《GC》专题
-
C#析构函数即使在代码范围GC之后也没有调用?[重复]
我有一个简单的Nunit测试代码。VS2019下的net core 2.0: 它总是失败,而我最终发现i=0,析构函数在Test()之后被调用。但是你可以看到“t”在一个代码块中,在代码块之后是无效的,我也打了电话 在我的“断言”之前。 为什么即使在GC之后也不调用析构函数?如何修复代码以使测试通过? 谢谢。
-
c#:为什么GC不能在我的代码中收集Weakreference的目标?[副本]
我写了这段代码: 我期望得到这样的结果:是的,第一次不,第二次 但GC似乎没有收集到我的WeakReference的目标(joe)。结果是:是的,第一次是的,第二次 我的问题是什么?...我误解了弱引用吗?
-
C#GC不释放内存[重复]
我在C#上度过了一段糟糕的时光,在我不再引用它之后,没有为我保存在内存中的大型结构释放内存。 我在下面包含了一些代码,它们显示了与我遇到的问题类似的问题。我想我一定是误解了GC,因为我不确定为什么下面的代码会抛出内存不足异常。 有人知道为什么我包含的代码会丢失内存吗?没有一份名单被保留,可以立即清理。 谢谢, 保罗 复制:全新的4.5控制台应用程序,将代码粘贴到Main中。 异常将在for循环的第
-
为什么要调用GC。坚持到底,而不是一开始?[副本]
从: 在obj必须可用的指令范围的末尾而不是开始处编写此方法。 为什么它会有如此不直观的行为?
-
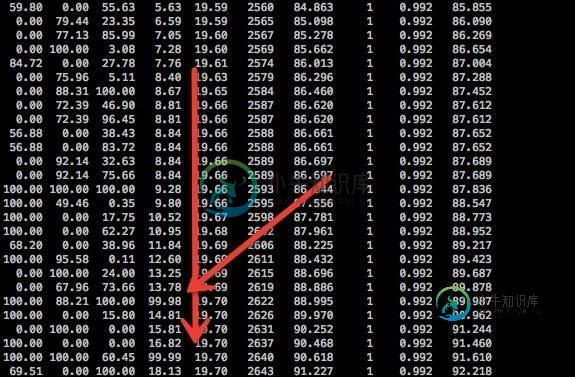 为什么在jstat-gcutil的结果中没有FullGC而是显示99%到14%的老一代?
为什么在jstat-gcutil的结果中没有FullGC而是显示99%到14%的老一代?jstat-gcutil,如下所示: 老一代从13.78到99.98,再到14.81,但FGCT总是1,为什么? 除了FullGC,还有其他原因造成这种情况? GC是CMS和JVM参数: -xms4096m-xmx4096m-xss256k-xx:permsize=256m-xx:maxpermsize=256m-xx:newssize=512m-xx:maxnewsize=512m-xx:sur
-
致命错误:python.h:没有此类文件或目录错误:命令“x86_64-linux-gnu-gcc”失败,退出状态为%1
我正在尝试安装mysqlclient,但我得到以下错误消息: _mysql.c:40:20:致命错误:python.h:没有终止此类文件或目录编译。错误:命令“x86_64-linux-gnu-gcc”失败,退出状态为%1
-
src/gevent/libev/corecext.c:95:20:致命错误:python.h错误:命令“gcc”失败,退出状态为1[重复]
在CentOS 7.7中,我安装了python3,我想通过pip3安装,但得到以下错误:
-
为什么Spark会在java.lang.OutofMemoryError:超过GC开销限制时失败?
我可能做了一些非常基本的错误,但我找不到任何关于如何从这一点上站出来的指针,我想知道我如何才能避免这一点。由于我是Scala和Spark的新手,我不确定问题是来自其中一个还是另一个,或者两者都有。我目前正在我自己的笔记本电脑上运行这个程序,它适用于数组长度不是很长的输入。提前谢了。
-
UseConcMarkSweepGC详细gc输出显示内存下降
我有一个应用程序,我已经为其启用了GC日志记录。堆似乎在增长,然后突然下降,但没有记录完整的GC。如果我可以启用一些启动参数,它将显示什么GC事件正在减小堆大小? 我的环境:Linux64位,java 1.6.0_31,JavaHotSpot(TM)64位服务器VM(build 20.6-b01,混合模式) 虚拟机参数: -Server -Xms2560m -Xmx2560m -XX: 使用图标标
-
c/c中gcc编译器是否保证将指向const数据的全局const指针放在单独的只读节中?
给定全局(或静态局部)变量的以下定义: ,我可以依赖这样一个事实吗,即ptr和初始化程序列表中的数据都将被放置到生成的目标文件的单独只读部分(即它不会被放置到. data或包含非const变量的类似部分)? 问题仅与所有架构/平台(至少存在只读内存的那些架构/平台)通用的 gcc c/c 编译器行为有关。它并不意味着任何平台,处理器,操作系统,链接器,启动运行时,库等。 请不要问我要做什么。我知道
-
如何在STM32上使用Eclipse/ gcc / ac6 / sw4stm32的自定义回调来重新定位printf?
我正在使用Eclipse/gcc/ac6/sw4stm32对stm32g071rb核进行编程,并且我在使用打印到SPI连接的显示器的自定义回调重新定位printf时遇到了一些困难。 现在,我的main看起来像这样: 我想做的是在重新定位的printf中使用我的display_write功能和显示目标。 我看到的选项有: > 使用__io_putchar函数:这可以从 syscalls.c 文件中导
-
MinGW GCC:"未知的转换类型字符' h'" (snprintf)
好的,我在Windows 7上使用MinGW(GCC 4.6.2)编译C文件时遇到了一个奇怪的问题。有问题的文件包含以下C代码: 编译结果是这样的: 现在,对我来说奇怪的是,它抱怨第6行的调用,而不是第4行的调用。我是错过了什么还是警告不正确?此外,是否有更好的格式字符串等效项?(我正在尝试将char变量打印为十六进制值。)
-
GCC 5.4.0的一个昂贵的跳转
-
Firebase存储安全规则桶通配符会影响项目中的其他GCS桶吗?
假设您可以在Firebase存储安全规则中提供bucket通配符,例如: 这里声明的规则是否可能覆盖来自同一Google Cloud项目的GCS bucket的规则(如公共读取)?具体地说,在Firebase Storage browser中创建的规则是否会影响同一项目中的其他(即非Firebase)GCS桶? 一个例子: Firebase存储的规则会导致无意中获得公共读取权限吗?
-
有没有办法在GCP中排队批处理数据流作业?
长话短说,我有一个cron工作,每天在指定的时间将一堆文件上传到云存储桶中。所有这些bucket都有一个关联的发布/订阅通知主题,该主题在文件创建事件时触发。每个事件都会触发一个数据流作业来处理该文件。 问题是这会在几秒钟内实例化100个并行批处理作业。每个作业都会使用HTTP请求来关闭我的下游服务。这些服务无法足够快地扩展,并开始抛出连接拒绝错误。 为了限制这些请求,我限制了每个数据流作业的可用