
python处理数据,存进hive表的方法

首先,公司的小组长给了我一个任务,把一个txt的文件中的部分内容,存进一个在hive中已有的表的相同结构的表中。所以我的流程主要有三个,首先,把数据处理成和hive中表相同结构的数据,然后仿照已有的hive中表的结构再创建一张新的数据表,最后把本地的txt文件上传到hive中新建的数据表中。
1:已有的数据表的结构和在hive表中的结构完全对不上,下面的图是原来hive中表的结构和小组长给我的txt中表的结构:
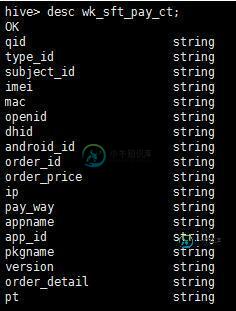

大家可以看出,我们原来的hive中表的字段一共有17个,而组长给我的表中的字段一共有9个,其中最后一个为json结构,而且顺序还不对,所以我们要进行筛选,把对应上的字段放到相应位置,对应不上的字段写成空。

大家要注意几个地方,原来的数据是按照tab来划分的,所以我们要数好对应的tab的数目,好来计算出来数据的实际的位置信息,然后我们按照原来hive表中的数据顺序,重新排列我们新建表的数据的顺序,下面给大家看看结果:

其中line[0]=null,line[1]=102,大家以此类推。
3:我们把本地的txt文件导入到hive表中。首先我们要新建一个和原来hive表中相同结构的数据表,然后把我们的数据导入到表中,
hive> creat table new_sft(x1 string,x2 string ,...,xn string) partitioned by (d string);
建好表之后,把数据导入到新表之中:
hive> load data local inpath‘/home/opendev/1.txt' into table new_sft;
最后给大家看看我的最终的结果:

以上这篇python处理数据,存进hive表的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持小牛知识库。
-
本文向大家介绍Python使用Pandas对csv文件进行数据处理的方法,包括了Python使用Pandas对csv文件进行数据处理的方法的使用技巧和注意事项,需要的朋友参考一下 今天接到一个新的任务,要对一个140多M的csv文件进行数据处理,总共有170多万行,尝试了导入本地的MySQL数据库进行查询,结果用Navicat导入直接卡死....估计是XAMPP套装里面全默认配置的MySQL性能不
-
本文向大家介绍python数据处理 根据颜色对图片进行分类的方法,包括了python数据处理 根据颜色对图片进行分类的方法的使用技巧和注意事项,需要的朋友参考一下 前面一篇文章有说过,利用scrapy来爬取图片,是为了对图片数据进行分类而收集数据。 本篇文章就是利用上次爬取的图片数据,根据图片的颜色特征来做一个简单的分类处理。 实现步骤如下: 1:图片路径添加 2:对比度处理 3:滤波处理 4:数
-
本文向大家介绍python数据预处理之数据标准化的几种处理方式,包括了python数据预处理之数据标准化的几种处理方式的使用技巧和注意事项,需要的朋友参考一下 何为标准化: 在数据分析之前,我们通常需要先将数据标准化(normalization),利用标准化后的数据进行数据分析。数据标准化也就是统计数据的指数化。数据标准化处理主要包括数据同趋化处理和无量纲化处理两个方面。数据同趋化处理主要解决不同
-
本文向大家介绍Python处理XML格式数据的方法详解,包括了Python处理XML格式数据的方法详解的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python处理XML格式数据的方法。分享给大家供大家参考,具体如下: 这里的操作是基于Python3平台。 在使用Python处理XML的问题上,首先遇到的是编码问题。 Python并不支持gb2312,所以面对encoding="gb23
-
本文向大家介绍python处理大数字的方法,包括了python处理大数字的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了python处理大数字的方法。分享给大家供大家参考。具体实现方法如下: 运行结果如下: 希望本文所述对大家的Python程序设计有所帮助。
-
我使用Spring批处理从Oracle数据库读取数据并将结果写入CSV文件。 我还需要将spring批处理元数据表与oracle数据库分开,为此,我在批处理配置中配置了两个不同的数据源(spring批处理元数据的内存数据库)。 这是我的代码: 批处理配置。JAVA 然后我的itemReader bean看起来像: 当我运行批处理时,一切正常。 但是当我尝试在我的BatchApplication中添