《二叉树》专题
-
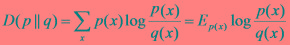 交叉熵公式
交叉熵公式本文向大家介绍交叉熵公式相关面试题,主要包含被问及交叉熵公式时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 交叉熵:设p(x)、q(x)是X中取值的两个概率分布,则p对q的相对熵是: 在一定程度上,相对熵可以度量两个随机变量的“距离”,且有D(p||q) ≠D(q||p)。另外,值得一提的是,D(p||q)是必然大于等于0的。 互信息:两个随机变量X,Y的互信息定义为X,Y的联合分布和各自
-
MySQL交叉连接
主要内容:笛卡尔积前面所讲的查询语句都是针对一个表的,但是在关系型数据库中,表与表之间是有联系的,所以在实际应用中,经常使用多表查询。多表查询就是同时查询两个或两个以上的表。 在 MySQL 中,多表查询主要有交叉连接、内连接和外连接。由于篇幅有限,本节主要讲解交叉连接查询。内连接和外连接将在《 MySQL内连接》和《 MySQL外连接》中讲解。 交叉连接(CROSS JOIN)一般用来返回连接表的笛卡尔积。 本节
-
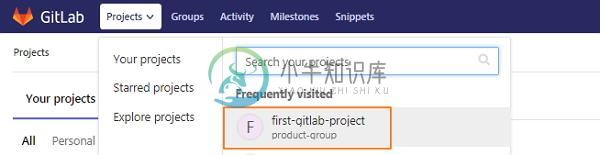 GitLab分叉项目
GitLab分叉项目主要内容:创建一个分支分支是独立的线路和开发过程的一部分。 分支的创建包括以下步骤。 创建一个分支 步骤(1): 登录到您的GitLab帐户并转到项目部分下的项目。 步骤(2): 要创建分支,请单击“Repository” 部分下的 Branches 选项,然后单击“New branch” 按钮。 步骤(3): 在New branch 界面中,输入分支的名称,然后单击 Create branch 按钮。 步骤(4):
-
 GitLab分叉项目
GitLab分叉项目主要内容:分叉项目分叉(Fork)是原始存储库的一个副本,您可以在不影响原始项目的情况下进行更改。 分叉项目 步骤(1): 要分叉一个项目,请项目详细下面单击按钮,以上节中创建的项目为例,如下所示: 步骤(2): 在分叉项目之后,需要通过单击将分叉的项目添加到分支组: 注意:如果提示没有命名空间权限(namespace),可以先创建一个分组后,再创建分叉。 步骤(3): 接下来,它将开始处理项目一段时间。 步骤(4
-
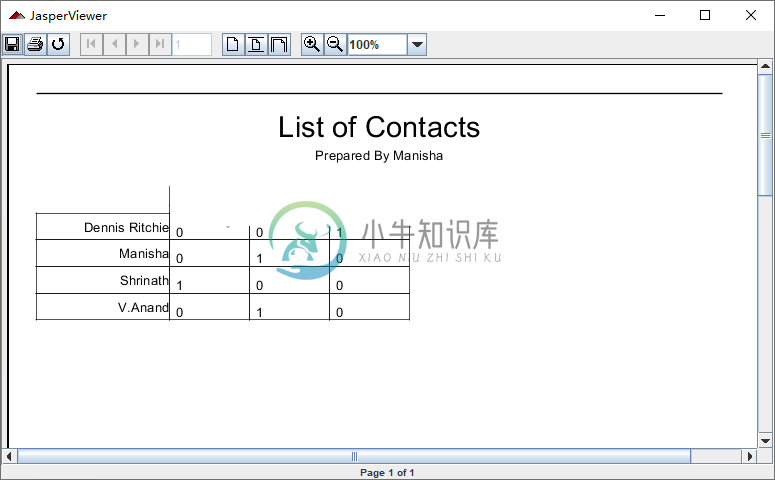 JasperReports 交叉表crosstab
JasperReports 交叉表crosstab主要内容:交叉表属性,JasperReports 交叉表的示例交叉表(cross-tabulation)报表是包含以表格形式跨行和列排列数据的表格的报表。交叉表对象用于在主报表中插入交叉表报表。交叉表可用于任何级别的数据(名义、有序、区间或比率),并且通常以动态表的形式显示包含在报表变量中的汇总数据。变量用于显示汇总数据,例如总和、计数、平均值。 交叉表属性 JRXML 元素<crosstab> 用于在报表中插入交叉表。 属性 以下是 <crosstab>
-
分叉与线程
问题内容: 我以前在应用程序中使用过线程,并且对线程的概念非常了解,但是最近在我的操作系统讲座中,我遇到了fork()。这类似于线程。 我用谷歌搜索了它们之间的区别,我知道: Fork只是一个看起来与旧流程或父流程完全相似的新流程,但它仍然是具有不同流程ID并拥有自己内存的不同流程。 线程是轻量级进程,具有较少的开销 但是,我仍然有一些疑问。 什么时候应该更喜欢fork()而不是线程? 如果我想以
-
TypeScript 交叉类型
本节起开始介绍 TypeScript 高级类型,依次是交叉类型、联合类型、类型别名、索引类型、映射类型、条件类型。 本节介绍交叉类型的语法和应用,跟数学集合里的相交不一样,TypeScript 的交叉类型并不是指每个类型的交集,& 的意思理解成 and ,A & B 表示同时包含 A 和 B 的结果。 1. 慕课解释 交叉类型是将多个类型合并为一个类型。 这让我们可以把现有的多种类型叠加到一起成为
-
1.8. 交叉分解
