《数据恢复》专题
-
 3.1腾讯游戏数据,数据开发一面
3.1腾讯游戏数据,数据开发一面先自我介绍 我看你是Java ,c和c++了解吗?(只在本科学过c基础,没有实际开发过 平时用windows 还是Linux开发?(win写代码,部署需要用Linux Linux 关于网络和查询命令用过哪些?(ps Grep 查看运行程序,docker 的命令,还有nohup 这种,网络防火墙的firewall 有用过查看网络状态,网络接口之类的命令吗?没有 那你说一下哪个命令?忘了,我都没记
-
mysql源码解读——数据到文件之数据
主要内容:一、数据,二、数据写入,三、源码分析,四、总结一、数据 数据库落盘前面讲了日志,今天分析一下数据的落盘,麻烦的很。但是原理都差不多。在前面的分析已经可以明确知道,在MySql中,不管哪种数据,都是先进入缓存,然后再落盘保存。而在数据库,最重要的是什么?当然是数据,不管你是什么2PC,什么缓存,什么线程等等。最终的目的都是保证数据的安全应用。说的直白一些,就是满足各种SQL语句的操作,支持数据的各种恢复备份以及数据库的迁移。马Sir不是说过,以
-
 求中证数据数据技术岗面经😭
求中证数据数据技术岗面经😭#面经# #中证数据#
-
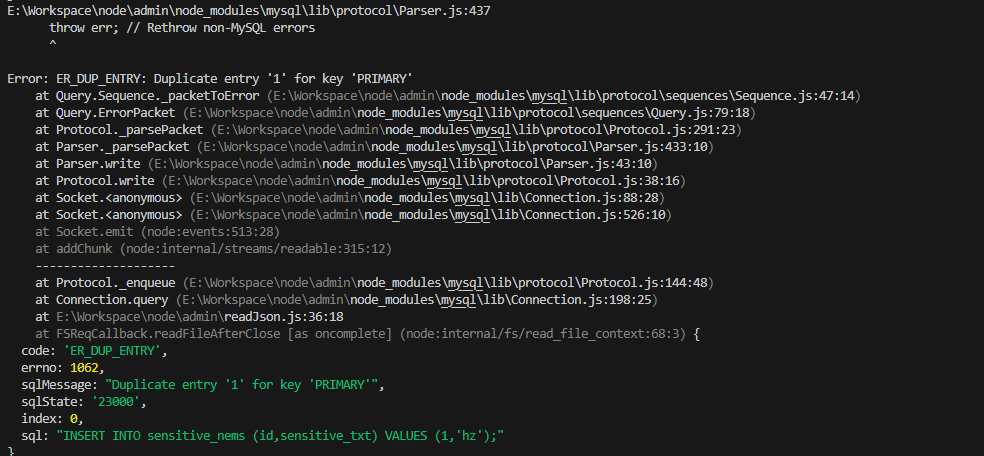 node.js - nodejs往数据库插入数据的问题?
node.js - nodejs往数据库插入数据的问题?拿到了一份敏感词的json文件,想通过nodejs循环插入数据库中 但是每次都会报错,不知道是怎么回事,有大佬帮忙看看呗 报错 设计的表
-
 一面数据-数据分析实习生面经
一面数据-数据分析实习生面经写在前面:这个岗位重视可视化的能力,在去年一战失败后也投过这个岗位的正职,面试前和面试中都在问有没有相应的可视化作品,对于实习生希望熟悉sql和tableau,一来就可以干活 1.自我介绍 2.对于以往实习经历和项目浅挖 3.次日留存sql代码考察 4.询问了不了解窗口函数 5.利用窗口函数计算不同品类前十GMV 6.tableau和power bi知识点考察 -技术问题一直准备的sql,DAX公
-
将数据帧转换为Numpy数组?[重复]
我有这个数据框 我想转换这种形式的Numpy数组: 我正在使用转换为_矩阵函数,并在它重塑(1,4)后使用,但它不起作用!!它给我的格式是:有什么建议吗?我需要把它转换成那种格式,这样我就可以应用“精确回忆曲线”功能。
-
SQLite3增量每个重复数据计数1
我是sqlite3的新手。我通过python在SQLite中导入了一个导出的CSV文件,其中列出了来自Splunk的IP地址,我计划在每次识别类似的IP地址时增加数据库中的count列。 我的想法是使用SQLite CASE语句,留档,更新语句等。 也试过, 我知道我错了,我好几天都搞不清楚这个问题。下面是我的sqlite3数据库在cmd提示符中的样子: 我会继续寻找解决方案。感谢您的反馈!
