《数据备份》专题
-
需要数据库事务来读取数据吗?
问题内容: 当我尝试从数据库中读取数据时,至少使用 抛出异常表示不存在事务。 当我添加注释时: 它工作正常。 但是,由于读取和访问数据每秒将发生百万次,因此我想确保不会不必要地阻塞我们的环境。 如果不是,创建只读事务的成本是多少? 我不能在没有事务的情况下结合Spring创建Hibernate Criteria Query吗? 问题答案: 所有数据库语句都在物理事务的上下文中执行,即使我们没有显式
-
 调用MySQL中数据库元数据的方法
调用MySQL中数据库元数据的方法本文向大家介绍调用MySQL中数据库元数据的方法,包括了调用MySQL中数据库元数据的方法的使用技巧和注意事项,需要的朋友参考一下 MySQL的三个信息: 查询的结果有关的信息: 这包括由任何SELECT,UPDATE或DELETE语句产生数量的记录。 表和数据库有关的信息: 这包括表和数据库的结构有关的信息。 MySQL服务器的信息: 这包括当前状态的数据库服务器,版本
-
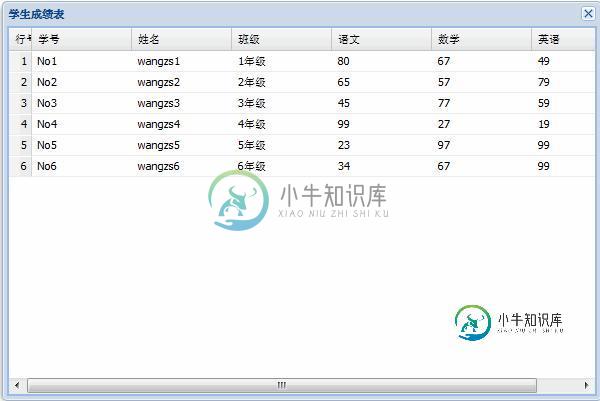 extjs_02_grid显示本地数据、显示跨域数据
extjs_02_grid显示本地数据、显示跨域数据本文向大家介绍extjs_02_grid显示本地数据、显示跨域数据,包括了extjs_02_grid显示本地数据、显示跨域数据的使用技巧和注意事项,需要的朋友参考一下 1.显示表格 2.显示本地数据 3.显示跨域jsonp数据
-
MySQL数据透视表的列数据作为行
问题内容: 我正在努力寻找解决此MySQL问题的方法。我似乎无法理解该怎么做。我有下表。 如果可能的话,我想将问题答案显示为每个结果集的列,如下所示。 任何帮助将非常感激。 谢谢 问题答案: SQLFiddle演示 如果您不清楚问题的数量( 例如Matei Mihai所说的1000个 ),则非常需要动态版本。 SQLFiddle演示 输出值
-
码头数据源,休眠,未找到数据源
问题内容: 我正在尝试在Jetty 7.4中配置数据源。我可以使用Tomcat context.xml中的Web应用程序成功完成此操作。 这就是我在jetty.xml中的内容(这将是该码头实例中的唯一应用程序,因此我不介意在服务器范围内使用数据库连接-我宁愿不必在战争中进行配置) 。它位于最后一个上方的最底部: 在我的Web应用程序的WEB-INF / web.xml中: 最后,在我的hibern
-
kafaka 生产数据时数据的分组策略
本文向大家介绍kafaka 生产数据时数据的分组策略相关面试题,主要包含被问及kafaka 生产数据时数据的分组策略时的应答技巧和注意事项,需要的朋友参考一下 生产者决定数据产生到集群的哪个 partition 中 每一条消息都是以(key,value)格式 Key 是由生产者发送数据传入 所以生产者(key)决定了数据产生到集群的哪个 partition
-
使用javascript / AJAX将数据插入MySQL数据库
问题内容: 我使用Google Maps API制作了一个非常简单的页面,其中有几个字段,用户将在其中放置一些数据。看起来像- http://aiworker2.usask.ca/marker_field_db.html 我要做的是使用javascript / Ajax将数据存储到MySQL数据库中。我发现了几个使用Jquery的示例。我是这个javascript / Ajax / Jquery平
-
使用javascript Onclick将数据传递到数据库
问题内容: 对于javascript / ajax,我是一个真正的菜鸟,因此对您的帮助将非常感激 但主要关注菲尔·萨克雷留下的答案。我想知道是否有人可以详细说明我们如何(如果可以的话)使用jquery通过他的示例传递值/数据。他留下的代码示例如下: 例如,我们要使用php将任意数量的值传递给数据库,有人可以给我一个有关javascript函数所需内容的摘要示例吗?或详细说明上面发布的内容? 再次谢
-
PyTorch数据集/数据加载程序批处理
对于在时间序列数据上实现PyTorch数据管道的“最佳实践”,我有点困惑。 我有一个HD5文件,我使用自定义DataLoader读取。似乎我应该返回数据样本作为一个(特征,目标)元组,每个元组的形状是(L,C),其中L是seq_len,C是通道数-即不要在数据加载器中预制批处理,只需返回一个表。 PyTorch模块似乎需要一个批处理暗淡,即。Conv1D期望(N,C,L)。 我的印象是,类将预先处
-
无法从Firebase实时数据库获取数据
我正在尝试获取我的用户名,并在应用程序打开时向他/她问好。但我无法根据某个用户的uid获取数据。当我运行应用程序时,祝酒词从未真正出现。 数据库结构 密码
-
无法从Firebase实时数据库检索数据
我试图显示一个零件的"loc",如果它的零件号我给。以下是数据结构的样子: 活动代码: getLoc是Product类的getter函数,它返回给定curP对应的“loc”。curP部分表示子值。 逻辑对我来说似乎是正确的,但我没有得到输出。我哪里出了问题?
-
Spring Boot 1数据库多个数据库用户
我目前正在构建一个访问数据库的restful API(带有Spring Boot)。此应用程序最终将托管在服务器上。 我想做的事情: 配置多个用户的数据库,并为他们分配不同的权限到不同的表 根据调用的endpoint,使用特定用户在该函数中执行该查询 如何配置上述应用程序? 到目前为止,我找到的答案涉及到配置多个数据源,但是对于上面的应用程序,只有一个数据源,但是有多个用户。 我已经阅读了以下链接
-
Spark数据集/数据帧连接空倾斜键
使用Spark Dataset/DataFrame联接时,我面临长时间运行且OOM作业失败的问题。 以下是输入: ~10个不同大小的数据集,大部分是巨大的( 经过一番分析,我发现作业失败和缓慢的原因是歪斜键:当左侧有数百万条记录时,用连接键。 我用了一些蛮力的方法来解决这个问题,这里我想和大家分享一下。 如果您有更好的或任何内置的解决方案(针对常规Apache Spark),请与他人分享。
-
数据库 - 一次提交写入多条数据?
我希望一次提交一条内容,但这条内容里面根据特定字符自动分割成多条记录写入ac数据库。用asp程序。请问可以实现吗? 举例: 我提交如下一段内容,里面用开头和结尾字样来分割,希望入库4条记录(同一个表单只提交一次,入库4条)。对了,数据库有两个字段(内容和时间)。如下例子。 开头 这里是要入库的内容1 时间 结尾 开头 这里是要入库的内容2 时间 结尾 开头 这里是要入库的内容3 时间 结尾 开头
-
第四章-数据序列化和模块数据
Most Odoo configurations, from user interfaces to security rules, are actually data records stored in internal Odoo tables. The XML and CSV files found in modules are not used to run Odoo applications