《hive》专题
-
插入Hive表中的值并用双引号将csv文件中的字符串
问题内容: 我正在将一个csv文件导出到配置单元表中。关于csv文件:列值包含在双引号中,并用逗号分隔。 CSV的样本记录 我使用以下语句创建了一个配置单元表, 创建外部表咖喱(review_rating string,review_comment string)行格式字段,以;分隔 表已创建。 现在,我使用命令load data local inpath加载了数据,并且操作成功。当我查询表格时,
-
如何对数组排序并返回hive中的索引?
问题内容: 在hive中,我希望对从最大到最小的数组进行排序,并获得索引数组。 例如,该表是这样的: 我要得到这个: 结果中的arries是初始元素的索引。我怎样才能做到这一点? 问题答案: 使用posexplode爆炸数组以获取索引和值,按值排序,收集索引数组: 经过测试,结果:
-
对行进行排序时优化Hive GROUP BY
问题内容: 我有以下(非常简单)Hive查询: 该表具有以下结构: 对于一个事实,我知道行首先按,然后按排序。 问题是:鉴于行已排序,有没有一种方法可以“提示” Hive引擎来优化查询?优化的目的是避免将所有组都保留在内存中,因为这一次仅需保留一个组即可。 现在,此查询在具有大约300 GB数据的6节点16 GB Hadoop集群中运行,大约需要30分钟,并且使用了大部分RAM,这使系统感到窒息。
-
Spark可以从pyspark访问Hive表,但不能从Spark提交访问
问题内容: 因此,从pyspark运行时,我会输入(不指定任何上下文): ..而且效果很好。 但是,当我从运行脚本时,例如 我把以下内容 但这给我一个错误 pyspark.sql.utils.AnalysisException:u’未找到表:experian_int_openings_latest_orc;’ 所以它没有看到我的桌子。 我究竟做错了什么?请帮忙 PS Spark版本在Amazon
-
使用Python访问Hive数据
问题内容: 我在HDFS中有一些数据,我需要使用python访问该数据,有人可以告诉我如何使用python从蜂巢访问数据吗? 问题答案: 您可以使用hive库从python访问hive,因为要从hive导入ThriveHive导入hive类 下面的例子
-
Hive插入查询(如SQL)
问题内容: 我是hive的新手,想知道是否有像在SQL中一样将数据插入到hive表中的方法。我想像我的蜂巢中插入我的数据 我已经读过您可以将文件中的数据加载到配置单元表中,也可以将数据从一个表导入到配置单元表中,但是有什么方法可以像在SQL中那样附加数据吗? 问题答案: 自Hive 0.14起,此处的某些答案已过时 https://cwiki.apache.org/confluence/displ
-
Hive和HBase之间的区别
本文向大家介绍Hive和HBase之间的区别,包括了Hive和HBase之间的区别的使用技巧和注意事项,需要的朋友参考一下 Apache Hive和HBase都是基于Hadoop的大数据技术,它们基本上具有相同的查询大数据的目的。但是,Apache Hive和HBase都在Hadoop之上运行,但它们的功能有所不同。 但是基于功能,我们可以如下区分Hive和HBase- 序号 键 蜂巢 HBase
-
Dynamic Partitioning + CREATE AS on HIVE
问题内容: 我试图从另一个表中创建一个新表CREATE AS和 动态分区上HiveCLI。我正在从Hive官方Wiki学习,这里 有以下示例: 但是我收到了这个错误: FAILED: SemanticException [Error 10065]: CREATE TABLE AS SELECT command cannot specify the list of columns for the t
-
yum安装CDH5.5 hive、impala的过程详解
本文向大家介绍yum安装CDH5.5 hive、impala的过程详解,包括了yum安装CDH5.5 hive、impala的过程详解的使用技巧和注意事项,需要的朋友参考一下 一、安装hive 组件安排如下: 1.安装hive 在77上安装hive: 在其他节点上可以安装客户端: 2.安装mysql yum方式安装mysql: 启动数据库: 安装jdbc驱动: 设置mysql初始密码为bigdat
-
hive 创建数据库
本文向大家介绍hive 创建数据库,包括了hive 创建数据库的使用技巧和注意事项,需要的朋友参考一下 示例 在特定位置创建数据库。如果我们不为数据库指定任何位置,则其在仓库目录中创建。
-
hive 建立表格
本文向大家介绍hive 建立表格,包括了hive 建立表格的使用技巧和注意事项,需要的朋友参考一下 示例 创建具有分区的托管表并存储为序列文件。假定文件中的数据格式Ctrl-A (^A)由换行符进行字段分隔和行分隔。下表是hive.metastore.warehouse.dir在Hive仓库目录中创建的,该目录中为Hive配置文件中的键指定了值hive-site.xml。 创建具有分区的外部表并存
-
如何检查Hive中是否存在表?
问题内容: 我正在通过.NET应用程序中的ODBC驱动程序连接到Hive。是否存在查询以确定表是否已存在? 例如,在MSSQL中,您可以查询表,而在Netezza中,您可以查询表。 任何援助将不胜感激。 问题答案: 您可以通过两种方法进行检查: 1.)如@dimamah所建议,只需在此处添加一点,对于这种方法,您需要 2.)第二种方法是使用HiveMetastoreClient API,您可以在其
-
动态分区+在HIVE上创建AS
问题内容: 我正在尝试使用HiveCLI上的动态分区从另一个表创建一个新表。我正在从Hive官方Wiki学习,这里有以下示例: 但是我收到了这个错误: 失败:SemanticException [错误10065]: CREATE TABLE AS SELECT命令无法指定目标表的列列表 资料来源:https : //cwiki.apache.org/confluence/display/Hive/
-
Hive JOIN中同时遇到左右别名;没有任何不平等条款
问题内容: 我正在使用以下查询: 我收到错误消息: 失败:SemanticException行0:-1在JOIN’PRSMN_VAL_END_D’中同时遇到左右别名 搜索表明,当查询中有不相等子句时,就会出现此错误。但是,即使在出现此错误的情况下,我也没有使用任何不等式子句(或在我的查询(just和)中)。 问题答案: 尝试将不等式条件从on子句移到where条件。
-
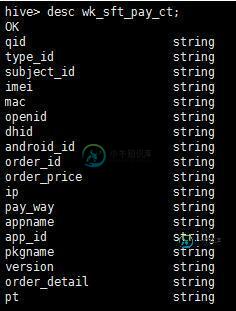 python处理数据,存进hive表的方法
python处理数据,存进hive表的方法本文向大家介绍python处理数据,存进hive表的方法,包括了python处理数据,存进hive表的方法的使用技巧和注意事项,需要的朋友参考一下 首先,公司的小组长给了我一个任务,把一个txt的文件中的部分内容,存进一个在hive中已有的表的相同结构的表中。所以我的流程主要有三个,首先,把数据处理成和hive中表相同结构的数据,然后仿照已有的hive中表的结构再创建一张新的数据表,最后把本地的t