《底层》专题
-
 ionic 背景层
ionic 背景层主要内容:实例我们经常需要在 UI 上,例如在弹出框、加载框、其他弹出层中显示或隐藏背景层。 在组件中可以使用$ionicBackdrop.retain()来显示背景层,使用$ionicBackdrop.release()隐藏背景层。 每次调用retain后,背景会一直显示,直到调用release消除背景层。 实例 HTML 代码 JavaScript 代码 尝试一下 » 显示效果如下图所示:
-
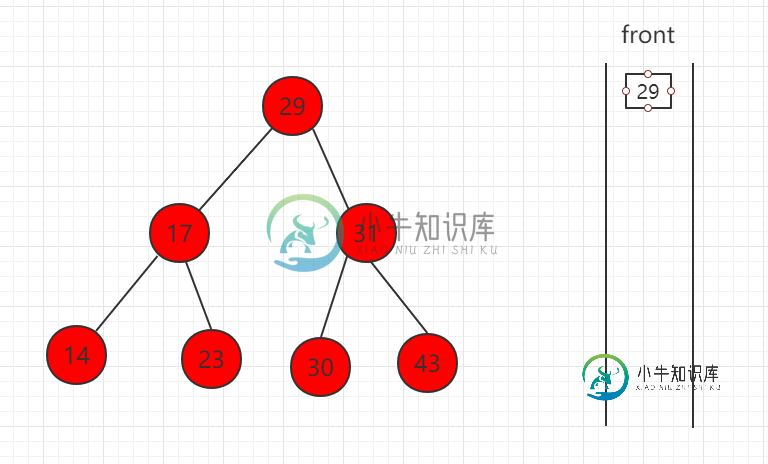 二分搜索树层序遍历
二分搜索树层序遍历主要内容:src/runoob/binary/LevelTraverse.java 文件代码:二分搜索树的层序遍历,即逐层进行遍历,即将每层的节点存在队列当中,然后进行出队(取出节点)和入队(存入下一层的节点)的操作,以此达到遍历的目的。 通过引入一个队列来支撑层序遍历: 如果根节点为空,无可遍历; 如果根节点不为空: 先将根节点入队; 只要队列不为空: 出队队首节点,并遍历; 如果队首节点有左孩子,将左孩子入队; 如果队首节点有右孩子,将右孩子入队; 下面依次演示如下步骤: (1)先取出
-
Python Pandas分层索引
主要内容:创建分层索引,应用分层索引,分层索引切片取值,聚合函数应用,局部索引,行索引层转换为列索引,列索引实现分层,交换层和层排序分层索引(Multiple Index)是 Pandas 中非常重要的索引类型,它指的是在一个轴上拥有多个(即两个以上)索引层数,这使得我们可以用低维度的结构来处理更高维的数据。比如,当想要处理三维及以上的高维数据时,就需要用到分层索引。 分层索引的目的是用低维度的结构(Series 或者 DataFrame)更好地处理高维数据。通过分层索引,我们可以像处理二维数据
-
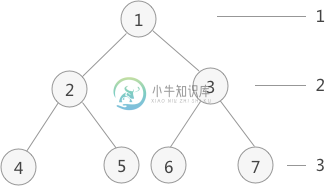 二叉树层次遍历
二叉树层次遍历主要内容:层次遍历的实现过程,实现代码前边介绍了 二叉树的先序、中序和后序的遍历算法,运用了 栈的 数据结构,主要思想就是按照先左子树后右子树的顺序依次遍历树中各个结点。 本节介绍另外一种遍历方式:按照二叉树中的层次从左到右依次遍历每层中的结点。具体的实现思路是:通过使用 队列的数据结构,从树的根结点开始,依次将其左孩子和右孩子入队。而后每次队列中一个结点出队,都将其左孩子和右孩子入队,直到树中所有结点都出队,出队结点的先后顺序就是层
-
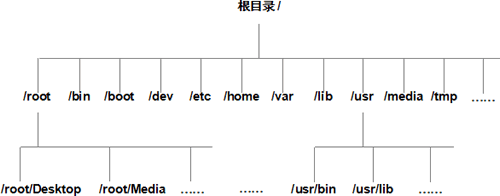 Linux文件系统的层次结构
Linux文件系统的层次结构通过学习《 Linux一切皆文件》一节我们知道,平时打交道的都是文件,那么,应该如何找到它们呢?很简单,在 Linux 操作系统中,所有的文件和目录都被组织成以一个根节点“/”开始的倒置的树状结构,如图 1 所示。 图 1 Linux 系统文件和目录组织示意图 其中,目录就相当于 Windows 中的文件夹,目录中存放的既可以是文件,也可以是其他的子目录,而文件中存储的是真正的信息。 文件系统的最
-
LoadException:没有指定控制器。在顶层指定控制器
在一个项目中,当我将代码切换到主分支时,我开始发现一些错误。其中之一是加载异常错误。整个日志还显示了一个No Suck method异常错误。 我也想发布控制器,但因为它超过600行,我不确定这是否有帮助,我已经确保控制器中的每个方法都是公共的,唯一的私有部分是我使用的变量和图表。
-
具有远程服务调用的事务服务层
答案可能涵盖所有框架,但我对SpringMVC案例特别感兴趣。我正在重构一个访问内部数据库和远程服务的服务层。这些方法应该是事务性的,它们需要来自远程服务的数据。下面是类似的伪代码: 这样更容易实现。但是有许多缺点,例如当远程服务调用失败时不必要地创建和回滚事务,由于远程服务调用而导致的事务更长,并且可能更复杂。我正在考虑将服务调用移动到单独的非事务性方法,并调用事务性方法,如下面的代码段所示 假
