《hash》专题
-
如何按值对HashMap进行排序,但同时保持重复项的顺序?
有没有办法保留重复订单,或者至少当它找到重复订单时,把它放在价值相等的订单后面?
-
使用pbkdf2的SALT和HASH
我使用以下方法从NodeJS中的crypto lib创建加盐和散列密码: 对于randomBytes调用(创建SALT)我应该使用多大的大小?我听说过128位的盐,可能最多256位。看起来这个函数使用的是字节大小,那么我可以假设32(256位)的大小就足够了吗? 对于pbkdf2调用,什么是好的迭代次数,什么是好的密钥长度(keylen)?
-
Swagger HashMap属性类型
是否有任何方法可以在模型部分定义HashMap或泛型对象类型?我有一个返回产品的REST服务,这些产品可以有不同的选择。options属性基本上是一个HashMap,其中id是选项名,其值是选项值。
-
使用 boost::hash with boost::p roperty_tree?
我正在尝试为包含提升::property_tree(
-
使用线性探测实现Hashtable时调整大小的权衡
我正在尝试使用线性探测实现一个哈希表。 在将(键、值)对插入哈希表之前,我想检查它是否已满一半。如果是,我需要将底层数组的大小增加一倍。 显然,有两种方法可以做到这一点: 一种是创建另一个大小加倍的数组,重新刷新旧数组中的所有条目,并将它们添加到新数组中。然后,将旧阵列重新绑定到新阵列。这种方法易于实现,但占用了大量空间。 另一种方法是将阵列加倍,并在适当的位置进行重新灰化。这种方式可能会导致更长
-
迭代HashMap时引用局部变量->从lambda表达式引用的局部变量必须是final或实际上是final错误
今天我想做一些我想完成的项目,在那里我得到了一个异常,我不能从lambda表达式中引用局部变量。我有一个方法,其中我给出了两个值,该方法检查值对是否已经在HashMap中 当它结束时,我想读出布尔函数,需要知道他是否发现它成立= false我怎样才能在这个lambda中设置founded或者有没有其他方法可以做到这一点?
-
JavaScript:将对象数组转换为hashmap
我在数组中有一组值,每个值都有一个和。 一旦我有了值数组和类型控制台和,输出是: 如何将这些值存储在哈希映射中,如键值(ID-LABEL)对,并将其存储在json中?
-
带Spring Boot路由URL的Angular 4使用hashcode
下面是我的场景: 我正在使用带有Angular 4的Spring boot 我正在使用angull-cli生成构建文件,并将其放在resource-static文件夹下。 运行my pom.xml时,所有静态文件夹都在target-->Project文件夹-->WEB-INF-->Classes-->静态文件夹(预期)下复制 每次单击整个/整个URL都不会改变。如果我使用以下配置: `@配置公共类
-
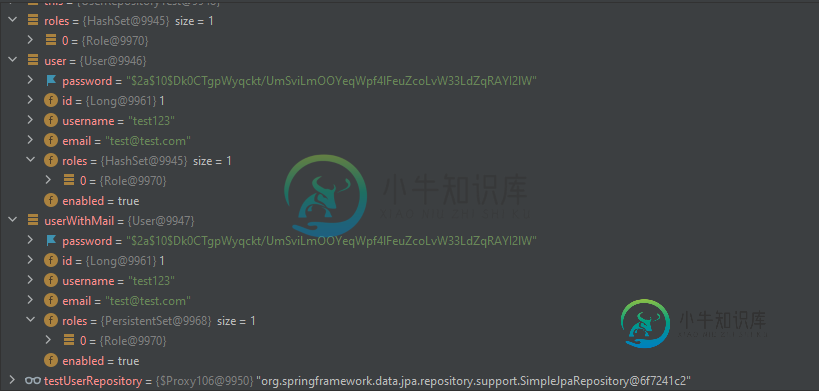 Spring数据测试-两个相同的对象返回另外两个hashcode
Spring数据测试-两个相同的对象返回另外两个hashcode我试图通过@datajpatest测试我的Spring存储库。我想通过电子邮件找到完全相同的用户,但我得到了另一个角色集。 首先,如果我开始我的项目,然后我设置测试用户和他的角色。 将保存用户的UserService中的一段代码。 在测试中比较对象是好主意,还是例如用户名/电子邮件就足够了?
-
从Hashmap填充JList并检索键
我如何从一个HashMap填充JList而只在列表中显示值呢?
-
使用HashMap填充TableView,该HashMap将在HashMap更改时更新
我跟踪过这个帖子 用tableview绑定hashmap(JavaFX) 并创建了一个由HashMap中的数据填充的TableView。 通过从创建并将该传递给的构造函数,从称为的接收其数据。(代码如下) 但是,尽管它是一个,带有,但当对基础HashMap进行更改时,TableView不会更新。 下面是我的代码: 这正是将hashmap与tableview(JavaFX)绑定的代码,只是我添加了以
-
如何创建包含optional的hashmap,当检索它时,会给我值或optional。空,但有限制
如何创建一个包含可选的hashmap,当检索时,它会给我值或Optional.empty?但是,我不允许检查null、Optional.empty()或使用,,。 对于<代码>可选 例如,<代码>。获取(“John”)。平面图(x-
-
基于输入将WebClient并行调用的批处理结果转换为HashMap条目,而不阻止每个单独的调用
我想将Mono从WebClient响应转换/添加到以输入为键的映射中 我正在使用WebClient并行执行一批REST调用,但是我不想返回用户列表,而是想返回一个ID的HashMap作为键,从REST调用返回的用户作为值。 我不想在添加到HashMap之前阻止每个单独的调用来获取值。 有没有一种方法可以将结果从WebClient转换为HashMap条目,而不会影响REST调用的并行执行? 我尝试了
-
如何用Lambda将List的List转换为Java中的Hashset[duplicate]
我有一个包含用户数据的类。 从中,我想提取所有唯一的城市。改变,我为此而做, 这些变化的表达式是什么? 任何帮助都将不胜感激。
-
HashMap与Switch语句性能
HashMap本质上具有O(1)性能,而开关状态可以具有O(1)或O(log(n)),具体取决于编译器是否使用表开关或查找开关。 可以理解,如果switch语句是这样写的, 然后,它将使用一个表开关,显然比标准HashMap具有性能优势。但是如果switch语句是稀疏的呢?这是我要比较的两个例子: . 什么会提供更多的吞吐量,查找开关还是HashMap?HashMap的开销是否会在早期给查找开关带