《内存淘汰》专题
-
express.static()是否在内存中缓存文件?
问题内容: 在ExpressJS for NodeJS中,我们可以执行以下操作: 提供所有静态CSS,JS和图像文件。我的问题是: 1)当我们这样做时,Express是否会在每次提供一种资源时自动在服务器内存中缓存文件,还是从硬盘上读取文件? 2)执行此操作时,Express是否默认使用ETag将资源保存在客户端的硬盘上或仅在客户端的内存上? 问题答案: 静态中间件不进行服务器端缓存。它使您可以执
-
如何在WAMP中启用内存缓存
问题内容: 如何在WAMP中安装内存缓存? 我在中找不到任何php_memche 。 现在我该怎么做? @瑞安 感谢您的步骤,现在在WAMP中启用了内存缓存,我也已经在PHPINFO中进行了交叉检查。正在显示内存缓存。 我已经尝试过以下示例Memcache示例。但是抛出错误。 收到以下通知错误。 我错过了… 问题答案: 以下是对我有用的步骤: 所需文件 直接链接 Windows DLL文件 适用于
-
ORA-27101:共享内存领域不存在
问题内容: 我启动oracle时遇到此错误。我检查了Oracle Home和SID。一切设置正确。 ORA-27101:共享内存领域不存在 请帮助我找出解决方案。提前致谢 问题答案: 该错误通常表示没有Oracle实例(进程)可连接。有人需要登录并启动实例。
-
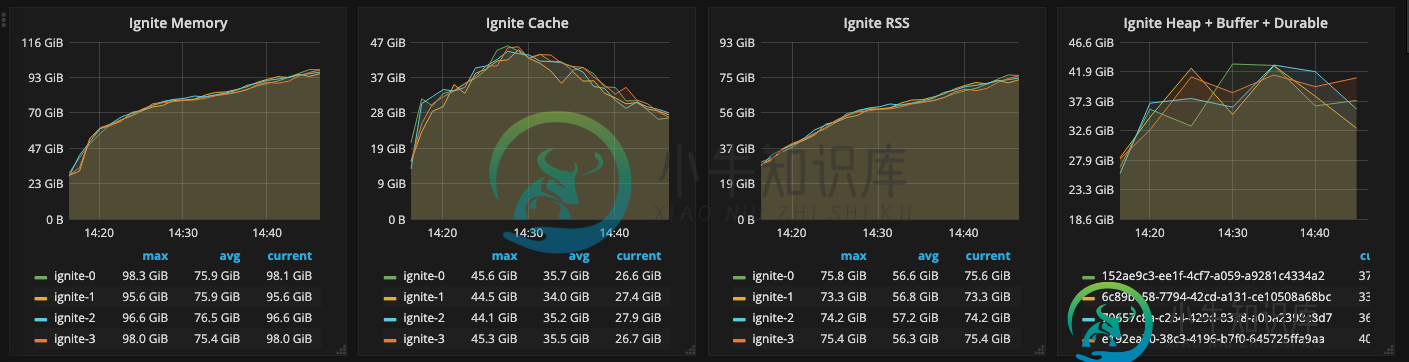 Ignite DataStreamer中可能存在内存泄漏
Ignite DataStreamer中可能存在内存泄漏我正在启用持久性的Kubernetes集群中运行Ignite。每台机器都有一个24GB的Java堆,20GB专用于持久内存,内存限制为110GB。我的相关JVM选项是。在每个节点上运行DataStreamer数小时后,我的集群上的节点达到了它们的k8s内存限制,触发了OOM杀机。运行Java NMT后,我惊讶地发现分配给内部内存的空间数量巨大。 Kubernetes metrics证实了这一点:
-
Apache Ignite中可能存在内存泄漏?
