《同步调用》专题
-
volley如何在android中同步工作[副本]
volley库如何在Android中同步工作?我想当volley从服务器得到响应的时候,程序的执行停止并等待volley的结果。
-
同步和通知执行顺序和范围
-
Android Studio 3.0 Canary 5中的Gradle同步失败
这是我的构建。gradle(项目:MyProjectName)文件: 下面是构建。gradle(模块:应用程序): 这是错误消息: 此意外错误的可能原因包括: Gradle的依赖项缓存可能已损坏(这有时会在网络连接超时后发生。)重新下载依赖项和同步项目(需要网络) Gradle构建进程(守护进程)的状态可能已损坏。停止所有Gradle守护进程可以解决此问题。停止Gradle生成过程(需要重新启动)
-
Gradle与“找不到可选库”同步失败
从google文档: 要继续使用Apache HTTPAPI,必须首先在build.gradle文件中声明以下编译时依赖项: 我尝试了这篇文章中提到的建议,但它们不起作用。与android Studio1.5和2预览结果相同。 将和更改为22。还有23.0.1、23.0.0、22.0.1版本的buildToolsVersion。
-
同步数据读/写到/从主存储器
当同步方法完成时,它将仅将其修改的数据推送到主内存,还是将所有成员变量(类似地,当同步方法执行时,它将仅从主内存中读取所需的数据,还是清除缓存中的所有成员变量并从主内存中读取其值?例如 在上面的代码中,假设计算由 threadA 执行,getResult 由 threadB 执行。执行计算后,线程 A 将使用 a 和 b 更新主内存,还是会更新 a、b、c 和 d。在执行 getResult 之前
-
将Infinispan缓存条目与数据库同步
我想知道是否可以使用Infinispan与Oracle数据库进行缓存数据同步。这是我的场景。我有两个主要的应用程序。一个是高度并发使用的应用程序,另一个用作管理模块。由于它是高度并发的,我希望减少数据库连接(将实体加载到缓存(读写启用)中,并在不调用数据库的情况下从此处使用它)。但同时我想根据缓存的变化更新数据库,因为管理模块直接使用数据库。那个更新过程(缓存到数据库)能在实体级处理而不涉及应用程
-
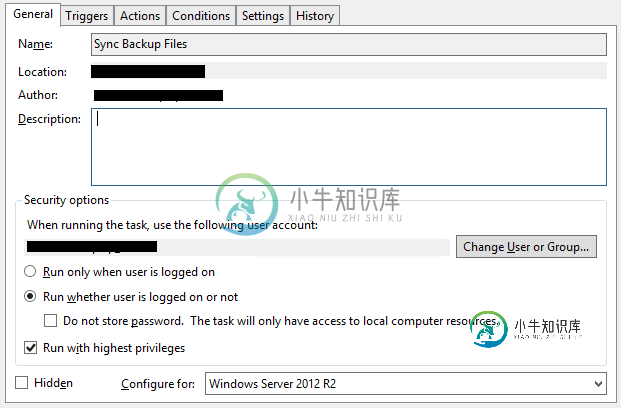 AWS同步s3 Windows计划任务返回0x1
AWS同步s3 Windows计划任务返回0x1我创建了一个windows计划任务来运行< code>aws命令,以将本地文件夹同步到S3存储桶。该任务运行一个. bat文件。如果。蝙蝠是手动运行的,它运行良好。当它通过任务运行时,我得到一个0x1作为最后的运行结果。 按照这里找到的建议,我的bat文件如下所示: 在是文件夹。 我的任务是这样的: 正在使用的帐户是管理员帐户,已经成功运行其他计划任务并且任务中的路径是正确的。
-
Java中同步关键字的记忆效应
这个问题以前可能已经回答过了,但是由于这个问题的复杂性,我需要一个确认。所以我重新措辞这个问题 问题1:当一个线程进入一个同步块时,内存屏障将包括被触摸的任何字段,而不仅仅是我同步的对象的字段?因此,如果在一个同步块中修改了许多对象,那么在线程内存缓存之间会有大量内存移动。 问题 2 : 在线程 1 中隐式地是“发生前”关系的一部分? 我希望是这样,但可能不是这样。如果没有,有没有一个技巧可以让它
-
web服务手册同步后RecyclerView未刷新
在手动同步web服务后,我遇到了RecyclerView无法刷新的问题。手动同步是通过在列表上向下滑动或点击ActionBar项目触发的。手动同步使用截取请求以JSON格式检索数据,数据被解析并保存到SQLite数据库表中。同步日期时间也会保存到SQLite数据库表中,然后显示在片段的ActionBar字幕中。截击请求通过WorkManager OneTimeWorkRequest启动。 问题是没
-
如何将项目与Android Studio同步到GitHub?
我正在尝试将我在Android Studio文件夹中的一个项目同步到GitHub,但我不完全确定除了在选项菜单中添加凭据之外该做什么。有人能给我一个快速的向导吗?
-
基于参数(名为mutex/lock)的Java同步
我正在寻找一种基于方法接收到的参数来同步方法的方法,如下所示: 我希望基于参数同步方法,如下所示: 线程1:做某事(“A”); 线程2:doSomething(“B”); 线程3:doSomething(“C”); 线程4:做某事(“A”); 线程1、线程2和线程3将在没有同步的情况下执行代码,但是线程4将等待线程1完成代码,因为它具有相同的“a”值。 谢谢 更新 基于Tudor的解释,我认为我面
-
reduce操作中并行流的同步问题
我正在尝试使用并行流连接字符串。 我在下面的代码中也发现了同样的问题。 在这里,我还使用了一个同步集合,所有的方法都是线程安全的。 我在Java文档中看到了这个 我是不是漏掉了什么?使用线程安全的数据结构还不够吗?
-
Android Studio Gradle同步失败-不支持的Java
我在Linux (Arch Linux)上,用的是Android Studio 2.3.1 在Android Studio中创建新的空项目时,我得到错误消息: 似乎爪哇版本有一些东西。我已经安装了 openjdk-8,并且还尝试了 Oracle JDK 版本 8(也尝试了版本 7)。 我尝试过的事情: > < li> 使用已安装的gradle或Android Studio附带的gradle 删除
-
如何在暴风雨中制作同步Kafka
我试图使Kafka消费者同步消费Kafka的消息。 我遇到的实际问题是消息队列存储在Storm Spout中。 我想做的是让暴风雪等待Kafka的回复,然后让暴风雪消耗下一条信息。 我正在使用Storm KafkaSpout: 我已经更新到Storm 2.0.0,我使用Storm kafka客户端。但是如果我将Storm队列配置为50:
-
多服务器中的数据事务同步
目前,我的java应用程序在多个服务器中运行。我有一个数据事务遇到死锁。我尝试使用线程和同步,但徒劳无功,因为多个服务器中有多个应用程序实例。每个应用程序实例都同步了其数据事务,但同一数据库上的不同同步应用程序事务恰好使数据库陷入死锁状态,因为对于所有应用程序实例,数据库是相同的,并且是一个。 在这种情况下,请提出正确的方法。任何高级解决方案也就足够了。