校验者: @peels 翻译者: @Counting stars 交叉分解模块主要包含两个算法族: 偏最小二乘法(PLS)和典型相关分析(CCA)。 这些算法族具有发现两个多元数据集之间的线性关系的用途: fit method (拟合方法)的参数 X 和 Y 都是 2 维数组。 交叉分解算法能够找到两个矩阵 (X 和 Y) 的基础关系。它们是对在两个空间的 协方差结构进行建模的隐变量方法。它们将尝
-
 JS中的算法与数据结构之二叉查找树(Binary Sort Tree)实例详解
JS中的算法与数据结构之二叉查找树(Binary Sort Tree)实例详解本文向大家介绍JS中的算法与数据结构之二叉查找树(Binary Sort Tree)实例详解,包括了JS中的算法与数据结构之二叉查找树(Binary Sort Tree)实例详解的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了JS中的算法与数据结构之二叉查找树(Binary Sort Tree)。分享给大家供大家参考,具体如下: 二叉查找树(Binary Sort Tree) 我们之前所学
-
 python 使用turtule绘制递归图形(螺旋、二叉树、谢尔宾斯基三角形)
python 使用turtule绘制递归图形(螺旋、二叉树、谢尔宾斯基三角形)本文向大家介绍python 使用turtule绘制递归图形(螺旋、二叉树、谢尔宾斯基三角形),包括了python 使用turtule绘制递归图形(螺旋、二叉树、谢尔宾斯基三角形)的使用技巧和注意事项,需要的朋友参考一下 插图工具使用Python内置的turtle模块,为什么叫这个turtle乌龟这个名字呢,可以这样理解,创建一个乌龟,乌龟能前进、后退、左转、右转,乌龟的尾巴朝下,它移动时就会画一条
-
Java中二叉树的奇数位置和偶数位置节点之和之间的差
本文向大家介绍Java中二叉树的奇数位置和偶数位置节点之和之间的差,包括了Java中二叉树的奇数位置和偶数位置节点之和之间的差的使用技巧和注意事项,需要的朋友参考一下 问题陈述 对于给定的二叉树,编写一个程序以查找奇数位置和偶数位置的节点总和之差。假设根位于0级,奇数位置,根的左/右子级位于2级,左子级位于奇数位置,右子级位于偶数位置,依此类推。 示例 解 使用级别顺序遍历。在遍历期间,将第一个元
-
如何查找节点是否存在于二叉树中(按索引,而不是按值)?
给定一个完整的二叉树,其中节点的索引从1到N(索引1是根,N是树中的节点数)。在O(logN)时间复杂度下,我们能发现树中是否存在具有特定索引的节点吗? 下面我写了在O(N)中运行的代码 当节点位于右子树深处时,O(N)解似乎效率很低。我们可以避免在根级别访问左子树吗? 利用O(logN)时间复杂度是一个完整的二叉树这一事实,有可能实现这一目标吗?
-
有哪些算法可以增量构建没有顺序约束的平衡二叉树?
我感兴趣的是获取一个元素列表,并将它们转换成一个平衡的二叉树,每个元素位于树的一片叶子上。此外,我想用一种一次只能看到一个元素的算法来构建树,而不是一次看到整个列表。最后,这个树没有排序约束——也就是说,它不是一个搜索树,所以节点可以按任何顺序排列。 我的问题是:有很多算法可以增量地构建二叉搜索树,但有哪些算法可以在没有任何排序约束的情况下构建平衡的二叉树?它们应该更有效,因为它们不必担心保持节点
-
通过二叉树的数组表示的最小堆;Move多谢函数无限循环
我正在使用一个数组数据结构实现一个最小堆,但是我的moveDown方法有一个问题(在根节点使用,如果根节点的子节点比它小,就将集合返回到一个堆)。我假设读者知道什么是min heap,但是我将描述它以防有人不知道或者我的理解不正确。 最小堆(在这种情况下)是由数组表示的二叉树,这样: 根节点是数据结构中的最小值 节点必须始终小于其子节点 给定一个数组索引I的节点,它的左子节点位于索引I*21,右子
-
使用不知道二叉查找树高度的顺序遍历的第k大元素
我们可以在不知道二叉查找树的高度的情况下使用顺序遍历找到第k个最大的元素吗?或者有没有一种方法可以让我们创建一个新的遍历模式,比如“右根向左”