《分类》专题
-
基于文本分类的Stanford CoreNLP情感分析
但是,我还没能在Stanford CorenLP中找到任何文本分类的注释器。我有什么办法可以实现我的想法。更好的是,有没有更好的方法来实现我想要实现的目标。 提前谢了。
-
Spring 工具分类-依据组织形式分类
下面是几种常见的Spring工具的类型 : – 静态工具方法类 通常以作为类名后缀 类的成员函数定义为 一般不通过创建类实例方式使用,而是通过直接被使用 一般完全无状态,(即使有状态,也一般是维护类静态成员属性static member field ) 工具方法命名通常可以"望文知意",可以知道其目的 – "某某"配置器 – "某某"增强器 – "某某"加载器 – "某某"后置处理器 – "某某"
-
Elasticsearch分析百分比
问题内容: 我正在使用Elasticsearch 1.7.3累积用于分析报告的数据。 我有一个包含文档的索引,其中每个文档都有一个名为“ duration”的数字字段(请求花费了几毫秒)和一个名为“ component”的字符串字段。可能有许多具有相同组件名称的文档。 例如。 我想生成一份报告,说明每个组件: 此组件的所有“持续时间”字段的总和。 此总和在 所有 文档的总期限中所占的百分比。在我的
-
7 分页和分段
分页: 用户程序的地址空间被划分成若干固定大小的区域,称为“页”,相应地,内存空间分成若干个物理块,页和块的大小相等。可将用户程序的任一页放在内存的任一块中,实现了离散分配。 分段: 将用户程序地址空间分成若干个大小不等的段,每段可以定义一组相对完整的逻辑信息。存储分配时,以段为单位,段与段在内存中可以不相邻接,也实现了离散分配。 分页与分段的主要区别 页是信息的物理单位,分页是为了实现非连续分配
-
html分区与分区
我正在制作一个web组件,一个导航栏(或navbar)。里面有四个部分,标志,菜单,切换器,和额外。 问题是,我应该对每个部分使用 还是 ? 还是有更合适的元素类型? 插图是这样的: 匿名用户 这是一个很棒的问题,并且与语义HTML相关。根据MDN,当没有其他标记真正相关或合适时,我们应该使用section标记。如果意图是一个实际的节,那么它还应该包括一个节头。 HTML 元素表示文档的一个通用的
-
主成分分析 PCA
目录 综述 01 使用梯度上升法求解主成分 demean 梯度上升法 02 获得前n个主成分 03 从高维数据向低维数据的映射 04 scikit-learn中的PCA 05 使用PCA降噪 手写识别例子 人脸识别 06 特征脸 特征脸 综述 “明道若昧;进道若退;夷道若颣;大方无隅;大器免成;大音希声;大象无形。” 本文采用编译器:jupyter 主成分分析 是一个非监督的机器学习算法
-
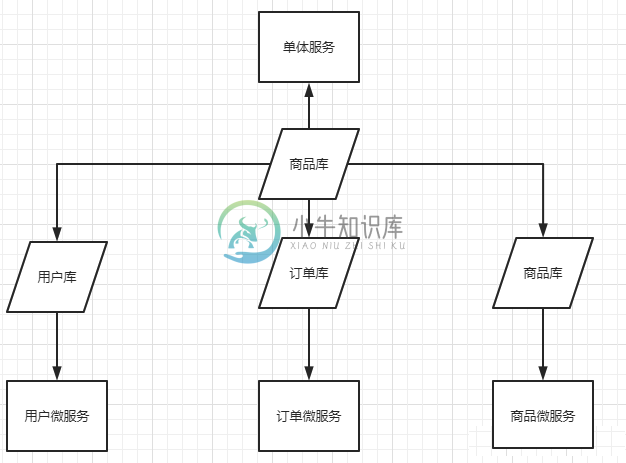 分库分表-入门
分库分表-入门主要内容:1.数据库瓶颈,2.垂直切分,3.水平切分,4.数据分片规则,5.分库分表带来的问题1.数据库瓶颈 不管是IO瓶颈,还是CPU瓶颈,最终都会导致数据库的活跃连接数增加,进而逼近甚至达到数据库可承载活跃连接数的阈值。在业务Service来看就是,可用数据库连接少甚至无连接可用。 (并发量、吞吐量、崩溃)。 1.1 IO瓶颈 第一种:磁盘读IO瓶颈,热点数据太多,数据库缓存放不下,每次查询时会产生大量的IO,降低查询速度 -> 分库和垂直分表。 第二种:网络IO瓶颈,请求的数据太多,
-
1.12 第十一部分 主成分分析
第十一部分 主成分分析(Principal components analysis) 前面我们讲了因子分析(factor analysis),其中在某个 $k$ 维度子空间对 $x \in R^n$ 进行近似建模,$k$ 远小于 $n$,即 $k \ll n$。具体来说,我们设想每个点 $x^{(i)}$ 用如下方法创建:首先在 $k$ 维度仿射空间(affine space) ${\Lambda
-
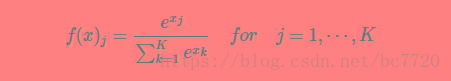 softmax原理分类?
