《红黑树》专题
-
R光栅识别黑色光栅图像
下面的代码在我的图像上生成两个框。我正计划进一步分析这些框内的像素。 在下面的例子中,在红色方块的情况下,我不想继续下去,因为它的右上角有黑色像素。而我想继续在绿色方块的情况下,因为它没有一个黑色像素沿着它的边缘。
-
为spring boot制作黑名单JWT令牌
现在最大的问题是,当我尝试将用户在连接期间必须使用的令牌列入黑名单时,当它断开连接时,这个令牌不再有效,这里的代码I jwtfilter.java 现在,当我尝试使用黑名单令牌或不使用黑名单令牌进行查询时,我会出现以下错误 这是模型 这是JwtBlacklist的存储库
-
Pyplay显示黑屏("Pro Python"最佳实践")
我从“Pro Python最佳实践”一书中获取了这段代码,但无法运行游戏。运行此代码后,它会显示黑屏: 终端没有显示任何错误。它只是在黑屏上运行。我试图找到类似的问题,但在大多数情况下,问题在于代码。根据这本书,它必须起作用。如果有任何帮助,我将不胜感激!
-
 pygame窗口上奇怪的黑色矩形
pygame窗口上奇怪的黑色矩形有人知道这个黑色矩形是什么吗?这是我的主要任务。py: 这是我的马里奥。py: 最后,我的levels.py: 我使用的是Windows10计算机,python版本为3.8。3和pygame版本1.9。6.
-
pyplay窗口中的空白(黑色)屏幕
我运行以下代码: 当我运行代码时,pygame窗口打开,但它是一个空白(黑色)屏幕。我还收到以下错误消息:Traceback(最近一次呼叫last): 文件"C:/用户/Draco/OneDrive/文档/编程/graphics.py",第13行,screen.blit(img(0,0))TypeError:'pyplay.Surface'对象不可调用 我试图打开的图像保存为JPG文件。图像保存在
-
当活动继续时,SurfaceView变为黑色
我研究了其他解决方案,但它们使用的是扩展SurfaceView并实现Runnable的自定义类。我希望使用默认的SurfaceView类。有什么办法可以解决这个问题吗?
-
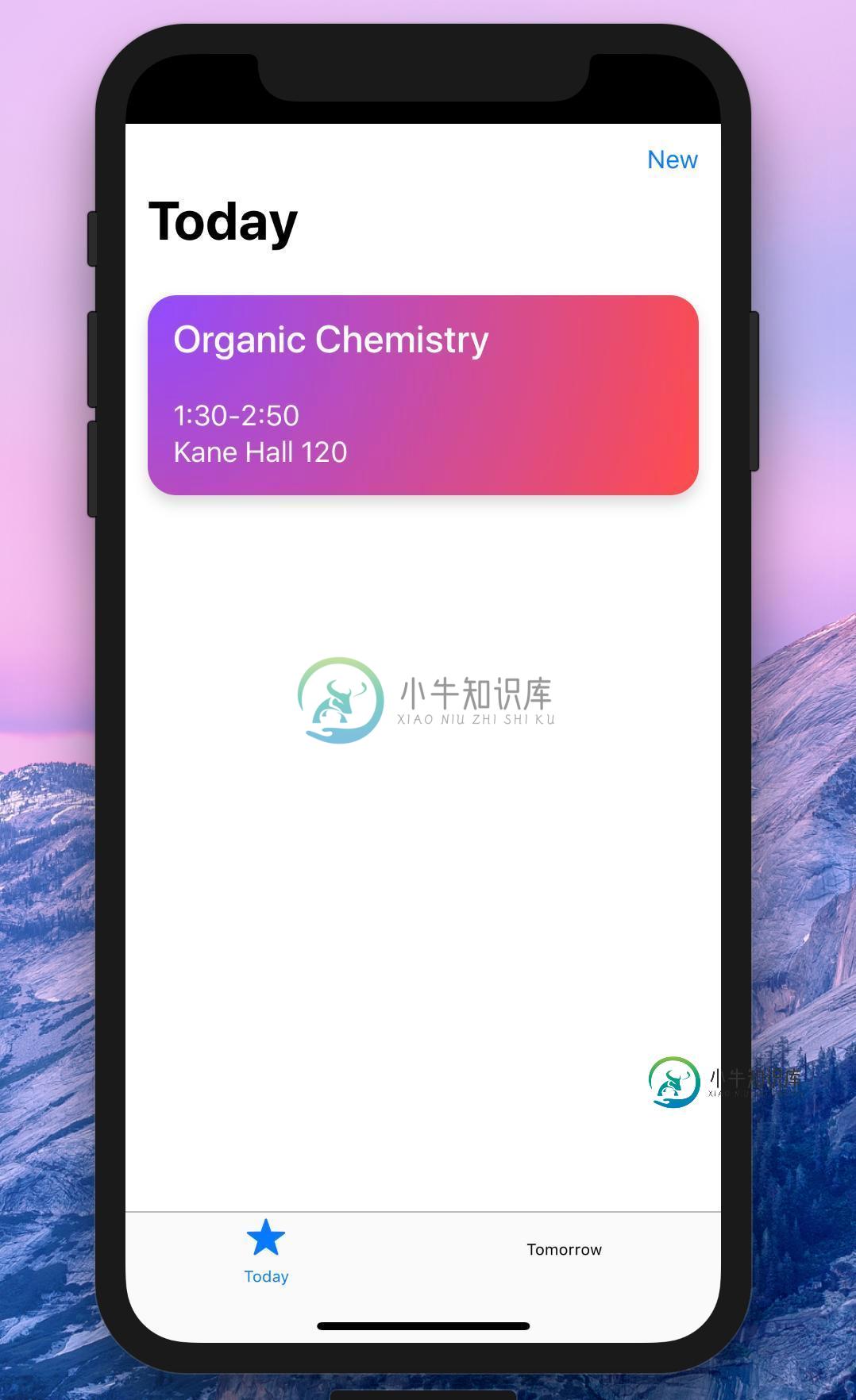 iPhone X状态栏黑色网络应用
iPhone X状态栏黑色网络应用我正在开发一个网络应用程序,在使用模拟器对苹果手机X进行测试时,状态栏完全是黑色的。我如何让我的网站覆盖整个屏幕?我没有使用任何库;我见过许多提到科尔多瓦的问题,但我有的只是带有CSS的超文本标记语言。 这是我头脑中的HTML代码。
-
https://api.twitter.com/oauth/request_token黑莓原生SDK失败
我正试图通过oAuth连接到Twitter。我正在向API发出POST请求https://api.twitter.com/oauth/request_token. 这是我的Base签名字符串示例 我用过这个工具http://quonos.nl/oauthTester/验证我的基本签名。 这里是对应的标题 我在我的MAC终端中尝试了以下命令 我得到401未经授权的错误。我试图设置oauth_call
-
 删除opencv中文本周围的黑线
