Java 8 还为上面每个流式 API
-
Predicate操作Collection集合
Java 8 起为 Collection 集合新增了一个 removeIf(Predicate filter) 方法,该方法将会批量删除符合 filter 条件的所有元素。该方法需要一个 Predicate 对象作为参数,Predicate 也是函数式接口,因此可使用 Lambda 表达式作为参数。 如下程序示范了使用 Predicate 来过滤集合。 上面程序中第 11 行代码调用了 Colle
-
Cypress Github操作失败
我将GitHub操作用于CI/CD,并从中编写了一些cypress测试和YAML文件。但是当我推存储库时,我得到了一个错误。 失败的错误 我如何解决这个问题。当我在本地运行cypress时,它工作正常。
-
Spark嵌套RDD操作
我有两个RDD说 RDD2基本上是使用范围(intial_value、end_value、间隔)生成的。这里的参数可以变化。大小可以与rdd1相同或不同。这个想法是基于使用过滤Criertia的rdd2值将记录从rdd1提取到rdd2(rdd1的记录可以在提取时重复,正如您在输出中看到的那样) 过滤条件rdd1。创建 预期产出: 现在我想根据一些使用RDD2键的条件过滤RDD1。(如上所述)并返回
-
 RxJava 过滤操作符
RxJava 过滤操作符主要内容:RxJava 过滤操作符 介绍,RxJava 过滤操作符 示例RxJava 过滤操作符 介绍 以下是用于从 Observable 中选择性地发送信息的运算符。 运算符 描述 Debounce 仅在发生超时时才发送项目而不发送另一个项目。 Distinct 只发送独特的物品。 ElementAt 仅发出由 Observable 发出的 n 个索引处的项目。 Filter 只发出那些通过给定谓词函数的项目。 First 发出通过给定条件的第一个项目或第一个项目。