《人工智能》专题
-
 广州电信研究院 人工智能分析师面经
广州电信研究院 人工智能分析师面经3.28 广州电信研究院 人工智能分析师1. 不长于5min的自我介绍 2.根据自我介绍提问开放性问题 3.国内AI领域的发展方向 4.给一个具体场景分析用哪些模型 输入输出是什么 5.忘了 印象:总体比较融洽 没有技术性问题 感觉这个岗位可能不用怎么写代码 看了同一批面试的同学 感觉bg都很不错 目前没收到二面 估计凉了 可能方向不太匹配 #电信研究院##电信研究院广州##人工智能#
-
人工智能 - 英伟达显卡如何调用本地RAM?
假如这么一个场景:我的笔记本有 32GB 的 RAM,然后我有一个 RTX4080 16GB 的显存 然后我现在运行一个模型需要 16GB+的显存,但是这个时候,我的显存不够会 OOM 英伟达的显卡可以向 RAM 借用存储空间吗?
-
 网易三面 | 后端开发(实习) | 人工智能部门
网易三面 | 后端开发(实习) | 人工智能部门之前分享了网易的一面二面面经,本来以为凉了,没想到在回复牛友评论的时候收到了三面的通知(https://www.nowcoder.com/discuss/487543831529857024?sourceSSR=users)。今天来分享一下三面的面经~ 谈谈JVM虚拟机 JVM虚拟机是有哪些部分组成的 JVM虚拟机的内存结构 方法区存放哪些信息 常量存放在哪个区域 一般用什么方法来创建一个线程池
-
 鉴智机器人一面
鉴智机器人一面全程70min,无手撕 全问细节和场景题 1. 在微软做哪些事情,你复杂的那一块 2. 你用了哪些数据结构和算法,完成之后效率上的提升测试过吗 3. 调用了多少异步线程,他们之间如何通信 4. 现在有一个场景 ABCD四个线程,BCD分别写入234,A读取 现在A读取的的数据不是4,你有哪些思路 BCD执行顺序问题 A读取的数据有问题 好像让了解底层原理,例如validate每次从地址当中去读取(
-
人工智能背景下的Office 365现状和发展趋势
作者:陈希章 发表于 2017年7月31日 引子 谈论人工智能是让人兴奋的,因为它具有让人兴奋的两大特征 —— 每个人都似乎知道一点并且以知道一点为荣,但又好像没多少人能真正讲的明白。毫无疑问,我也仅仅是知道一点点,这一篇文章试图想通过比较接地气的方式给一部分人讲明白。这还得说要感谢这样一个时代,换做是几年前我是绝不敢造次的 —— 那时虽然人工智能并不稀奇,但大抵都是王谢堂前的燕儿,而如今随着技术
-
人工智能 - 有无这样的audio to text接口可以用?
这段代码运行了,得到满意的输出,但是有不好的地方:google的服务,其他接口都是国外的(如ibm等). 有无这样的audio to text工具? 1.中国产 2.免费 (收费的就不要推了) 3.有python接口
-
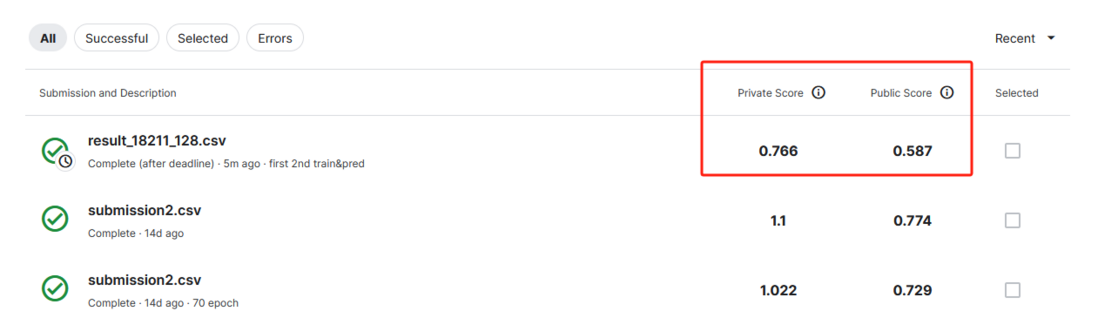 人工智能 - 如何比较Kaggle上late submission与leaderboard的分数?
人工智能 - 如何比较Kaggle上late submission与leaderboard的分数?kaggle上late submission获得的分数药怎么跟leaderboard的分数比较? 下面是leaderboard的分数,该用什么分数跟什么分数比? 搜过,没有解答
-
人工智能 - 目前的开源视觉大模型有哪些?