-
在react[重复]中传输数据的函数
我是新的反应,我有一个问题,如何获得另一个组件的onclick值。
-
计算海量数据的中位数[重复]
我有大量的数据( 另外,是否是合适的数据结构?或者另一种数据结构会提供更好的复杂性 注意:我不能使用,因为如果使用,也可能存在重复项。查找中值将增加复杂性,因为我将从开始到中间循环以获取其值。
-
数据库表名称是单数还是复数?[复制]
问题内容: 这个问题已经在这里有了答案 : 11年前关闭。 精确重复 表命名难题:单数与复数名称 使用单数或复数数据库表名称更好吗?有公认的标准吗? 我听到有人支持和反对它,你们怎么看? 问题答案: 恕我直言,表名称应像客户一样是复数形式。 如果类名映射到“客户”表中的一行,则其名称应与“客户”一样为单数形式。
-
从具有多个数据库的实例中复制单个Redis数据库
问题内容: 我有一个Redis实例,其中有两个数据库。现在,我想设置第二个实例并复制第一个实例,但是第二个实例应该仅具有一个数据库,并且仅复制第一个实例中的db 0。当我尝试执行此操作(为第二个实例设置)时,我在Redis日志文件中收到以下错误消息: 我尝试使用redis-dump,但是尝试将生成的转储导入新实例时出现错误。(我认为与2 dbs和1 db无关,而是redis-dump中的一个错误,
-
保留多语言数据的最佳数据库结构是什么?[重复]
问题内容: 这个问题已经在这里有了答案 : 8年前关闭。 可能重复: 多语言数据库的架构 这是一个例子: 问题: 每种新语言都需要修改表结构。 这是另一个例子: 问题是: 每种新语言都需要创建新表,并且每个表中都有“价格”字段重复。 这是另一个例子: 问题: 难吗? 问题答案: 您的第三个示例实际上是通常解决问题的方式。努力,但可行。 从翻译表中删除对产品的引用,然后将翻译的引用放在您需要的地方(
-
UDP数据包是否可以分为多个较小的数据包[重复]
如果UDP数据包超过MTU,它能被分割成几个更小的数据包吗?看起来MTU碎片是关于IP层的,所以我认为它可以。 如果是,为避免碎片,建议通过UDP发送的最大数据包大小是多少?为什么?
-
MySQL中复制数据表中的数据到新表中的操作教程
本文向大家介绍MySQL中复制数据表中的数据到新表中的操作教程,包括了MySQL中复制数据表中的数据到新表中的操作教程的使用技巧和注意事项,需要的朋友参考一下 MySQL是不支持SELECT … INTO语法的,使用INSERT INTO … SELECT替代相同用法,下面我们我们这里简答分一下新表存在和不存在两种情况,具体使用不同的语句。 1.新表不存在 复制表结构即数据到新表 这种方法会将ol
-
数据['col']。values中的字符串,但数据['col']中的字符串[重复]
问题内容: 这个问题已经在这里有了答案 : 如何确定Pandas列是否包含特定值 (9个答案) 3年前关闭。 我已经从文件中读取了一个熊猫数据框: 当我尝试时,它会返回,但是当我尝试时,它会返回(这就是我在这种情况下的预期)。 我不明白为什么会有行为上的差异。我读到返回列的Numpy表示形式,但是为什么返回? 谢谢! 问题答案: 熊猫系列就像字典。 搜索其索引(或键),然后 检查字符串是否在该Se