softmax原理分类?本文向大家介绍softmax原理分类?相关面试题,主要包含被问及softmax原理分类?时的应答技巧和注意事项,需要的朋友参考一下 Softmax 函数可以导,这点很关键,当损失函数是交叉熵时,计算很方便。 Softmax 函数能够指数级扩大最后一层的输出,每个值都会增大,然而最大的那个值相比其他值扩大的更多,最终归一化。
-
DBMS故障分类
主要内容:1. 事务失败,2. 系统崩溃,3.磁盘故障要找到问题发生的位置,我们将故障(失败)归纳为以下类别: 事务失败 系统崩溃 磁盘故障 1. 事务失败 当事务无法执行或者它到达无法继续执行的点时发生事务失败。 如果一些事务或进程受到损害,那么这称为事务失败。 事务失败的原因可能是 - 逻辑错误:如果由于某些代码错误或内部错误情况导致事务无法完成,则会发生逻辑错误。 语法错误:它发生在DBMS本身终止活动事务的位置,因为数据库系统无法执行它。 例
-
Junit4 分类测试
主要内容:1 Junit分类测试的介绍,2 在Maven中进行分类测试,3 在Gradle中进行分类测试,4 在SBT中进行分类测试,5 分类测试的典型用法1 Junit分类测试的介绍 从给定的一组测试类中,类别运行器仅运行用@IncludeCategory批注指定的类别或该类别的子类型进行批注的类和方法。类或接口都可以用作类别。子类型有效,因此,如果您说@IncludeCategory(SuperClass.class),则会运行标记为@Category({SubClass.class})的测
-
分类和回归
spark.mllib提供了多种方法用于用于二分类、多分类以及回归分析。 下表介绍了每种问题类型支持的算法。 问题类型 支持的方法 二分类 线性SVMs、逻辑回归、决策树、随机森林、梯度增强树、朴素贝叶斯 多分类 逻辑回归、决策树、随机森林、朴素贝叶斯 回归 线性最小二乘、决策树、随机森林、梯度增强树、保序回归 点击链接,了解具体的算法实现。 分类和回归 线性模型 SVMs(支持向量机)
-
 商业分类学
商业分类学我为木马产品定制了分类法,产品将书籍和电子书都有自己的写手。 现在,我需要显示它,例如在产品标题下,并需要双向链接,如标签或类别。
-
Drools规则分类
谢谢
-
分类 - Python编码
这次我们不将数据直接写在Python代码中,而是放到两个文本文件里:athletesTrainingSet.txt和athletesTestSet.txt。 我会使用第一个文件中的数据来训练分类器,然后使用测试文件里的数据来进行评价。 文件格式大致如下: 文件中的每一行是一条完整的记录,字段使用制表符分隔。 我要使用运动员的身高体重数据来预测她所从事的运动项目,也就是用第三、四列的数据来预测第二列