目前的开源视觉大模型有哪些? 我知道的只有智谱的 CogVLM,还有其他的吗? https://github.com/THUDM/CogVLM
-
 上海人工智能实验室大模型算法实习面经
上海人工智能实验室大模型算法实习面经问的很细很深,狠狠拷打了80分钟,这个组做LLM pretrain的,我主要会rl,nlp缺乏点,一面凉 自我介绍 项目 微调模型训练数据来源? LORA的理解 Ptuning和全量微调对比 RLHF全流程 写出RLHF的优化目标公式 目标公式中衰减因子的作用,取大取小有什么影响? RLHF的目标公式可以加入什么其他的项? 熵正则项是如何加入的? KL散度理解? RLHF中PPO算比率相对什么来算
-
 23智元机器人二面
23智元机器人二面确实,不太契合,非科班鼠鼠的计网,操作系统基本功太差了,题也没撕。 1. 为何转行 2. 拷打项目 3. 知道哪些网络攻击(csrf,xss) 4. csrf如何防御 5. xss如何开展(嵌入脚本,咋嵌入的?忘了) 6. 你在宿舍ping百度的ip的过程中发生了什么(我真不会) 7. linux如何查看进程监听的tcp端口 8. 如何查看进程PID 9. kill -9 中-9的作用和目的是什么
-
 23智元机器人前端
23智元机器人前端智元机器人不方便透露的部门前端岗 1. 项目 2. 难点 3. js基本数据类型 4. 对基本数据类型string访问length时发生了什么 5. 事件循环 6. 浏览器实现异步的几种写法 7. react的setState是同步还是异步的 8. 函数组件的基本的hook介绍下 9. redux更新状态的过程 10. 虚拟dom优势,劣势(简单的修改需要很多对比) 11. 算法: 1. 小青蛙上
-
 上海人工智能实验室后端开发实习面经(已oc)
上海人工智能实验室后端开发实习面经(已oc)一面 计算机基础你都学过了是吧,那我就不问了() 谈一谈你对hashmap的理解。 hashmap线程不安全的场景,如何去解决。 concurrenthashmap在1.6之后做了哪些改进。 hashmap在链表长度为8,数组长度为64时链表转红黑树,为什么设定这两个默认值。 synchronized 和 Lock的区别。 谈一谈在高并发的情况下,会遇到哪些问题,怎么去解决。 如果从线程池的角度去
-
 长安汽车(乘用车-人工智能算法开发)一面凉经
长安汽车(乘用车-人工智能算法开发)一面凉经本来以为一面应该是技术面,结果面着面着就像是综合面 时长:20min 1.自我介绍 2.询问项目(简单问了一下,问了一下自己的贡献) 由于我简历里面写了自己有发明专利,面试官还问了我发明专利的事情。 3.问我在科研上遇到挫折的时候有没有和业内的大牛交流过(啊这,遇到问题都是自己上网百度或者是查文献,都是自己解决的。自己也没有那些大牛的联系方式,咋会和那些大牛交流呢) 4.由于我有一个目标跟踪方向的
-
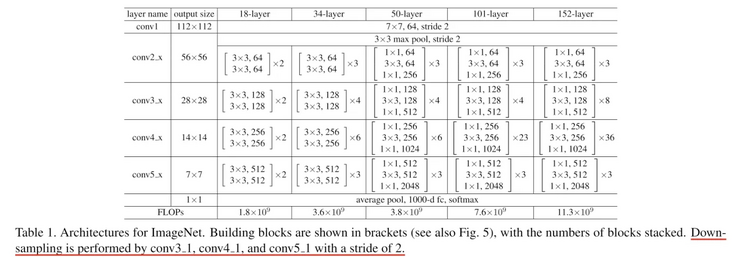 人工智能 - 如何获取 ResNet-50 模型的前 48 层的输出?
人工智能 - 如何获取 ResNet-50 模型的前 48 层的输出?我想看看 resnet50 模型,第 48 层的输出,我写了下面的代码,但是运行报错了 报错如下: 我明明把后面的 fc 给丢掉了呀,为什么还报错呢? 我该如何修改?
-
人工智能 - Kmeans如何应用于类别不平衡的数据上(用kmeans做工具)?
Kmeans如何应用于减轻类别不平衡的数据上,然后用来训练其他模型? 用kmeans做工具,不是用不平衡数据区训练kmeans! 举例: 训练数据中A,B,C,D,其中A B类别很多 CD很少; 预测数据中全部是A,C。 此时用kmeans直接把ABCD 聚类成2个? 查看过一些博客,基本上都是水文,没多少有用价值。。。