《数据湖》专题
-
创建从数据库获取数据的折线图
我尝试在D3中创建一个简单的条形图,从数据库中获取数据。其想法是使用参数和国家的选择按钮从数据库中提取年份和值,并以简单条形图的形式显示。我有两个选择按钮和一个提交按钮。代码如下: Foodfiner和Waterfiner是数据库中名为“气候”的表的名称。NPL和IND是国家代码。我的PHP代码(data.php)是这样的: 我的问题是那个折线图。html在使用选择表单之前工作得很好,但这一次,它
-
原因:com。谷歌。firebase。数据库数据库异常:
E/AndroidRuntime:致命异常:主进程:com。实例海报,PID:23677爪哇。lang.RuntimeException:无法启动活动组件信息{com.example.poster/com.example.poster.MainActivity}:com。谷歌。firebase。数据库DatabaseException:无法获取FirebaseDatabase实例:请在Fireba
-
Android VpnService捕获数据包不会捕获数据包
问题内容: 我已经在寻找我的答案几个小时了,但无法解决。请帮忙。 我想要做的是在Android中使用VpnService来抓取网络数据包,例如应用程序tPacketCapture 我首先使用了Google的ToyVpn示例代码并对其进行了修改,所以我不将数据发送到服务器。但是,我不确定这是否正确。 我的configure方法在调用build()之前将wlan ip地址用于binder.addAdd
-
创建具有大量数据的android app数据库
问题内容: 我的应用程序的数据库需要填充大量数据,因此在期间,不仅有一些创建表sql指令,而且还有很多插入。我选择的解决方案是将所有这些指令存储在res / raw中的sql文件中,该文件已加载。 它运作良好,但我面对编码问题,sql文件中有一些突出的字符,在我的应用程序中看起来很糟。这是我的代码来做到这一点: 我发现避免这种情况的解决方案是从一个巨大的而不是文件中加载sql指令,并且所有突出的字
-
将数据库架构复制到现有数据库
问题内容: 我正在使用Microsoft Sql Server Management Studio。我目前有一个包含数据的现有数据库,我将其称为DatabaseProd。我还有一个第二个数据库,其中包含用于测试的数据,因此数据既不完全正确也不是最新的。我将这个数据库称为DatabaseDev。 但是,DatabaseDev现在包含新添加的表和新添加的列等。 我想将此新模式从DatabaseDev复
-
MySQL数据库中历史数据的最佳做法
问题内容: 最近,我考虑了将历史数据存储在MySQL数据库中的最佳做法。目前,每个可版本控制的表都有两列-和,两者均为类型。具有当前数据的记录已充满了创建日期。当我更新此行时,我填写了更新日期,并添加了与上一行相同的新记录- 简单的东西。但是我知道表会非常快,因此获取数据可能会很慢。 我想知道您是否有任何存储历史数据的做法? 问题答案: 担心“大”表和性能是一个常见的错误。如果您可以使用索引来访问
-
详解 linux mysqldump 导出数据库、数据、表结构
本文向大家介绍详解 linux mysqldump 导出数据库、数据、表结构,包括了详解 linux mysqldump 导出数据库、数据、表结构的使用技巧和注意事项,需要的朋友参考一下 详解 linux mysqldump 导出数据库、数据、表结构 导出完整的数据库备份: 说明:--add-locks:导出过程中锁定表,完成后回解锁。-q:不缓冲查询,直接导出至标准输出 导出完整的数据库表结构
-
Oracle删除重复的数据,Oracle数据去重复