我试图将Ignite用作键值对的内存数据库,其值范围从50MB到800MB不等。看起来Ignite通过JVM分配堆空间,它从不清理,即使缓存条目离开堆,被清除,没有连接的客户机和运行的操作。我的机器将无法处理这样的内存消耗,因此我正在寻找一种方法来清理一些内存。 我的测试场景如下: null 我正在使用pyignite瘦客户机,通过python脚本在本地测试Ignite: 该脚本将800 MB的数
-
JDBC bulkcopy中可能存在内存泄漏
我正在编写一个spring boot 2应用程序,我正在使用SQL批量复制功能在SQL Server2012数据库中插入几条记录。每插入700行,我就有600 MB的泄漏 我已经试用了Microsoft驱动程序版本6.4.0.jre8和7.2.2.jre8,但任何东西都改变了。我尝试为tomcat更改Hikari连接池,但结果是一样的。 为了调用Microsoft API,我使用了包装器框架(ht
-
第2章 理解 Memcached 的内存存储
上一章的文章介绍了 Memcached 是分布式的高速缓存服务器。本次将介绍 Memcached 的内部构造的实现方式,以及内存的管理方式。另外 Memcached 的内部构造导致的弱点也将加以说明。 2.1 Slab Allocation 机制:整理内存以便重复使用 最近的 Memcached 默认情况下采用了名为 Slab Allocator 的机制分配、管理内存。在该机制出现以前,内存的分配
-
JNI的Java内存管理
问题内容: 我有两个问题: 如果我有对方法的JNI调用而JNI方法泄漏内存该怎么办。此方法完成后,JVM垃圾收集器将能够取回该内存。我听说JVM不管理JNI使用的堆空间吗?但是JNI使用的内存是Java进程使用的内存的一部分吗? 使用JNI来实现IPC是否绝对必要?还有哪些其他流行的Java技术?或者是否有一个开放源代码库来实现Java共享内存? 问题答案: 否:“ JNI框架不为在本机端执行的代
-
Redis Pub子通道内存
问题内容: 在pub- sub的情况下,Redis使用什么机制将消息保留在内存中?如果没有客户端订阅,消息将如何处理?Redis会缓冲它们吗?有没有一种配置最小值的方法。和最大 每个通道分配的内存? 问题答案: 在实现(x)中可以看到,Redis不会在Pub / Sub上下文中将消息保留在内存中: 邮件会发送给监听该频道的客户端(如果有), 该消息将发送给正在侦听匹配频道(如果有)的客户端。 然后
-
socket.io redis和内存泄漏
问题内容: 我的socket.io版本是socket.io@0.8.7和redis@0.7.1。我在Windows上。 在某些地方,我已经看到问题已解决。我想我正在使用最新的socket.io版本。什么是generator.setMaxListeners(),在哪里可以设置? 我正在使用redis pubsub,当我订阅redis时,它会抛出此警告。 问题答案: 有一个与此相关的已知问题。好像是几
-
在Python中释放内存
问题内容: 在以下示例中,我有一些有关内存使用的相关问题。 如果我在解释器中运行, 我的机器上使用的实际内存最高为80.9mb。那我 实际内存下降,但仅限于。解释器使用基线,因此不向 释放内存有什么好处?是否因为Python正在“提前计划”,以为你可能会再次使用那么多的内存? 它为什么特别释放- 释放的量基于什么? 有没有一种方法可以强制Python释放所有已使用的内存(如果你知道不会再使用那么多
-
Java MySQL JDBC内存泄漏
问题内容: 好的,所以我的程序有很多(〜300)线程,每个线程都与中央数据库通信。我创建了一个与数据库的全局连接,然后每个线程进行其业务创建语句并执行它们。 一路上的某个地方,我发生了大量内存泄漏。在分析堆转储之后,我看到com.mysql.jdbc.JDBC4Connection对象为70 MB,因为它在“ openStatements”(哈希映射)中有800,000个项目。在某个地方,它不能正
-
Java获取可用内存
问题内容: 有什么好的方法可以在运行时将剩余的内存提供给JVM?这种情况的用例是使Web服务在接近内存限制时通过拒绝一个新的错误消息“太多的人使用此,请稍后再试”,而不是因OutOfMemory错误而突然死亡而接近失败,从而正常失败。 注意,这与事先计算/估算每个对象的成本无关。原则上,我可以根据该估算值估算对象占用并拒绝新连接的内存量,但这似乎有点hacky /脆弱。 问题答案: 这是该主题给出
-
python中的内存错误
问题内容: 当我尝试运行以下程序时,出现了以上错误。有人可以解释什么是内存错误,以及如何解决此问题?。 该程序将字符串作为输入,并找到所有可能的子字符串,并从中创建一个集(按字典顺序),并应在用户要求的相应索引处打印值,否则应打印“无效” 问题答案: 这一个在这里: 对于大型字符串,这似乎非常低效且昂贵。 做得更好 缓冲区对象保留对原始字符串以及开始和长度属性的引用。这样,不会发生不必要的数据重复
-
Java:高效内存的ByteArrayOutputStream
问题内容: 我的磁盘中有40MB的文件,我需要使用字节数组将其“映射”到内存中。 最初,我认为将文件写入ByteArrayOutputStream是最好的方法,但我发现在复制操作期间的某个时刻它会占用约160MB的堆空间。 有人知道不使用三倍于RAM的文件大小的更好方法吗? 更新: 感谢您的回答。我注意到我可以减少内存消耗,告诉ByteArrayOutputStream初始大小比原始文件的大小稍大