《hbase》专题
-
HBase列族局部性
-
使用Phoenix驱动程序将数据保存到Hbase时的时区问题
-
HBASE:列族TTL
符合HBase规格: “ColumnFamilies可以以秒为单位设置TTL长度,一旦达到过期时间,HBase将自动删除行。这适用于行的所有版本,甚至是当前版本。在HBase中为行编码的TTL时间是在UTC中指定的。” null
-
用PySpark从HBase读取
我正在尝试用PySpark从HBase写/读。 环境: null 我的火花提交是: 当我写到HBase时,一切都很好,数据从mydf保存到HBase表中。 当我试图阅读时,它很好,只有在激发行动之前。df.show()-导致错误。
-
Spark上的Apache Phoenix-无法插入到Phoenix HBase表/需要最佳实践建议
我有一张下面结构的桌子。 在Apache Storm中,我能够在configure方法中创建一个Phoenix Connection对象,并且能够每10秒使用一次相同的连接来upsert。 在Spark中,我不能创建一个连接对象并为RDD中的每个对象使用相同的对象。spark的输出将是一个JavadStream>,其中start_time、end_time、count都是映射中的键。 我最终为RD
-
Spark 2.3.0 SQL无法将数据插入hive hbase表
使用与hive 2.2.0集成的Spark2.3thriftserver。从火花直线运行。尝试将数据插入配置单元hbase表(以hbase作为存储的配置单元表)。插入到配置单元本机表是可以的。当插入到配置单元hbase表时,它会引发以下异常:
-
使用Spark和Phoenix将CSV文件保存到hbase表中
有人能给我提供一个使用Spark2.2选项将csv文件保存到Hbase表的工作示例吗?我尝试过但失败了(注意:所有这些选项都适用于Spark1.6) 凤凰-火花 HBase-Spark it.nerdammer.bigdata:spark-hbase-connector2.10 所有这些最终都在修复一切后给出了类似的错误,这个火花HBase 谢谢
-
使用phoenix连接器将Spark dataframe写入Hbase
-
使用Phoenix在HBase中删除包含表的模式
null 这是使用Phoenix从HBase删除模式的Java代码:
-
用hbase serde阅读hbase表,用蜂巢中的凤凰盐腌
我使用Phoenix SQL创建表查询创建了一个hbase表,并指定了salt_buckets。Salting将前缀添加到rowkey中。 我已经用hbase serde创建了一个外部配置单元表来映射到这个hbase表,问题是当我通过rowkey上的筛选来查询这个表时: 我的问题是如何在配置单元中的行键值上高效地查询这个表(去掉salt前缀)?
-
Phoenix-Spark API有像HBase API一样的checkAndPut方法吗?
我使用的是Spark1.3、HBase1.1和Phoenix4.4。我的代码中有以下内容: 在DataFrame中,CREATED_DATE始终设置为dateTime.now()。 但是如何使用Phoenix-Spark API来实现呢?我应该改用HBase API吗?
-
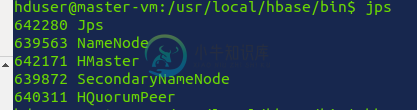 HBase完全分布式模式[执行HBase shell时Zookeeper错误]
HBase完全分布式模式[执行HBase shell时Zookeeper错误]根据这两个教程:即教程1和教程2,我能够在完全分布式模式下设置HBase集群。最初,集群似乎工作正常。 hmaster/Name节点中的“jps”输出 datanodes/RegionServers中的jps输出 null (我已经试着在/etc/hosts/中评论与HBase相关的主机,但仍然没有成功) 在hbase-site.xml中
-
执行hbase shell命令时,HMaster节点消失
8998 HRegionServer 8066 ResourceManager 8229 NodeManager 错误:无法从动物园管理员那里获得主地址;znode数据==null。 从hbase(main)退出后:001:0>我明白了 8998 HRegionServer
-
HBase错误:不是主机:端口对
嗨,我正在使用hBase在完全分布式模式,我试图连接hBase使用java代码和创建一个表。我得到一个错误。它没有连接到HBase。我已经检查了它们运行良好的所有进程:-namenode、datanode、nodemanager、resource manager、hbase master、hbase regionservers、ZooKeeper。
-
Phoenix没有从HBASE视图返回任何行
在HBASE 0.98.4上使用Phoenix4.2版本(我知道是老版本)。