《缓存穿透》专题
-
Redis与Disk在缓存应用中的性能比较
有趣的是,雷迪斯的表现并不是那么好。要么是Python做了一些神奇的事情(存储文件),要么是我的redis版本慢得惊人。 我不知道这是不是因为我的代码的结构方式,或者什么,但我希望redis做得比它做得更好。 为了制作一个redis缓存,我将我的二进制数据(在本例中是一个HTML页面)设置为一个从文件名派生的密钥,过期时间为5分钟。 在所有情况下,文件处理都是用f.read()完成的(这比f.re
-
如何实现缓存友好的动态二叉树?
根据包括维基百科在内的几个来源,实现二叉树最常用的两种方法是: 每个节点显式保存其子节点的节点和指针(或引用) 子节点的位置由其父节点的索引隐式给定的数组 第二种方法在内存使用和引用的局部性方面明显优越。但是,如果希望以可能导致树不平衡的方式允许从树中插入和删除,则可能会导致问题。这是因为这种设计的内存使用是树深度的指数函数。 假设您希望支持这种插入和删除。如何实现树,使树遍历充分利用CPU缓存。
-
二级缓存在Hibernate Spring JPA和EhCache中不工作
让我澄清一下我对二级缓存的理解。在我的web应用程序的基类中有一个查询。几乎每一个操作都会调用此查询(我使用的是Struts,这就是应用程序的设计方式,因此不会真正弄乱它),例如,加载我的主页会调用三个单独的Struts操作,并为每个操作执行此查询。QueryDsl形式的查询看起来像
-
Spring引导起动器高速缓存-速度丢失?
当我启动应用程序时,控制台出现以下异常: 我的pom.xml: mvn DEPENCY:树 我需要用Spring-启动-启动-缓存的速度吗?还是有什么其他的缺失或错误?
-
杂注和缓存控制标头之间的区别?
我在维基百科上读到语用标头,上面写着: “pragma:no-cache header字段是用于请求的HTTP/1.0标头。它是浏览器告诉服务器和任何中间缓存它需要资源的新版本的一种方法,而不是服务器告诉浏览器不要缓存资源。一些用户代理在响应中确实会注意此标头,但HTTP/1.1 RFC特别警告不要依赖此行为。” 但我不明白它是干什么的?值为的标头和值也为的之间有什么区别?
-
缓存刷新例程之间的计时不一致
我需要运行 DAXPY 线性代数核的时序。天真地,我想尝试这样的事情: 如果需要,完整的代码链接位于末尾。 问题是,填充操作数 x 和 y 的内存访问将导致它们被放置在处理器缓存中。因此,在 DAXPY 调用中对内存的后续访问比在生产运行中实际访问要快得多。 我比较了两种解决这个问题的方法。第一种方法是通过clflush指令从所有级别的缓存中刷新操作数。第二种方法是读取一个非常大的数组,直到操作数
-
没有重新执行Spring批处理步骤(缓存)
我正在做一个包括Spring批处理的项目,在复制代码片段之前,我要简单地总结一下这项工作是如何使用cron的。 cron在我的项目上调用restapi(@PostMapping(“/jobs/external/{jobName}”) 在post方法中,我获取作业并执行它 在每次执行中,我都应该执行一个步骤 该步骤包含一个读卡器(对弹性API的外部rest调用以获取文档)和一个处理器 现在我的问题是
-
如何使用命令行清除laravel中的缓存?
至 然后,在我的文件中,我为每个环境添加了前缀,如下所示 对于开发人员 如何清除特定环境的缓存?
-
Cassandra读取延迟高即使行缓存,为什么?
我正在用一个简单的模型测试卡桑德拉的性能。 我使用pycassa,get/xget函数()获取行键的100列。但在服务器上读取延迟约为15毫秒。 nodetool cfstats 这种类型的延迟是惊人的!当nodetool信息显示读取直接命中行缓存时。 谁能告诉我为什么cassandra在读取行缓存时要花这么多时间?
-
如何检测 XHR 何时返回缓存的资源?
我想知道是否有一种方法可以检测本地缓存何时返回响应?可能吗? 解决方案应该是通用的,并且适用于无条件的请求。在这种情况下,响应代码总是200 OK,但是XHR为第二个请求返回一个缓存的资源(例如,第一个响应包含Expires头,因此在到期日之前不需要向服务器请求新的资源)。
-
如何用带管道的Docker缓存本地Maven库?