-
JPA2实体在完成事务服务层方法后意外地保持管理状态
到目前为止,感谢您的评论! 在控制器和服务impl中注入的实体管理器只是为了调试目的和澄清我的stackoverflow问题而添加的。 我按照Andrei I的建议,添加了一种服务方式: 在控制器中,我使用这个新的isManaged()方法,而不是注入EntityManager。 我重新测试了行为,这仍然是一样的:实体仍然附加在服务方法之外,对实体的更改将持久化到数据库。只有当我离开调用服务方法的
-
服务层和spring事务中的验证
我过去认为,在分层应用程序(控制器或服务)中,将验证逻辑放在何处并不重要,但最近正在开发需要事务的服务(使用spring)。Spring使用方面创建代理,Spring代码如下所示: org.springframework.transaction.interceptor.事务支持 所以从我这里看到的,spring首先打开事务,然后执行代码。考虑到验证可能会失败,并且根本不需要DB调用,这是否意味着将
-
用Keras迁移学习。最后的层激活应该是什么?
我在这里参考 Keras 文档:https://keras.io/guides/transfer_learning/ 演示了一个典型的迁移学习工作流程 首先,用预先训练的权重实例化一个基础模型。 然后,冻结基本模型。 在顶部创建一个新模型。 根据新数据训练模型。 我的问题是,为什么这个示例没有在密集层中应用sigmoid或softmax激活? 这里的这个密集层默认有线性激活,这不是让模型输出一个回
-
 在现有geom_sf层下面插入geom_sf层
在现有geom_sf层下面插入geom_sf层我有一张印度的基本地图,其中有邦和边界,一些标签,以及一些其他规范,作为gg对象存储。我想用一个地区层生成一些地图,这些地图将承载来自不同变量的数据。 为了防止地区地图覆盖州和国家边界,它必须在所有之前的代码之前,我想避免重复。 我想我可以通过根据这个答案调用 gg 对象的来做到这一点。但是,它会引发错误。Reprex 如下: 任何帮助都将不胜感激!
-
如何使用SBT为库构建分层JAR文件?
我在图书馆工作,需要一些依赖。为了便于部署,我想创建一个包含所有内容的JAR文件,包括依赖项。 我已经尝试过sbt汇编——这是可行的,但由于法律原因,这可能是不可取的,因此我正在寻找一种解决方案,其中生成的JAR文件包含原始JAR文件,并且类路径条目包含在清单中。MF的设置使得客户端类可以将这个“嵌套JAR文件”添加到它们的类路径中。 这样的事情可能吗?sbt one jar几乎可以满足我的需求,
-
Pandas:使用循环和分层索引将多个csv文件导入dataframe
我已经找到了许多相关的链接,但我仍然无法得到这个工作: 将多个CSV文件读取到Python Pandas DataFrame中 将多个不同列数的数据帧合并为一个大数据帧 将多个csv文件导入到pandas中并连接到一个Dataframe中
-
在Spark中创建分层JSON
我有一个火花数据框,我需要写入MongoDB。我想知道如何在mongoDB中将数据框的一些列写成嵌套/分层JSON。假设数据框有6列,col1,col2,…… col5,col6我想要col1,col2,col3作为第一层次结构,其余列col4到col6作为第二层次结构。像这样的东西, 我如何在pyspark中实现这一点?
-
deeplearning4j嵌入层权重更新
我需要使用嵌入层来编码单词向量,所以嵌入层的权重本质上是单词向量。显然,我不希望这种情况下的权重在反向传播期间被更新。我的问题是,如果按设计嵌入层已经禁止重量更新,或者我必须对此做一些特别的事情?