本文向大家介绍Oracle删除重复的数据,Oracle数据去重复,包括了Oracle删除重复的数据,Oracle数据去重复的使用技巧和注意事项,需要的朋友参考一下 Oracle 数据库中查询重复数据: select * from employee group by emp_name having count (*)>1; Oracle 查询可以删除的重复数据 select t1.* from
-
Mysql删除重复的数据 Mysql数据去重复
本文向大家介绍Mysql删除重复的数据 Mysql数据去重复,包括了Mysql删除重复的数据 Mysql数据去重复的使用技巧和注意事项,需要的朋友参考一下 MySQL数据库中查询重复数据 select * from employee group by emp_name having count (*)>1; Mysql 查询可以删除的重复数据 select t1.* from employee
-
将Pandas数据框转换为Spark数据框错误
问题内容: 我正在尝试将Pandas DF转换为Spark one。DF头: 码: 我得到一个错误: 问题答案: 您需要确保您的pandas dataframe列适合spark推断的类型。如果您的熊猫数据框列出类似以下内容: 而且您遇到该错误,请尝试: 现在,确保实际上是您希望这些列成为的类型。基本上,当底层Java代码尝试从python中的对象推断类型时,它会使用一些观察值并做出猜测,如果该猜测
-
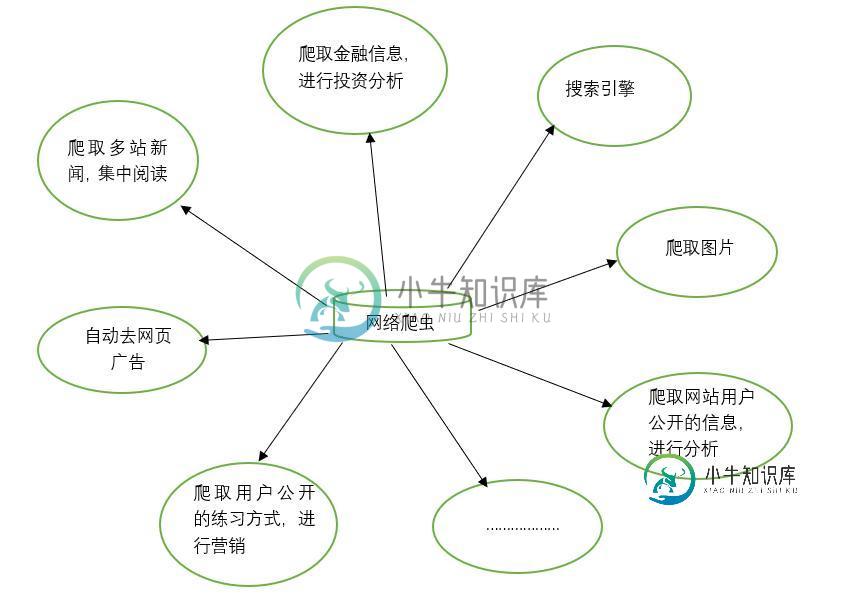 python爬虫爬取网页数据并解析数据
python爬虫爬取网页数据并解析数据本文向大家介绍python爬虫爬取网页数据并解析数据,包括了python爬虫爬取网页数据并解析数据的使用技巧和注意事项,需要的朋友参考一下 1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。 只要浏览器能够做的事情,原则上,爬虫都能够做到。 2.网络爬虫的功能 网络爬虫可以代替手工做很多事情,比如可以
-
如何更改derby数据库的列数据类型?
问题内容: 我正在尝试更改derby db列的数据类型。当前价格列设置为DECIMAL(5,0)。我想将其更改为DECIMAL(7,2)。我是这样做的: 但是它不起作用,并显示错误: 我可以知道如何进行更改吗?谢谢你。 问题答案: 这是Derby SQL脚本,用于将列MY_TABLE.MY_COLUMN从BLOB(255)更改为BLOB(2147483647):
-
php获取数据库中数据的实现方法
本文向大家介绍php获取数据库中数据的实现方法,包括了php获取数据库中数据的实现方法的使用技巧和注意事项,需要的朋友参考一下 废话不多说,直接上代码 这是获取完之后转成json格式 以上这篇php获取数据库中数据的实现方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持呐喊教程。
-
Spring Cloud数据流与Apache Beam/GCP数据流澄清
我很难理解GCP数据流/Apache Beam和Spring Cloud数据流之间的差异。我试图做的是转向一个更云原生的解决方案,用于流数据处理,这样我们的开发人员可以更专注于开发核心逻辑,而不是管理基础设施。 我们有一个现有的流解决方案,由Spring云数据流“模块”组成,我们可以独立迭代和部署,就像微服务一样,效果很好,但我们希望迁移到我们的业务提供的GCP现有平台,要求我们使用GCP数据流。
-
从数据库获取数据后动态设置chunksize
我需要在spring批处理作业的步骤中动态设置块大小,该步骤存储在数据库中,即需要从数据库中获取块大小并将其设置到bean中。 我的问题是: 从ID='some_id_param_value'的SOME_TABLE_NAME选择CHUNK_SIZE 在这里,的值将来自作业参数,该参数是通过与请求一起传递到 它无法从访问“chunk”键值,因此引发。是否需要以某种方式对其进行升级,以便可以在step