我想在Docker容器中运行我的Maven构建。我不想在每次构建时都上传所有依赖项,所以我尝试装载主机的本地Maven存储库,如使用Docker with Pipeline: 为容器缓存数据 [...] Pipeline支持添加传递给Docker的自定义参数,允许用户指定要挂载的自定义Docker卷,该卷可用于在Pipeline运行之间缓存代理上的数据。以下示例将使用maven容器在Pipelin
-
2.4.3.实际缓存类反射数据的 Reflector 对象
Reflector是mybatis中定义的一个用于描述类定义信息的对象,它缓存了指定对象的类型,可读/可写属性,getter/setter方法,以及构造器等信息,并提供了操作这些属性或方法的入口,有效的简化针对指定对象的方法和属性的反射操作。 Reflector对象的定义和实现涉及到的东西比较多,我们先简单了解一下这个类的属性定义: public class Reflector { /**
-
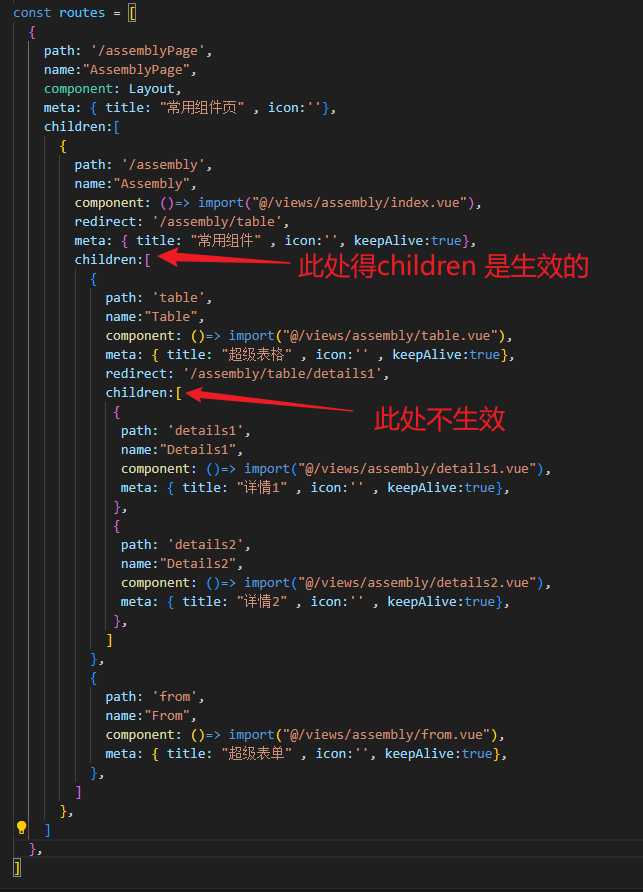 前端 - vue3中keep-alive 缓存页面如何实现?
前端 - vue3中keep-alive 缓存页面如何实现?vue3中使用keep-alive中include属性来缓存router-view 在第一层子级下缓存是生效得 但是在第二级缓存就不生效了 最终想实现得是在全局layout实现个页面缓存(不仅只有两级children还会有更多)、通过组件得name值配置或者路由信息配置 请求大佬指教������
-
如何在Redis中将MongoDB文档存储为缓存并按超时刷新
问题内容: 我有处理嵌套JSON文档的nodejs应用程序,如下所示: 并将它们存储在MongoDB数据库中。我的文档需要经常更新,但是如您所知,由于其性质,MongoDB的写入速度非常慢。为了解决此问题,我决定将文档存储在Redis中,并在某个超时时间(例如1-2小时后)刷新到MongoDB。 因此,这里是我的更新方法的代码示例: 我的第一个问题是我如何处理文档?我的方法有什么问题吗? 第二个问
-
在移动应用中缓存HTTP响应还是存储在数据库中?
为了获得更好的UX,移动应用程序将数据存储在客户端(设备上),以便在加载应用程序时提供即时信息,而不必等待来自互联网的数据,甚至在设备脱机时也可以提供数据。当然,以后会尽可能地更新/提取数据。 我正在构建一个应用程序(在flutter中),它是一个类似应用程序的社交网络/信息提要:有用户、配置文件、提要、帖子等。当用户打开应用程序时,我想显示上次应用程序运行时可用的数据。 我的问题是什么是实现缓存