删除opencv中文本周围的黑线我试图删除文本周围的黑线(如果有)。我的目的是让图像有足够的部分来提取其中的每个字符。当我试图提取字符时,额外的黑线是噪声。 我尝试过在opencv中使用泛滥填充,但图像在左上角的黑线开始之前包含一些白色像素。所以它没有结果。我尝试通过寻找轮廓来裁剪,但即使这样也不起作用。图像如下: 并利用洪水填埋场 这两种情况的结果如下 但似乎没有什么变化 不会删除任何边框。这两个代码的思想都是从对类似问题的堆
-
Spring-Cloud-侦探追踪黑森客户端
我从sping-cloud-sleuth-core中找到restTemplateInterceptor和feignRequest estInterceptor,但是我们的项目使用的是hessian连接微服务,我发现sping-cloud-sleuth无法注入到hessian客户端。有人可以分享一下如何在hessian中使用sping-cloud-sleuth的代码吗?谢谢~
-
黑暗主题在Eclipse中不起作用
我在Windows8.1上为C/C++开发人员提供了Eclipse IDE。我从市场上安装了Darkest Dark主题,但它不起作用。在重新启动时,Eclipse以我以前的主题开始,而Darkest Dark甚至不会出现在Preferences窗口中。然而,当我再次打开Marketplace并搜索它时,它显示为已安装。我找了找,但没有找到这个确切问题的答案。有人帮忙吗?
-
tesseract ANDROID中的黑名单和白名单
我正在开发一个Android应用程序,充值的手机通过手机的摄像头或从画廊的卡的照片…我使用tesseract库为此目的采取只使用黑名单和白名单的数字…它没有按预期工作 我使用的图片只包含这两行: 41722757649786 我只想识别数字,而不是字母,也不使用cropper..
-
Android:黑暗模式如何切换主题?
从Android10开始,你可以在黑暗模式和默认灯光模式之间切换。我还没有做任何更深入的研究,因为这是一个新的话题。暗模式的颜色切换是由操作系统自动的,还是有任何方法告诉我的应用程序切换不同的应用程序主题,如果暗模式是打开的?此外,黑暗模式也可能出现在一些Android 9设备上。 因为我使用自定义参数创建了自定义深色主题,并在资源中为每种颜色设置了深色(在中使用自定义属性,并在的主题中为它们应用
-
被解放的姜戈05 黑面管家
Django提供一个管理数据库的app,即django.contrib.admin。这是Django最方便的功能之一。通过该app,我们可以直接经由web页面,来管理我们的数据库。这一工具,主要是为网站管理人员使用。 这个app通常已经预装好,你可以在mysite/settings.py中的INSTALLED_APPS看到它。 “这庄园里的事情,都逃不过我的眼睛”,管家放下账本,洋洋得意。 默认界
-
Android实现QQ抢红包插件
本文向大家介绍Android实现QQ抢红包插件,包括了Android实现QQ抢红包插件的使用技巧和注意事项,需要的朋友参考一下 又想到快要过年了,到时候还不知道群里要发好多红包,所以我将之前在网上宕的一份微信抢红包的代码修改了一下,实现了QQ抢红包!可以支持抢QQ拼手气红包,普通红包,口令红包,现在再也不怕20年单身手速的人跟我抢红包了! 先看测试效果图: 1.抢QQ口令红包